3天掌握Spark-- Spark on YARN
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3天掌握Spark-- Spark on YARN相关的知识,希望对你有一定的参考价值。
Spark on YARN
属性配置和服务启动
将Spark Application提交运行到YARN集群上,至关重要,企业中大多数都是运行在YANR上
文档:http://spark.apache.org/docs/2.4.5/running-on-yarn.html
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性
在实际项目中,只需要配置:6.1.1 至 6.1.4即可,由于在虚拟机上测试,所以配置6.1.5解除资源检查限制。
提交应用
先将圆周率PI程序提交运行在YARN上,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master yarn \\
--class org.apache.spark.examples.SparkPi \\
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
运行完成在YARN 监控页面截图如下
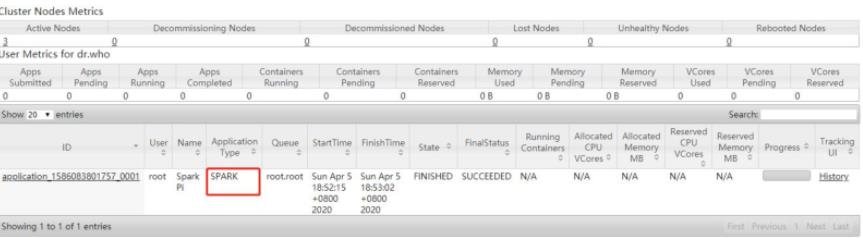
设置资源信息,提交运行WordCount程序至YARN上,命令如下
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master yarn \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--num-executors 2 \\
--queue default \\
--class cn.itcast.spark.submit.SparkSubmit \\
hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \\
/datas/wordcount.data /datas/swcy-output
当WordCount应用运行YARN上完成以后,从8080 WEB UI页面点击应用历史服务连接,查看应用运行状态信息。
DeployMode两种模式区别
Spark Application提交运行时部署模式Deploy Mode,表示的是Driver Program运行的地方,要么是提交应用的Client:client,要么是集群中从节点(Standalone:Worker,YARN:NodeManager):cluster。

- client 模式
默认DeployMode为
Client,表示应用Driver Program运行在提交应用Client主机上(启动JVM Process进程),示意图如下:
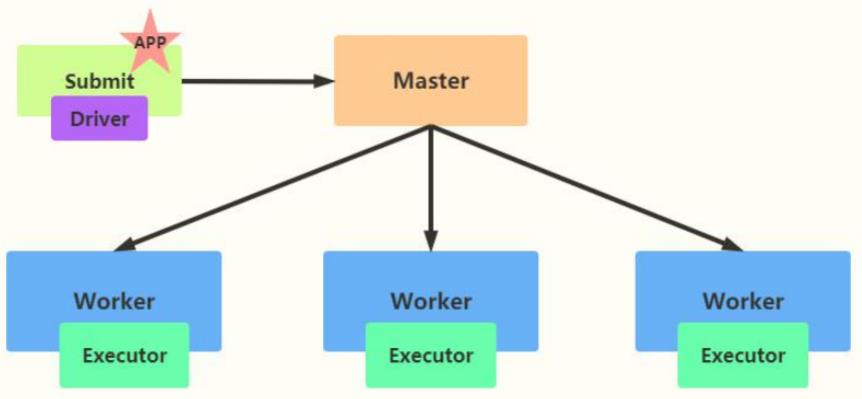
假设运行圆周率PI程序,采用client模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \\
--deploy-mode client \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--total-executor-cores 2 \\
--class org.apache.spark.examples.SparkPi \\
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
- cluster 模式
如果采用cluster模式运行应用,应用Driver Program运行在集群从节点Worker某台机器上。
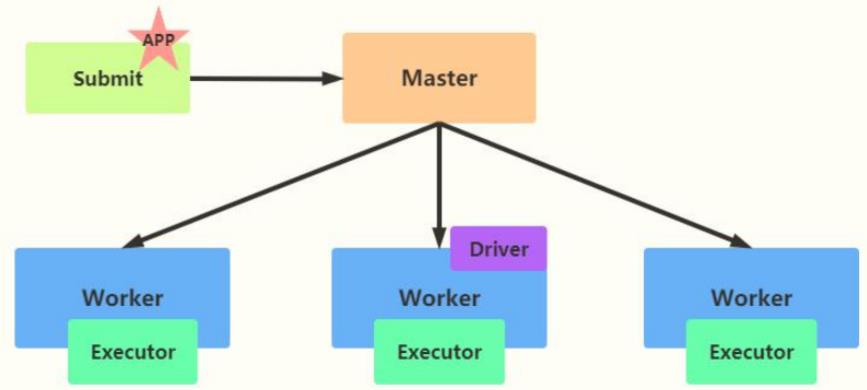
假设运行圆周率PI程序,采用cluster模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \\
--deploy-mode cluster \\
--supervise \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--total-executor-cores 2 \\
--class org.apache.spark.examples.SparkPi \\
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
YARN Client 模式
当应用运行YARN上时,有2部分组成:
- AppMaster,应用管理者,申请资源和调度Job执行
- Process,运行在NodeManager上进程,运行Task任务
Spark 应用运行集群上时,也有2部分组成:
- Driver Program,应用管理者,申请资源运行Executors和调度Job执行
- Executors,运行JVM进程,其中执行Task任务和缓存数据
- YARN
Client模式
当Spark 运行在YARN集群时,采用client DeployMode时,有如下三个进程:
AppMaster,申请资源,运行ExecutorsDriver Program,调度Job执行和监控Executors,运行JVM进程,其中执行Task任务和缓存数据
- YARN
Cluster模式
当Spark 运行在YARN集群时,采用clusterDeployMode时,有如下2个进程:
Driver Program(AppMaster),既进行资源申请,又进行Job调度Executors,运行JVM进程,其中执行Task任务和缓存数据
所以Spark Application运行在YARN上时,采用不同DeployMode时架构不一样,企业实际生产环境还是以cluster模式为主,client模式用于开发测试,两者的区别面试中常问。
在YARN Client模式下,Driver在任务提交的本地机器上运行,示意图如下:
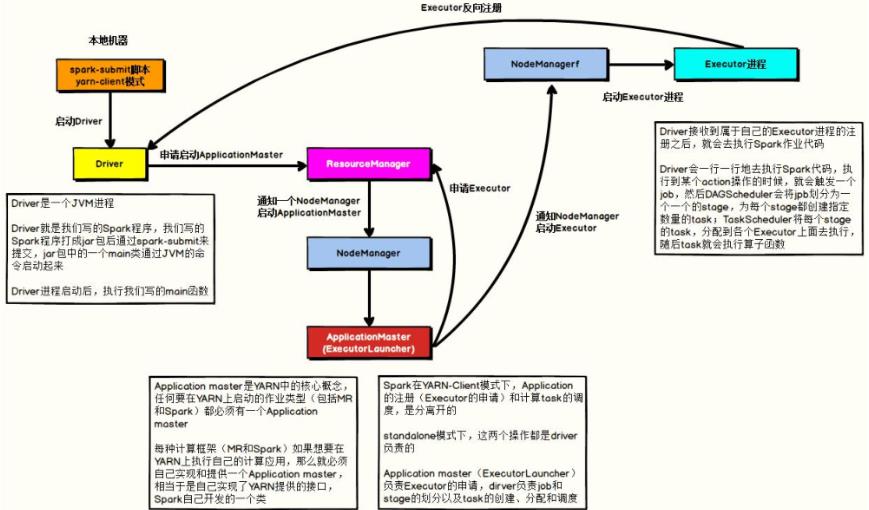
采用yarn-client方式运行词频统计WordCount程序
/export/server/spark/bin/spark-submit \\
--master yarn \\
--deploy-mode client \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--num-executors 2 \\
--queue default \\
--class cn.itcast.spark.submit.SparkSubmit \\
hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \\
/datas/wordcount.data /datas/swcy-client
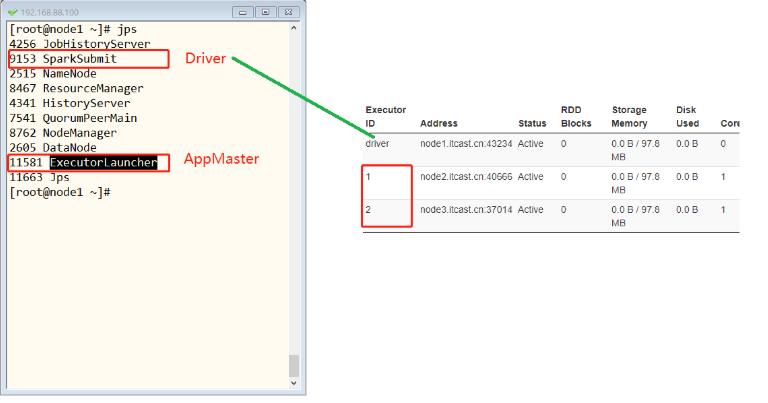
YARN Cluster模式
以运行词频统计WordCount程序为例,提交命令如下:
/export/server/spark/bin/spark-submit \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--num-executors 2 \\
--queue default \\
--class cn.itcast.spark.submit.SparkSubmit \\
hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \\
/datas/wordcount.data /datas/swcy-cluster
MAIN函数
Spark Application应用程序运行时,无论client还是cluster部署模式DeployMode,当DriverProgram和Executors启动完成以后,就要开始执行应用程序中MAIN函数的代码,以词频统计WordCount程序为例剖析讲解。

上述图片中,A、B都是在Executor中执行,原因在于对RDD数据操作的,针对C来说,如果没有返回值时,在Executor中执行,有返回值,比如调用count、first等函数时,在Driver中执行的。

点个赞嘛!

以上是关于3天掌握Spark-- Spark on YARN的主要内容,如果未能解决你的问题,请参考以下文章