3天掌握Spark-- IDEA 应用开发Spark
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3天掌握Spark-- IDEA 应用开发Spark相关的知识,希望对你有一定的参考价值。
IDEA 应用开发Spark
构建Maven Project
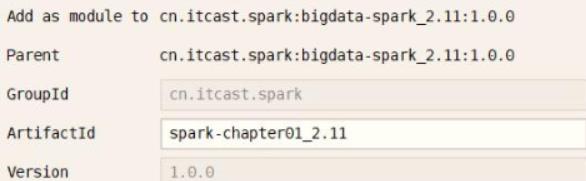
创建Maven Project工程【bigdata-spark_2.11】,设置GAV三要素的值如下:

创建Maven Module模块【spark-chapter01_2.11】,对应的GAV三要素值如下:
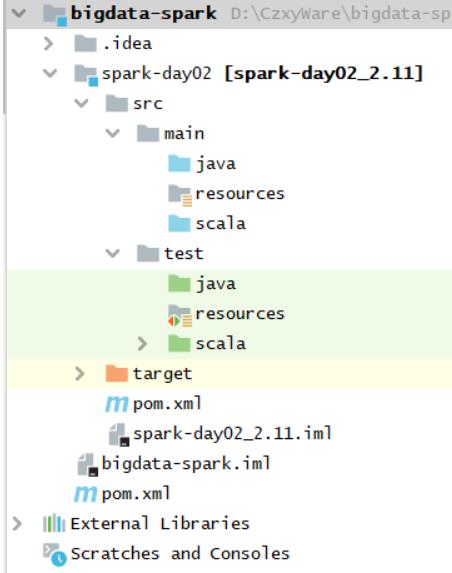
至此,将Maven Module模块创建完成,可以开始编写第一个Spark程序。
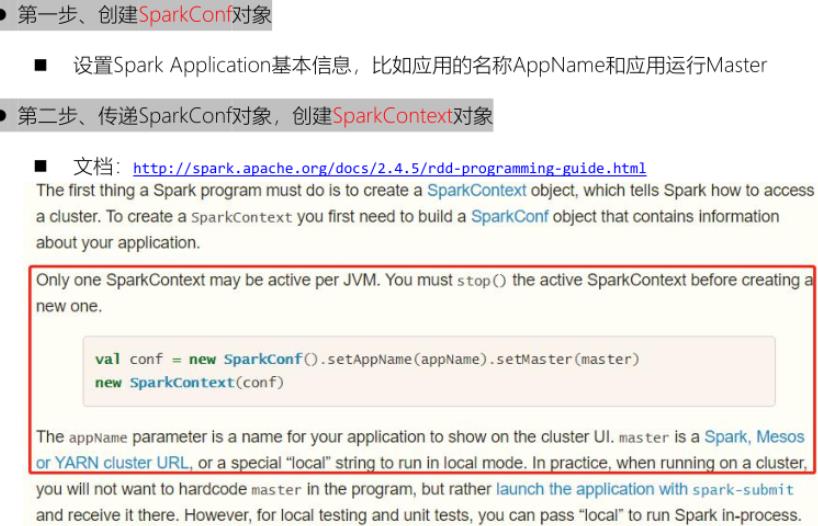
应用入口SparkContext
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
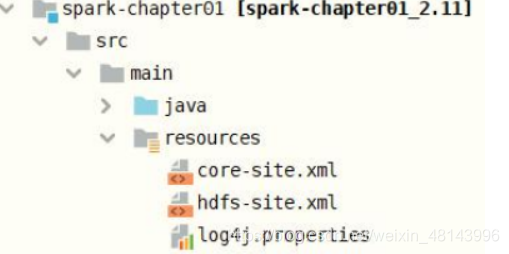
编程实现:WordCount
从HDFS上读取数据,所以需要将HDFS Client配置文件放入到Maven Module资源目录下,同时设置应用运行时日志信息。
object SparkWordCount {
def main(args: Array[String]): Unit = {
// TODO: 创建SparkContext实例对象,首先构建SparkConf实例,设置应用基本信息
val sc: SparkContext = {
// 其一、构建SparkConf对象,设置应用名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName("SparkWordCount")
.setMaster("local[2]")
// 其二、创建SparkContext实例,传递sparkConf对象
new SparkContext(sparkConf)
}
// TODO: 第一步、从HDFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("/datas/wordcount.data")
// TODO: 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
/*
mapreduce spark spark hive
| flatMap() = map + flatten
mapreduce
spark
spark
hive
|map
mapreduce,1
spark,1
spark,1
hive,1
| reduceByKey
spark, 2
mapreduce, 1
hive, 1
*/
val resultRDD: RDD[(String, Int)] = inputRDD
// 按照分隔符分割单词
.flatMap(line => line.split("\\\\s+"))
// 转换单词为二元组,表示每个单词出现一次
.map(word => word -> 1)
// 按照单词分组,对组内执进行聚合reduce操作,求和
.reduceByKey((tmp, item) => tmp + item)
// TODO: 第三步、将最终处理结果RDD保存到HDFS或打印控制台
resultRDD.saveAsTextFile("/datas/spark-wordcount")
resultRDD.foreach(tuple => println(tuple))
// 为了查看应用监控,可以让进程休眠
Thread.sleep(100000)
// 应用结束,关闭资源
sc.stop()
}
}
编程实现:TopKey
在上述词频统计WordCount代码基础上,
对统计出的每个单词的词频Count,按照降序排序,获取词频次数最多Top3单词。
数据结构RDD中关于排序函数有如下三个:
- 1)、sortByKey:针对RDD中数据类型key/value对时,按照Key进行排序

2)、sortBy:针对RDD中数据指定排序规则

3)、top:按照RDD中数据采用降序方式排序,如果是Key/Value对,按照Key降序排序

建议使用sortByKey函数进行数据排序操作,慎用top函数。
/**
* 使用Spark实现词频统计WordCount程序,按照词频降序排序
*/
object SparkTopKey {
def main(args: Array[String]): Unit = {
// TODO: 创建SparkContext实例对象,首先构建SparkConf实例,设置应用基本信息
val sc: SparkContext = {
// 其一、构建SparkConf对象,设置应用名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName("SparkWordCount")
.setMaster("local[2]")
// 其二、创建SparkContext实例,传递sparkConf对象
new SparkContext(sparkConf)
}
// TODO: 第一步、从HDFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("/datas/wordcount.data")
// TODO: 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
/*
mapreduce spark spark hive
| flatMap() = map + flatten
mapreduce
spark
spark
hive
|map
mapreduce,1
spark,1
spark,1
hive,1
| reduceByKey
spark, 2
mapreduce, 1
hive, 1
*/
val resultRDD: RDD[(String, Int)] = inputRDD
// 按照分隔符分割单词
.flatMap(line => line.split("\\\\s+"))
// 转换单词为二元组,表示每个单词出现一次
.map(word => word -> 1)
// 按照单词分组,对组内执进行聚合reduce操作,求和
.reduceByKey((tmp, item) => tmp + item)
// TODO: 第三步、将最终处理结果RDD保存到HDFS或打印控制台
/*
(spark,11)
(hadoop,3)
(hive,6)
(hdfs,2)
(mapreduce,4)
(sql,2)
*/
resultRDD.foreach(tuple => println(tuple))
println("===========================")
// =========================== sortByKey =========================
resultRDD
// 将单词和词频互换
.map(tuple => tuple.swap) // (tuple => (tuple._2, tuple._1))
// 调用sortByKey安装,按照Key进行排序,设置降序排序
.sortByKey(ascending = false)
// 打印结果
.take(3)
.foreach(tuple => println(tuple))
println("===========================")
// =========================== sortBy =========================
/*
def sortBy[K](
f: (T) => K, // 指定排序规则
ascending: Boolean = true,
numPartitions: Int = this.partitions.length
)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
*/
resultRDD
.sortBy(tuple => tuple._2, ascending = false)
// 打印结果
.take(3)
.foreach(tuple => println(tuple))
println("===========================")
// =========================== top =========================
/*
def top(num: Int)(implicit ord: Ordering[T]): Array[T]
*/
resultRDD
.top(3)(Ordering.by(tuple => - tuple._2))
.foreach(tuple => println(tuple))
// 为了查看应用监控,可以让进程休眠
Thread.sleep(100000)
// 应用结束,关闭资源
sc.stop()
}
}
Spark 应用提交命令【spark-submit】
使用IDEA集成开发工具开发测试Spark Application程序以后,类似MapReduce程序一样,打成jar包,使用命令【spark-submit】提交应用的执行
[root@node1 ~]# /export/server/spark/bin/spark-submit --help
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
提交一个应用命令:
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
第一种:基本参数配置

第二种:Driver Program 参数配置

第三种:Executor 参数配置
每个Spark Application运行时,需要启动Executor运行任务Task,需要指定Executor个数及每个Executor资源信息(内存Memory和CPU Core核数)。

应用打包运行
将开发测试完成的WordCount程序打成jar保存,使用【spark-submit】分别提交运行在本地模式LocalMode和集群模式Standalone集群。
[先修改代码,通过master设置运行模式及传递处理数据路径](
/**
* 使用Spark实现词频统计WordCount程序
*/
object SparkSubmit {
def main(args: Array[String]): Unit = {
//判断是否传递2个参数,如果不是,直接抛出异常
if(args.length < 2){
println("Usage: SparkSubmit <input> <output> ...................")
System.exit(-1)
}
// TODO: 创建SparkContext实例对象,首先构建SparkConf实例,设置应用基本信息
val sc: SparkContext = {
// 其一、构建SparkConf对象,设置应用名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName("SparkWordCount")
//.setMaster("local[2]")
// 其二、创建SparkContext实例,传递sparkConf对象
new SparkContext(sparkConf)
}
// TODO: 第一步、从HDFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile(args(0))
// TODO: 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
/*
mapreduce spark spark hive
| flatMap() = map + flatten
mapreduce
spark
spark
hive
|map
mapreduce,1
spark,1
spark,1
hive,1
| reduceByKey
spark, 2
mapreduce, 1
hive, 1
*/
val resultRDD: RDD[(String, Int)] = inputRDD
// 按照分隔符分割单词
.flatMap(line => line.split("\\\\s+"))
// 转换单词为二元组,表示每个单词出现一次
.map(word => word -> 1)
// 按照单词分组,对组内执进行聚合reduce操作,求和
.reduceByKey((tmp, item) => tmp + item)
// TODO: 第三步、将最终处理结果RDD保存到HDFS或打印控制台
resultRDD.saveAsTextFile(s"${args(1)}-${System.currentTimeMillis()}")
// 应用结束,关闭资源
sc.stop()
}
}
打成jar包,上传至HDFS文件系统:/spark/apps
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master local[2] \\
--class cn.itcast.spark.submit.SparkSubmit \\
hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \\
/datas/wordcount.data /datas/swc-output
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \\
--class cn.itcast.spark.submit.SparkSubmit \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--total-executor-cores 2 \\
hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \\
/datas/wordcount.data /datas/swc-output
点个赞嘛!

以上是关于3天掌握Spark-- IDEA 应用开发Spark的主要内容,如果未能解决你的问题,请参考以下文章