如何迈向高效深度神经网络模型架构?
Posted AI TIME 论道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何迈向高效深度神经网络模型架构?相关的知识,希望对你有一定的参考价值。
点击蓝字
AI TIME欢迎每一位AI爱好者的加入!
最近几年,随着公共领域中的数据规模和计算机的运算能力的大幅提升,神经网络模型在视觉,自然语言处理等领域取得了飞速的发展,各种任务的性能指标被不断刷新。人们为了追求更高的性能,提升模型的学习能力,设计了很多新的、越来越大的模型架构。这些越来越大的模型虽然带来了优越的性能,但也对实际应用带来了不小的挑战。为了解决这些挑战,促进神经网络在实际应用中的推广,越来越多的研究者开始研究压缩神经网络模型,提升模型运行与训练速度的方法。
3月27日,PhD Debate第一期“如何迈向高效深度神经网络模型架构”,AI TIME特别邀请了MIT的林己、德州大学奥斯汀分校陈天龙、东北大学的李垠桥,并由杜克大学的杨幻睿和清华大学的张亚娴主持,共话迈向高效深度神经网络研究。
神经网络结构搜索(NAS)
现有神经网络结构搜索方法是否成本过高?
在学校环境下研究NAS会有哪些难点。你是如何克服的?
林己首先表示,由于NAS是通过计算力提升模型效果的方法,计算代价确实比较高,特别是google最早提出的基于增强学习的方法,需要采样非常多的随机网络进行训练。但是最近同样出现了很多优化NAS速度的进展,比如基于可微分的NAS,以及基于weight sharing的one-shot的NAS方法(ECCV 2020, Single Path One-Shot Neural Architecture Search with Uniform Sampling),都可以极大地降低NAS的cost,所以能在实验室环境下开展实验。另外在学校环境下,NAS还有很多理论分析方向可以研究,比如,NAS用超网估计的子网络的性能和子网络最终训练性能不匹配,这种研究可以在一些小规模数据集(比如NAS-Bench-101,NAS-Bench-201)上进行,所以能进一步的缩小NAS的计算资源。以及在应用层面,也有针对在IoT设备上部署的小型网络进行搜索的相关研(NeurIPS 2020, MCUNet: Tiny Deep Learning on IoT Devices),进一步降低神经网络搜索的限制。
李垠桥同样表示结构搜索任务比较重。为了找到一个适用于当前任务的模型结构,NAS模型的搜索空间需要定义的相对较大,这样才能让搜索出的结构更好的跳出传统的人工设计的框架,找到更有突破性的结构。因此大部分最受关注的网络结构搜索的研究主要来自于大公司的团队。但是学校这种低资源的情况同样可以开展NAS的研究,可以通过两个方式来降低NAS对算力的要求,一个是使用更加轻量级的任务验证自己的方法,经统计,17年到现在的顶会NAS论文,其中将近60%的工作是在图像分类任务上做的,而其他任务也主要集中于在一些相对轻量级的任务中,如NLP的语言建模,命名实体识别等等。像机器翻译这种比较重的任务,在NAS中出现的非常少,大约占比不到1%左右。另一个就是选择更加高效的搜索策略,例如基于梯度的结构搜索方法,该方法并不需要很大的算力支持就可以在对应任务中找到适合的模型结构。
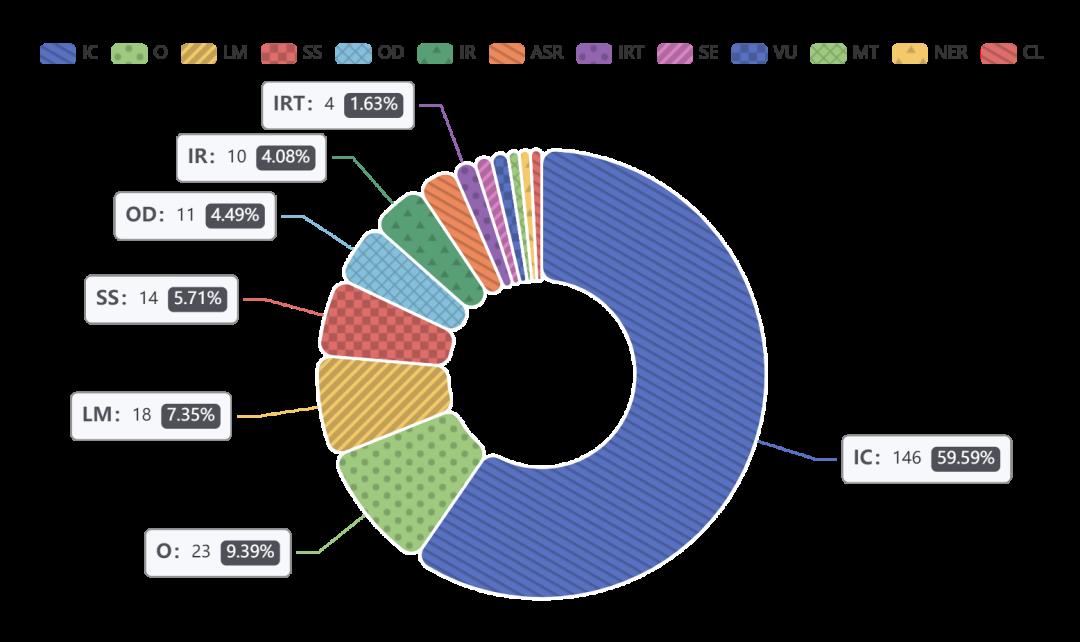
图1:2017年-2021年初结构搜索领域论文中各项任务的占比
(来源:https://github.com/NiuTrans/NASPapers)
陈天龙表示,从理论出发进行探究是一个很好的选择。例如可以考虑training-free的方法,利用random weight估计子网络的最终表现,从而大大的提升模型搜素的效率,从这个方法也延伸出很多理论方向的工作,例如NTK-base(Neural Architecture Search on ImageNet in Four GPU Hours: A Theoretically Inspired Perspective)的角度探究进一步的解决神经网络搜索的时间。
杨幻睿表示NAS现在很多是从超网到子网络sample的方法。有些方法训练超网的时间比较长,但是sample后训练时间比较短。可以考虑结合最新的理论工作,同时降低超网训练和子网络训练的时间,进一步加快模型搜索。
Transformer的机遇和挑战
1.目前针对Transformer的压缩有哪些常见方法?
2.与视觉领域CNN压缩相比的主要区别是什么?
李垠桥表示Transformer模型在自然语言处理的各项任务中大放异彩。凭借着Transformer模型在性能、可解释性、并行性等方面的优势,Transformer模型在自然语言处理任务之外的其他领域如CV也开始逐渐展露锋芒。而对于如何对Transformer这类模型进行压缩来说,从相对工程的角度出发,可以采用知识蒸馏,低精度运算等方法对模型进行压缩以及加速。虽然这类方法并不限于在Transformer模型中进行使用,但是在特定模型中这些方法的使用也需要研究人员进行一些尝试。例如,在模型结构中哪些位置可以使用低精度进行运算,而哪些位置为了保证模型性能而不能采用这类方法,甚至在不同位置需要保留多少的参数精度等等,这些都需要研究人员针对具体任务不断去调整。
另外对于模型压缩来说也可以针对Transformer模型本身的特定结构研究特定的压缩方法。之前也有研究人员从模型行为的角度出发针对Transformer进行压缩,在保证性能的前提下压缩模型大小。比如对于attention结构出发,ANN (Accelerating Neural Transformer via an Average Attention Network)提出了平均注意力的方法减轻模型在attention计算时的复杂度。另外李垠桥也从另一个角度提出了SAN (Sharing Attention Weights for Fast Transformer)的方法,通过利用不同层之间注意力权重的相似性在不同层之间对attention权重进行复用,从而达到加速的目的。这些方法都是从Transformer特定的结构出发的,可以和上述的工程方法结合。
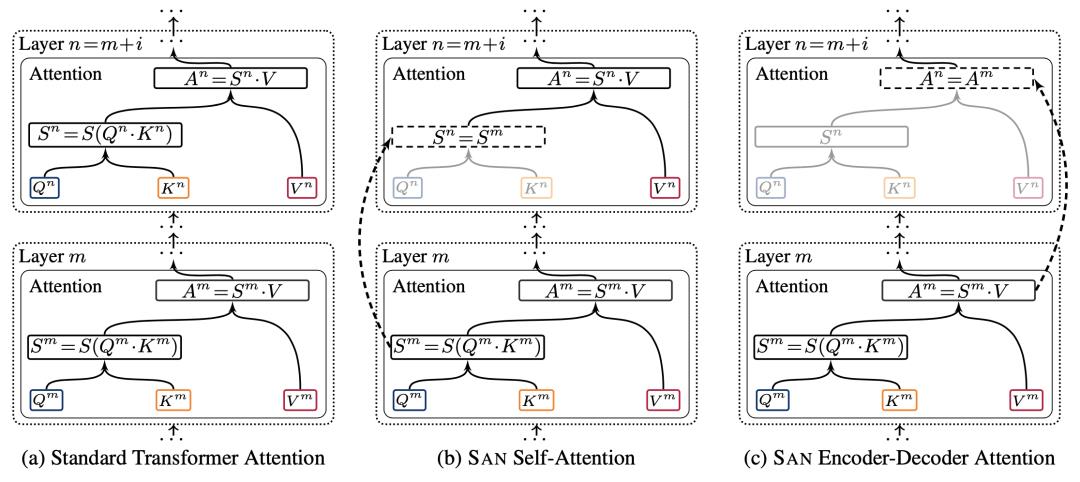
图2:基于attention权重共享的Transformer模型加速压缩方法
(来源:Sharing Attention Weights for Fast Transformer,https://www.ijcai.org/Proceedings/2019/0735.pdf)
杨幻睿表示Transformer的压缩相较于CNN而言可能更加精细,CNN的结构相对简单,全部由相似的卷积层构成;而transformer每个模块中存在作用不同的投影操作,也存在注意力机制等独特的模块。因此针对Transformer的压缩可能也需要更多的尝试和探索。其中典型包括early access (BERT Loses Patience: Fast and Robust Inference with Early Exit)和weight sharing (ALBERT: A Lite BERT for Self-supervised Learning of Language Representations)等方法,由于transformer结构在每一层的尺寸完全一样,可以考虑提前若干层输出结果,或者中间几层保持相同权重,这些方法在NLP领域已经有一些研究,可能在视觉方面的Vision transformer模型上还有很大发展。另外,在BERT在pretrain和finetune阶段应该存在不同的压缩方式,上述提及的ANN和SAN主要是针对下游特定任务进行的压缩,针对预训练阶段的压缩目前也很值得研究。
陈天龙从lottery ticket hypothesis角度出发,研究BERT压缩中lottery ticket的存在性,即为BERT中是否有小模型,可以继承pre-training好的迁移性。通过彩票假说,陈天龙证明了BERT压缩至只有~30%的参数,同样也有不受损的表达能力和迁移能力。
自监督与无监督模学习
1.目前针对自监督模型或GAN的压缩有什么值得关注的工作?
2.在方法与优化目标上会有哪些与监督学习模型压缩的差异?
林己表示GAN本身压缩比较复杂。主要原因如下:
1. GAN中包含两个神经网络,生成器和判别器(generator和discriminator),尽管我们最终只需要生成器,但是由于训练中涉及到生成器和判别器的优化,会让压缩过程变得更加复杂。例如我们在压缩生成器时,是否需要对判别器同时压缩?若同时压缩,如何权衡压缩比率使其训练过程尽量平衡?
2. GAN本身训练不稳定,相较于监督学习,GAN的训练难度更大。
3. GAN本身在压缩时,缺少性能量化标准,现在的指标很难量化生成器的整体性能,且这些指标如FID本身计算代价就比较昂贵。
陈天龙表示,GAN压缩过程的关键在于如何平衡两者。另外一个关键点在于判别器和生成器初始权重的选择,不同权重的选择会有不同的影响(ICLR 2021, GANs Can Play Lottery Tickets Too)。评价指标并不可靠同样加大了GAN压缩的难度,不能了解训练过程模型训练的程度。另外对自监督网络,陈天龙研究自监督模型性能受损情况,通过彩票假说保证泛化迁移能力不受损(CVPR 2021, The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models)。自监督与无监督模学习对比监督学习模型,压缩方法方面差异不大,主要还是继承以前的方法做微小改动。
针对如何在GAN剪枝时平衡判别器和生成器的比重,即是同时对生成器和判别器进行剪枝,还是使用一个较强的判别器仅对生成器进行剪枝?
林己表示通常不需要在对生成器剪枝时同时也对判别器剪枝,一个更强的判别器能更好的训练生成器,相对而言过分剪枝的判别器很难给生成器一个正确的反馈。实验中,判别器的权重可能需要从训练好的模型中恢复,而不是从头开始训练,这样会有效的提升performance(CVPR 2020, GAN Compression: Efficient Architectures for Interactive Conditional GANs)。另外,林己提及在NAS任务上,我们发现针对不同生成的子网络,可能需要不同的判别器才可以更好的判断每种结构的优劣(CVPR 2021, Anycost GANs for Interactive Image Synthesis and Editing)。
陈天龙从压缩比率和模型权重恢复两方面回答这个问题。在压缩比率方面,压缩判别器给训练带来的收益相对较少。而生成模型和判别器的初始化权重可能更加重要。此外,如果采用不同epoch恢复生成器和判别器,过强的判别器可能会over-confidence,使得训练无法进展。因此,在GAN模型压缩时,如果生成器从头开始训练,那么判别器最好也要从头训练。
针对问题:自监督学习模型在压缩时下游任务迁移的能力可能会受损,那么压缩预训练模型与压缩finetune之后的模型对比,两者的模型大小或压缩比例有什么区别?
陈天龙表示如果我们从一个合适的模型出发,例如ResNet-50/152,现在的自监督方法如simCLR、Moco,在压缩至一个很小的比率(如10%),再去做下游任务与直接训练下游任务,然后压缩模型至一个相同的比率,两者的performance几乎相同。这也表明了现在的神经网络结合目前先进的自监督方法,能够保持压缩的神经网络在部分任务上的适应性。
李垠桥:针对NLP任务,稀缺资源上会有自监督和无监督模型的使用。例如机器翻译任务中,如果双语资源量不大,我们可以考虑使用无监督方式实现,或使用预训练语言模型提升翻译句子的流利程度。
彩票假说与小模型训练
1.本领域近期有哪些新进展和新的应用领域?
2.Lottery Tickets Hypothesis中的观察能否快速找到适合快速训练的更小模型?对NAS是否有帮助?
彩票假说:任何密集、随机初始化的包含子网络(ticket)的前馈网络,子自网络隔离训练时,可以在相似的迭代次数内达到与原始网络相当的测试精度。
陈天龙从以下几点阐述了目前该领域的最新进展:
1.Transferability角度,在预训练模型上使用彩票假说是否影响模型的迁移性?彩票假说获取的子网络是否能够在连续迁徙训练 (e.g, lifelong learning) 的下游任务上获取一个好的效果?
2. Data Efficiency角度,小样本(100个数据)下GAN训练更加不稳定,而彩票假说能够获得一个稀疏模型,由于该模型参数量少且提供了一个潜在的好的结构先验,能够帮助数据量有限的GAN训练更加稳定。
3. 从Data角度,在图神经网络上对数据使用彩票假说探究,由于图神经网络层数不大而图本身很大且不规则,直接训练图非常困难。可以使用彩票假说,压缩剪枝模型时并对图进行剪枝,
4. 能否从理论上验证彩票假说,并从此出发,设计出更好的剪枝方法?或能否不需要训练即可验证子模型的效果?
在以上进展之外,杨幻睿从其他角度探讨如何利用模型的子网络,如在已训练模型中mask部分链接 (HYDRA: Pruning Adversarially Robust Neural Networks)。另外从多任务的角度出发,在数据不均衡的联合学习场景下基于大网络训练不同的子模型 (LotteryFL: Personalized and Communication-Efficient Federated Learning with Lottery Ticket Hypothesis on Non-IID Datasets)。
李垠桥从结构搜索的角度说了一下彩票假说的进展。彩票假说强调了对剪枝后的模型如何初始化来保证性能的问题。而结构搜索方面也有研究从剪枝方面研究模型结构的搜索,例如NeST(NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm),彩票理论同时也提醒我们,不仅剪枝十分重要,如何训练剪枝后网络方法也同样重要。另外近期的NAS中,超网络和one-shot等方式由于效率高越来越被大家重视,通过超网络获取子网络的结构搜索方法从某种程度上也可以视为与剪枝类似的方法,彩票假说提及的模型初始化方式在这类任务中可能也有帮助。
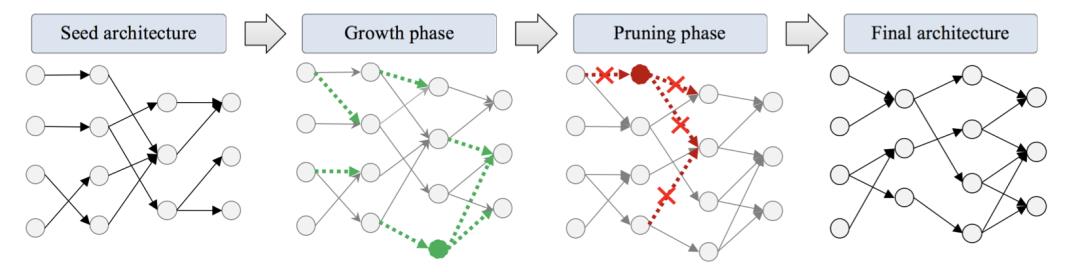
图3:采用剪枝方法的结构搜索
(来源:NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm,https://ieeexplore.ieee.org/document/8704878)
林己表示目前彩票假说已经有了很多具体的应用,如提高训练时的数据效率等。但大多数工作更关注偏理论方面的解释,如通过彩票假说研究神经网络优化空间是否是一个稳定的平面等。
高效神经网络的未来走向
1.近期有哪些值得关注的新的提升模型效率的思路?
2.接下来的一两年中那些领域更有前景?
杨幻睿:
1. 动态网络:针对不同的数据模型使用不同的结构,不减少模型的精度同时提高推断速度,例如动态channel的选择,动态层的选择等等,(Dynamic Neural Networks: A Survey)
2. 模型增长:从小模型出发,逐渐增大模型的容量,(Growing Efficient Deep Networks by Structured Continuous Sparsification)
陈天龙:动态稀疏网络,逐渐探索到一个结构和参数都较好的网络
李垠桥:高效的NAS搜索。指定硬件设备环境下对模型进行约束找到最适合的模型结构。
林己:结合系统/硬件来协同优化高效的神经网络设计。
整理:李健铨
审稿:杨幻睿、陈天龙、李垠桥、林己
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。
更多资讯请扫码关注
我知道你在看哟
↓ 点击 阅读原文 观看直播回放
以上是关于如何迈向高效深度神经网络模型架构?的主要内容,如果未能解决你的问题,请参考以下文章
论文速递TPAMI2022 - 自蒸馏:迈向高效紧凑的神经网络
第26篇MobileNets:用于移动视觉应用的高效卷积神经网络