使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
Posted wbh1000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词相关的知识,希望对你有一定的参考价值。
1 package sogolog 2 3 import org.apache.hadoop.io.{LongWritable, Text} 4 import org.apache.hadoop.mapred.TextInputFormat 5 import org.apache.spark.rdd.RDD 6 import org.apache.spark.{SparkConf, SparkContext} 7 8 9 10 class RddFile { 11 def readFileToRdd(path: String): RDD[String] = { 12 val conf = new SparkConf().setMaster("local").setAppName("sougoDemo") 13 val sc = new SparkContext(conf); 14 //使用这种方法能够避免中文乱码 15 sc.hadoopFile("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced",classOf[TextInputFormat], classOf[LongWritable], classOf[Text]).map{ 16 pair => new String(pair._2.getBytes, 0, pair._2.getLength, "GBK")} 17 } 18 }
1 package sogolog 2 3 import org.apache.spark.rdd.RDD 4 5 /** 6 * 列出搜索不同关键词超过3个的用户及其搜索的关键词 7 */ 8 object userSearchKeyWordLT3 { 9 def main(args: Array[String]): Unit = { 10 //1、读入文件 11 val textFile = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced") 12 13 //2、map操作,将每行的用户、关键词读入新的RDD中 14 val userKeyWordTuple:RDD[(String,String)] = textFile.map(line=>{ 15 val arr = line.split(" ") 16 (arr(1),arr(2)) 17 }) 18 19 //3、reduce操作,将相同用户的关键词进行合并 20 val userKeyWordReduced = userKeyWordTuple.reduceByKey((x,y)=>{ 21 //去重 22 if(x.contains(y)){ 23 x 24 }else{ 25 x+","+y 26 } 27 }) 28 29 //4、使用filter进行最终过滤 30 val finalResult = userKeyWordReduced.filter(x=>{ 31 //过滤小于10个关键词的用户 32 x._2.split(",").length>=10 33 }) 34 35 //5、打印出结果 36 finalResult.collect().foreach(println) 37 } 38 }
运行结果:
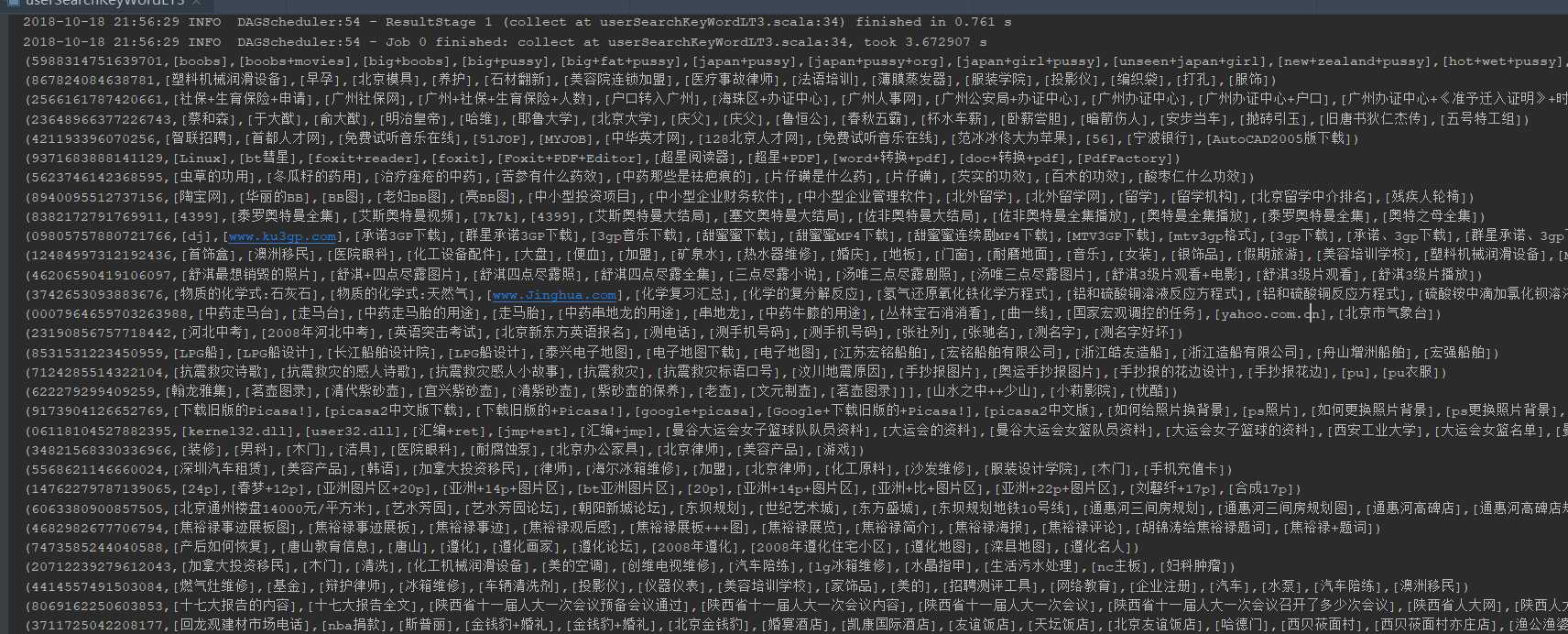
以上是关于使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词的主要内容,如果未能解决你的问题,请参考以下文章