自动模型压缩与架构搜索,这是飞桨PaddleSlim最全的解读
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动模型压缩与架构搜索,这是飞桨PaddleSlim最全的解读相关的知识,希望对你有一定的参考价值。
机器之心发布
来源:百度飞桨
从剪枝、量化到轻量级神经网络架构搜索与自动模型压缩,越来越强大的飞桨 PaddleSlim 已经模型瘦身提供了一系列高效工具。
近年来,深度学习技术在很多方向都取得了巨大的成功,但由于深度神经网络计算复杂度高,模型参数量大,限制了其在一些场景和设备上进行部署,特别是在移动嵌入式设备的部署。因此,模型小型化技术成为最近几年学术界和工业界研究的热点,模型小型化技术也从最开始的网络剪枝、知识蒸馏、参数量化等发展为最新的神经网络架构搜索()和自动模型压缩等技术。
飞桨核心框架 Paddle Fluid v1.5 版本,PaddleSlim 也发布了最新升级,新增支持基于模拟退火的自动剪切策略和轻量级模型结构自动搜索功能(Light-NAS)。
PaddleSlim 简介
PaddleSlim 是百度飞桨 (PaddlePaddle) 联合视觉技术部发布的模型压缩工具库,除了支持传统的网络剪枝、参数量化和知识蒸馏等方法外,还支持最新的神经网络结构搜索和自动模型压缩技术。
PaddleSlim 工具库的特点
接口简单
以配置文件方式集中管理可配参数,方便实验管理
在普通模型训练脚本上,添加极少代码即可完成模型压缩
效果好
对于冗余信息较少的 MobileNetV1 和 MobileNetV2 模型,卷积核剪切工具和自动网络结构搜索工具依然可缩减模型大小,并保持尽量少的精度损失。
蒸馏压缩策略可明显提升原始模型的精度。
量化训练与蒸馏的组合使用,可同时做到缩减模型大小和提升模型精度。
网络结构搜索工具相比于传统 RL 方法提速几十倍。
功能更强更灵活
剪切压缩过程自动化
剪切压缩策略支持更多网络结构
蒸馏支持多种方式,用户可自定义组合 loss
支持快速配置多种压缩策略组合使用
PaddleSlim 工具库的功能列表
模型剪裁
支持通道均匀模型剪裁(uniform pruning)、基于敏感度的模型剪裁、基于进化算法的自动模型剪裁三种方式
支持 VGG、ResNet、MobileNet 等各种类型的网络
支持用户自定义剪裁范围
量化训练
支持动态和静态两种量化训练方式
动态策略: 在推理过程中,动态统计激活的量化参数。
静态策略: 在推理过程中,对不同的输入,采用相同的从训练数据中统计得到的量化参数。
支持对权重全局量化和 Channel-Wise 量化
支持以兼容 Paddle Mobile 的格式保存模型
蒸馏
支持在 teacher 网络和 student 网络任意层添加组合 loss
支持 FSP loss
支持 L2 loss
支持 softmax with cross-entropy loss
轻量级神经网络结构自动搜索
支持百度自研的基于模拟退火的轻量模型结构自动搜索 Light-NAS
自动模型压缩
支持基于模拟退火自动网络剪枝
其它功能
支持配置文件管理压缩任务超参数
支持多种压缩策略组合使用
PaddleSlim 应用效果
经典压缩 Benchmark
Light-NAS Benchmark
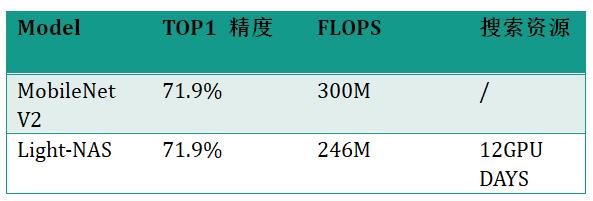
Light-NAS 百度业务应用效果
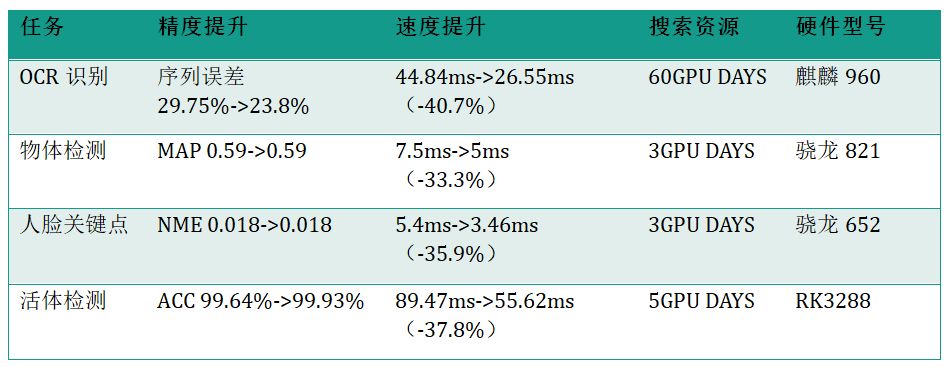
轻量级模型搜索详解
1、自动网络结构搜索
网络结构的好坏对最终模型的效果有非常重要的影响,高效的网络结构可以可以用较少的计算量获得较高的精度收益,比如 MobileNet,ShuffleNet 等,但手工设计网络需要非常丰富的经验和众多尝试,并且众多的超参数和网络结构参数会产生爆炸性的组合,常规的 random search 几乎不可行,因此最近几年神经网络架构搜索技术(Neural Architecture Search)成为研究热点。
区别于传统 NAS,我们专注在搜索精度高并且速度快的模型结构,我们将该功能统称为 Light-NAS。网络结构搜索关键的几个要素一般包括搜索策略、搜索目标评估方法、搜索空间定义和搜索速度优化。
搜索策略
搜索策略定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。常见的搜索方法包括:强化学习、贝叶斯优化、进化算法、基于梯度的算法等。
早期的 NAS 方法中,强化学习使用的比较多。强化学习(Reinforcement learning,简称 RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。强化学习是一种非常有意思的范式,几乎只要可以提炼出强化学习四要素,原问题就可以用强化学习来求解。
论文「NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING」将架构的生成看成是一个 agent 在选择 action,reward 是通过在训练集上训练一定的 epochs 后的精度。在具体的实现过程中,用 RNN 作为控制器来表示策略函数,每次通过 RNN 生成一串编码,通过一个映射函数将编码映射成网络结构,并使用 policy gradient 来优化 RNN 控制器的参数,如图 1 所示。
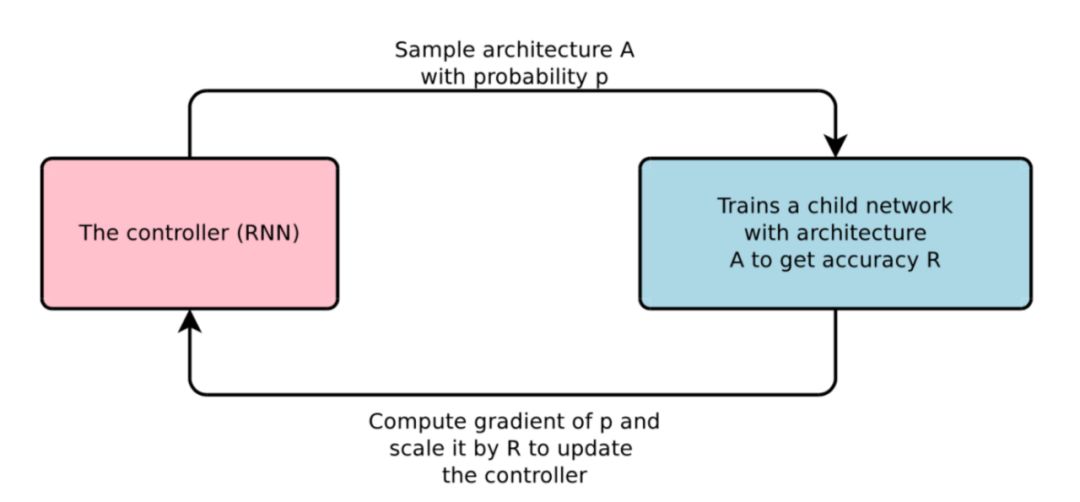
图 1
强化学习策略计算复杂度高、耗时长,因此 PaddleSlim 选用了经典的组合优化策略模拟退火。模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小。鉴于物理中固体物质的退火过程与一般组合优化问题之间的相似性,我们将其用于网络结构的搜索。
在 PaddleSlim 的 NAS 任务中,采用了百度自研的基于模拟退火的搜索策略,区别于 RL 每次重新生成一个完整的网络,我们将网络结构映射成一段编码,第一次随机初始化,然后每次随机修改编码中的一部分(对应于网络结构的一部分)生成一个新的编码,然后将这个编码再映射回网络结构,通过在训练集上训练一定的 epochs 后的精度以及网络延时融合获得 reward,来指导退火算法的收敛,如图 2 所示。
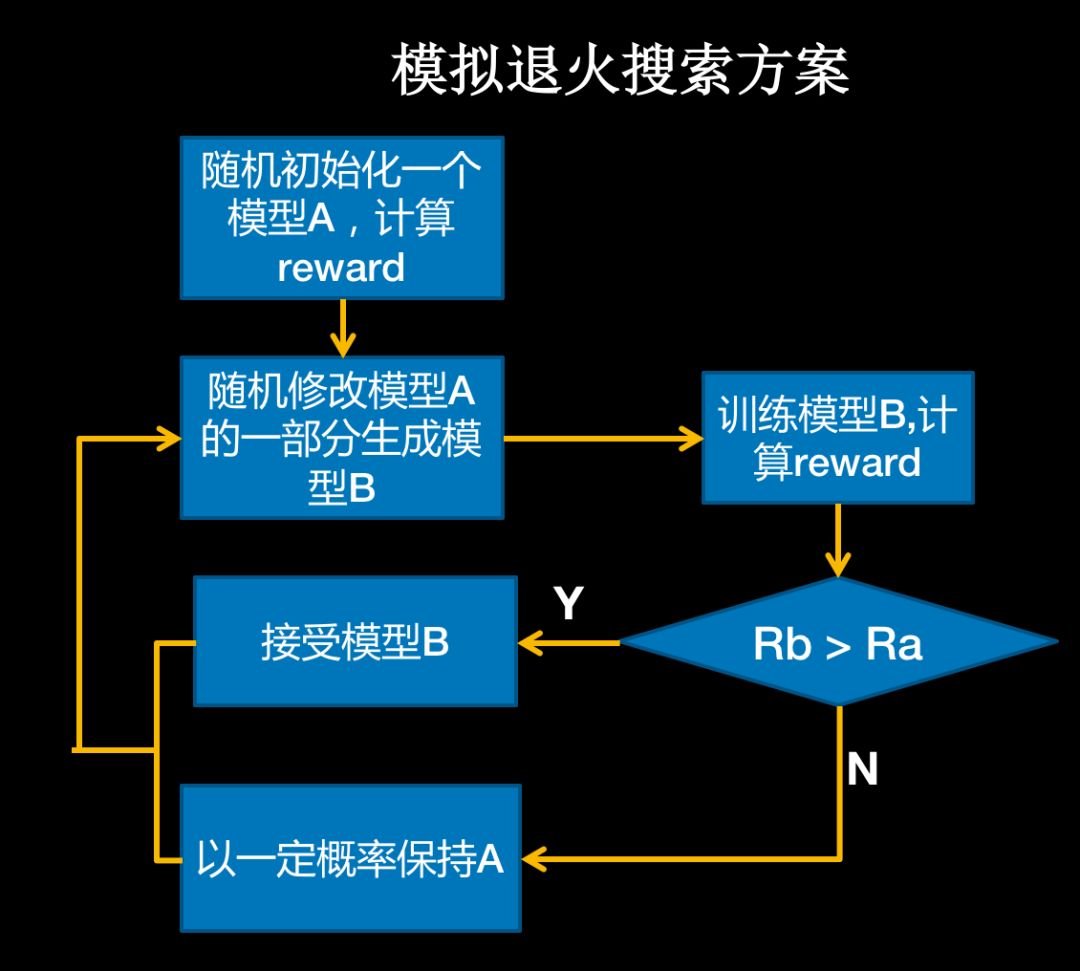
图 2
搜索目标评估方法
相比一般的网络搜索技术,在模型小型化方向,不仅要考虑模型的精度,同时要考虑模型的运行效率,论文「MnasNet」同时将模型的精度以及在手机上运行的时间加权计算作为最终的 reward。
由于每次在手机上运行网络获得延时操作非常繁琐并且耗时,论文「ChamNet」提出将网络结构拆解成若干可穷举的 OP,在手机上运行每个 OP 获得延时并建立一个查找表 LUT,这样每次只需要通过查表并累加各个 OP 的时间就可以快速获得模型整体的运行耗时。PaddleSlim 也正在进行相关功能研发,即将开源,敬请期待。
搜索空间定义
搜索空间定义了优化问题的变量,变量规模决定了搜索算法的难度和搜索时间。因此为了加快搜索速度,定义一个合理的搜索空间至关重要,早期的 NAS 因为没有限制搜索空间,甚至需要使用 800 块 GPU 训练一个月才能收敛。
为了加快收敛速度,论文「Learning Transferable Architectures for Scalable Image Recognition」将网络拆分为多个 Normall Cell 和 Reduction Cell,只搜索这两个子模块中的拓扑结构,然后人工堆叠成最终的网络结构,如图 3 所示。
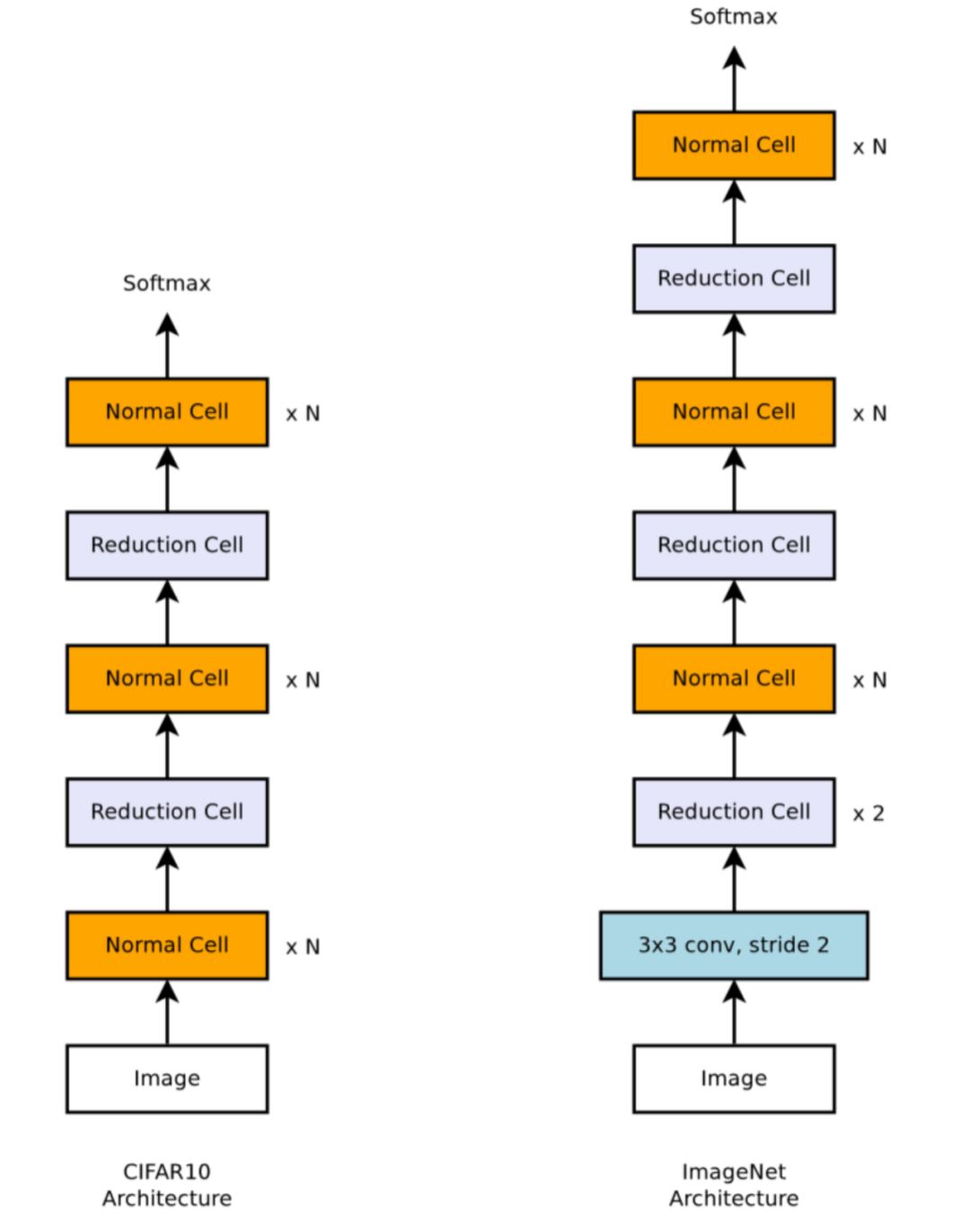
图 3
在模型小型化方向,为了使搜索到的结构尽量高效,PaddleSlim 参考了 MobileNetV2 中的 Linear Bottlenecks 和 Inverted residuals 结构,搜索每一个 Inverted residuals 中的具体参数,包括 kernelsize、channel 扩张倍数、重复次数、channels number,如图 4 所示。
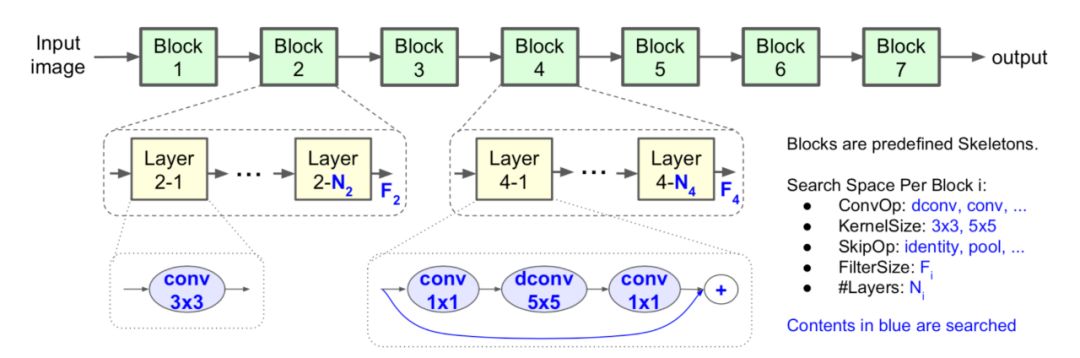
图 4
搜索速度优化
最后在搜索速度优化方面,为了减少采样的网络训练时间,一般采用提前终止的策略,只训练少量 epochs 数获得其在验证集上的精度作为 reward。
最新的一些文章考虑使用参数共享的方案,如论文「Efficient Neural Architecture Search via Parameter Sharing」共享 OP 的参数,而进行拓扑结构的搜索,另外论文「Darts: Differentiable architecture search」基于可微分搜索空间的方案也能加快搜索速度,如图 5,不过其无法搜索 channel 数量,这对于高效的网络结构设计有比较大的限制。PaddleSlim 也正在做这个方向的探索。
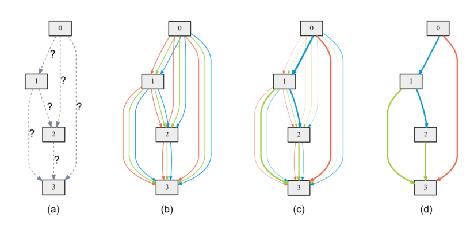
图 5
2、自动模型压缩
自动模型压缩相比 NAS 而言,不是一个从无到有的过程,而是在一个已有的模型(训练好的)基础上进行压缩裁剪,在保证精度的同时,快速获得一个更快、更小的模型。目前传统的剪枝、量化、蒸馏这些人工压缩方法,一方面需要使用者了解算法原理和实现细节,另一方面在使用时有大量繁琐的调参工作,特别是对于模型剪枝,不同任务的最优参数差异很大,因此,如何用机器代替人工,自动搜索出最合适的参数变得非常重要。
在众多的压缩加速方法中,通道剪枝已经被证明非常有效,并在实际业务中广泛应用。通道剪枝压缩后模型不仅在大小上有收益,并且不需要依赖特殊的预测库就能加速,但由于神经网络中不同层的允余程度不同,并且不同层之间存在相互依赖关系,如何确定每一层的压缩率变得十分困难,论文「AMC: AutoML for Model Compression and Acceleration on Mobile Devices」提出使用强化学习搜索每一层最优的剪枝比例。
搜索策略采用 actor-critic 架构的 DDPG 算法,从网络的第一层开始,Actor 网络输入每层的相关参数(input_size、kernel_size、filter_num、stride、flops 等),输出一个(0~0.8)连续值,表示这层的剪枝率,直到模型的最后一层,然后根据输出的压缩率对网络进行裁剪,并将裁剪后的模型在 validation set 上测试得到裁剪后的网络精度作为 reward 来指导 ddpg 收敛,整体的流程如图 6。
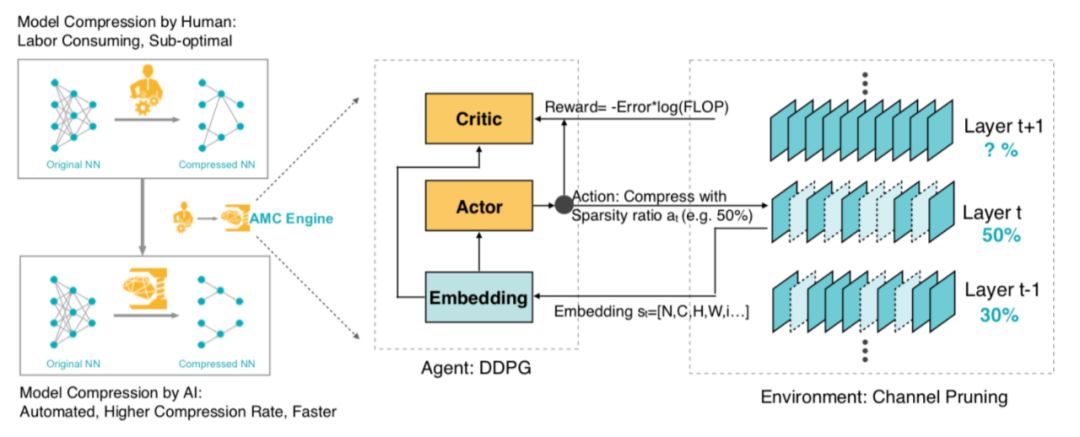
图 6
PaddleSlim 基于模拟退火算法实现了类似的功能,搜素速度有明显的提升。具体的实现方法中,我们将网络的压缩率编码成一个向量,向量中每一维表示某一层的压缩率(取值范围为 0~0.8),初始状态下,随机生成一个向量,然后用向量中的压缩率裁剪整个网络,和用强化学习一样,我们将裁剪后的网络在 validation set 上测试得到裁剪后的网络精度,并使用的延时评估器获取裁剪后网路的速度,将延时和精度融合后得到最终的 reward。
每次结束后,我们会随机改变向量中某一维(也可以是多维),得到网络一个新的裁剪率,根据这个新的向量裁剪网络并获取 reward,根据当前 reward 和前一个状态的 reward 的关系来指导退火算法收敛。
和剪枝类似,在参数量化方向,论文「HAQ: Hardware-Aware Automated Quantization」搜索出每层最优量化位宽已达到最佳的整体量化收益。整体框架和搜索剪枝的类似,如图 7 所示。
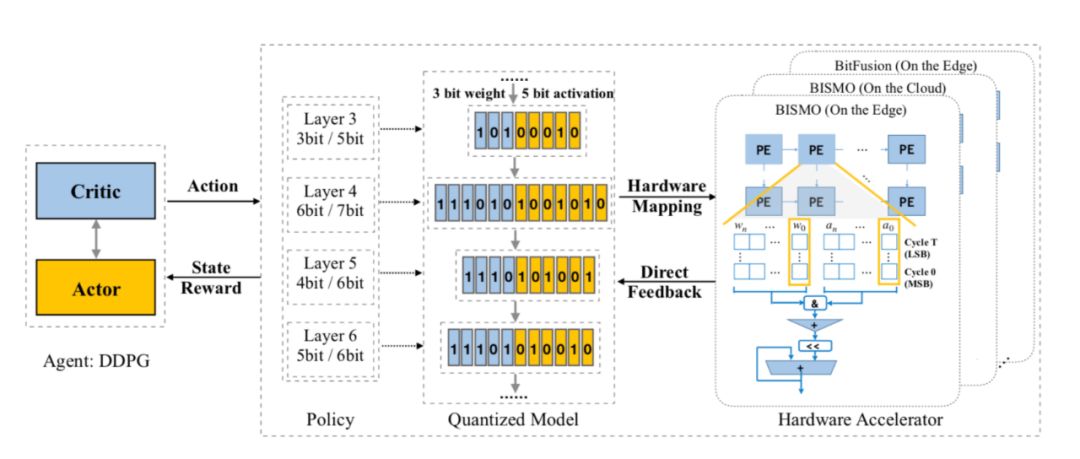
图 7
未来 PaddleSlim 也将支持类似的功能。
经典模型压缩技术详解
PaddleSlim 除了支持新增的基于模拟退火的自动剪切策略和轻量级模型结构自动搜索功能(Light-NAS)以外,之前的版本中已经支持了经典的模型压缩技术,如网络剪枝、参数量化和模型蒸馏等。
一. 剪枝
网络剪枝是将训练好的模型中的允余参数去掉,达到减小模型参数量和计算量的目的。在众多剪枝方法中,可以根据被裁剪的参数是否具有结构化的信息分为细粒度剪枝和结构化剪枝两类。
1、细粒度剪枝
细粒度剪枝主要用于压缩模型的大小,比较有名的是韩松在论文【Deep Compression:Compressing Deep NeuralNetworks with Pruning, Trained Quantization and Huffman Coding】中提出的方法,主要包含剪枝、量化和哈弗曼编码三个步骤。
其具体的思想是认为网络中权值越靠近 0 的神经元对网络的贡献越小,剪枝的过程就是对每一层神经元的权重按照绝对值排序,按一定的比例裁剪掉最小的一部分,使得这些神经元不激活,为了保证剪枝后网络的精度损失尽量小,每次裁剪后都会对保留的非零权重进行 fine-tuning,最终能将模型大小减小 9~13 倍。
为了进一步压缩模型大小,对于剪枝后稀疏的神经元,通过量化编码,将连续的权值离散化,从而用更少比特数来存储浮点权值,如图 8 所示。最后再通过霍夫曼编码进一步压缩模型大小,最终可以在不损失精度的情况下将模型大小压缩 35 到 49 倍。
细粒度剪枝虽然能达到较高的压缩比,但稀疏的权值没有结构化的信息,如果不依赖特定预测库或硬件的优化,模型在实际运行中并不能加速,并且占用的内存也和未压缩前一样。所以细粒度的剪枝方法目前使用的相对比较少,因此 PaddleSlim 中暂未支持。
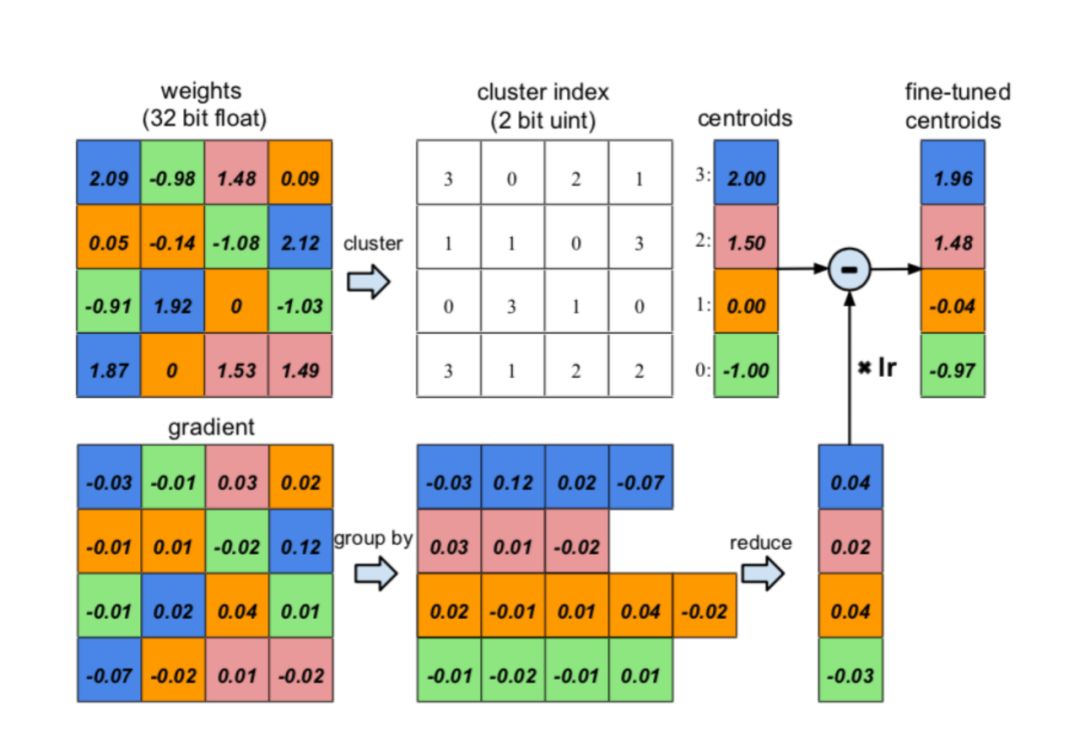
图 8
2、结构化剪枝
相比细粒度剪枝随机地裁剪掉网络中的若干的神经元,结构化剪枝以一定的结构为单位进行剪枝,如裁剪掉卷积层中若干 filter,如图 9 所示。裁剪后的模型相比原始模型,只是 channel 数量减小,不需要额外的预测库支持就能达到加速的目的,因此结构化剪枝是目前使用较多,也是 PaddleSlim 中支持的剪枝方案。
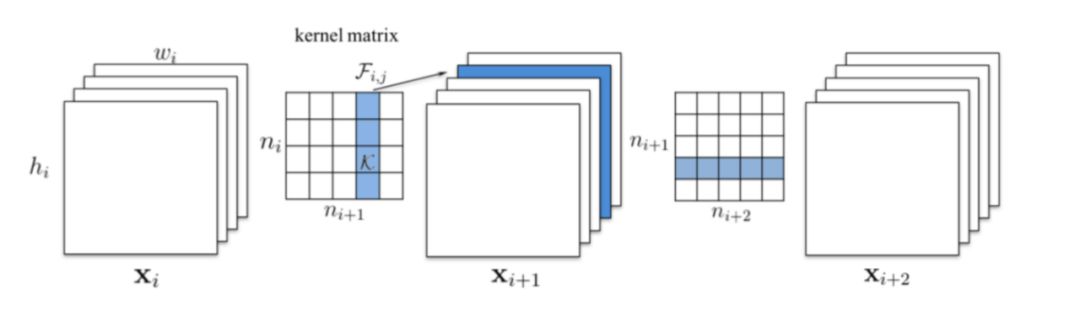
图 9
在剪枝的过程中,如何确定每层的最优剪枝比例和具体要裁剪的 filter,来达到整个模型的最优压缩比是该方法中要解决的问题,对于选择哪些 filter 进行裁剪,常规的方案和细粒度剪枝类似,对不同 filter 的参数计算了 l1_norm,选择值较小的 filter 进行裁剪。
对于每层裁剪的比例,常规的方法是网络中所有层使用同样的比例,没有考虑到模型中不同层参数允余程度的差异性。
论文【Pruning Filters for Efficient ConvNets】提出了一种基于敏感度的剪枝策略,通过不同层对剪枝的敏感度来决定裁剪比例,每层敏感度的计算方法是使用不同裁剪比例对该层进行剪枝,评估剪枝后模型在验证集上的精度损失大小,对于剪枝比例越大,但精度损失越小的层,认为其敏感度越低,可以进行较大比例的裁剪,如图 9 所示。
由于每次剪枝完在验证集上进行评估的开销比较大,该方法在计算敏感度时每次只对其中的一层进行剪枝,没有考虑到不同层之间的相关性,所以实际的敏感度并不是非常准确。
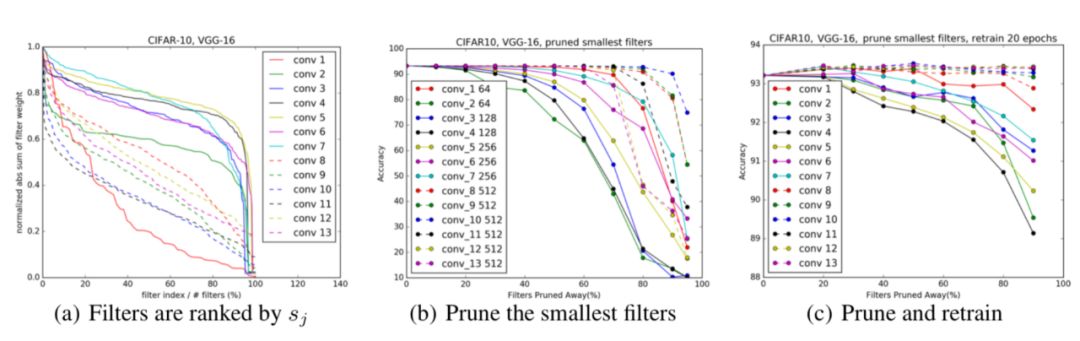
图 10
二、量化
很多嵌入式芯片中都设计有各种位宽的乘法器,将神经网络中 32 位的全精度数据处理成 8 位或 16 位的定点数,同时结合硬件指定的乘法规则,就可以实现低内存带宽、低功耗、低计算资源占用以及低模型存储需求等。
1、8bit 量化
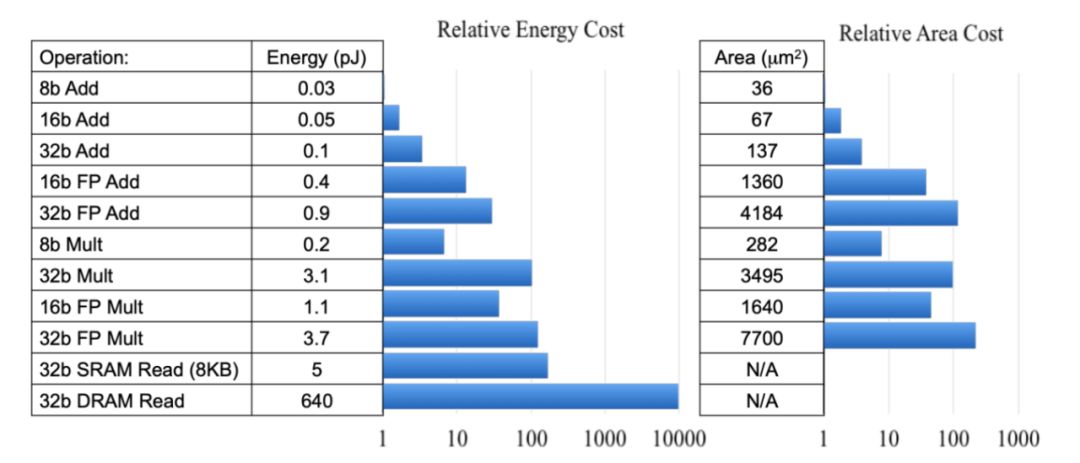
图 11
低精度定点数操作的硬件面积大小及能耗比高精度浮点数要少几个数量级,如图 11 所示。使用 8bit 定点量化可带来 4 倍的模型压缩、4 倍的内存带宽提升,以及更高效的 cache 利用 (很多硬件设备,内存访问是主要能耗)。除此之外,计算速度也通常具有 2~3 倍的提升。另外在很多场景下,定点量化操作对精度并不会造成损失。
目前量化方法主要分为两大类:Post Training Quantization 和 Quantization Aware Training。Post Training Quantization 是指使用 KL 散度、滑动平均等方法确定量化参数,量化过程不需要重新训练。
Quantization Aware Training 是对量化后的模型进行 fine-tuning,通过量化模型产生的梯度更新模型参数,以恢复由于量化而造成的精度损失,它与 Post Training Quantization 模式相比可以提供更高的预测精度。PaddleSlim 实现了 Quantization Aware Training 量化方式。
2、二值神经网络
为了进一步压缩网络的计算量,在 8bit 量化的基础上,论文「Binaryconnect: Training deep neural networks with binary weights during propagations」和「BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1」分别提出了二值权重网络和二值神经网络的概念。
二值权重网络是将网络的权重量化成+1、-1 两个数,对预测过程中的激活值不做量化。这样一方面权重可以用更低的比特数(1bit)来存储达到压缩模型大小的目的,另一方面,原本网络计算中的浮点运算可以被加法代替达到加速的目的。
由于计算机底层硬件在实现两个 n 位宽数据的乘法运算时必须完成 2*n 位宽度的逻辑单元处理,而同样数据在执行加法时只需要 n 个位宽的逻辑单元处理,因此理论上可以得到 2 倍的加速比。
二值神经网络是在二值权重网络的基础上对网络中间激活值也进行二值量化,这样网络中所有的参与运算的数据都量化成了+1、-1 两个数,权重值和激活值都进行二值化之后,原来 32 位浮点型数的乘加运算,可以通过一次异或运算和一次 popcnt(population count 统计有多少个为 1 的位) 运算解决,极大地压缩了计算量,从而达到加速的目的。
不过通过大量实验表明,二值权重网络和二值神经网络的适应性还不是很强,在很多任务上都有较大的精度损失,且对硬件和预测库的优化要求比较高,因此这些方法目前还不是很普及,所以 PaddleSlim 暂未支持。
四、知识蒸馏
一般情况下,模型参数量越多,结构越复杂,其性能越好,但参数也越允余,运算量和资源消耗也越大;知识蒸馏是将复杂网络中的有用信息提取出来,迁移到一个更小的网络中去,以达到模型压缩的效果。
1、传统方案
知识蒸馏最早由 Hinton 在 2015 年提出,核心思想是用一个或多个训练好的 teacher(大模型)指导 student(小模型)进行训练,在论文「Distilling the Knowledge in a Neural Network」中,对于分类任务要学习的目标,将图片实际的类别概率信息称为 hard target(只有真实类别对应的概率为 1,其他为 0),而模型输出的类别概率信息称为 soft target(各个类别概率都为一个大于 0 的值)。
由于类别之间具有相关性,soft target 相比 hard target 具有更高的信息熵,比如一张猫的图片,在 soft target 中,其分到狗的概率一般会大于分到汽车的概率,而不是 hard target 中将它们都设置为 0,导致没有区别。
使用大模型产生 soft target 代替 hard target 能获得更多的信息和更小的梯度方差,可以达到更好的性能。一般模型蒸馏的流程如下,先训好一个大模型,让后让小模型去拟合大模型产生的 soft target,在蒸馏结束后,一般还会使用真实的 label 信息进行 fine-tuning,如图 12 所示。
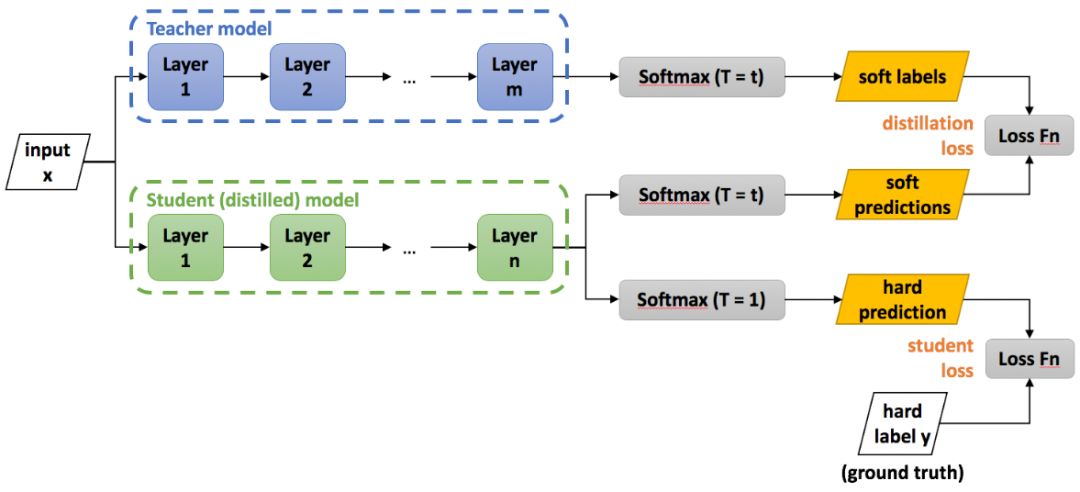
图 12
另外,为了使 soft target 中各个类别的概率值更加平滑,文章中还引入了一个温度系数 T 的概念,对大模型输出的概率值做一个平滑处理,具体如下面公式。
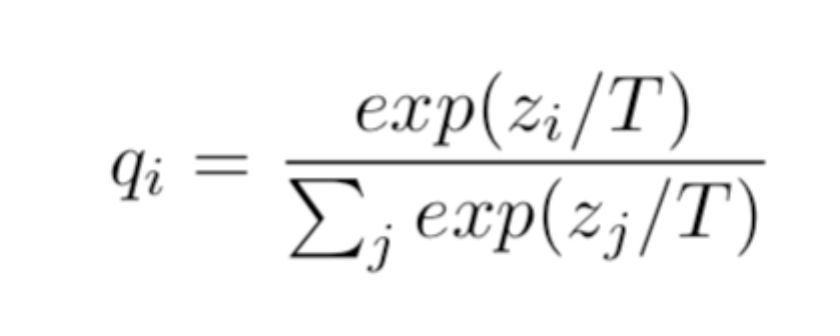
T 一般被设置成一个大于 1 的数,值越大输出的概率值越平滑。
2、fsp 方案
相比传统的蒸馏方法直接用小模型去拟合大模型产生的 soft target,论文「A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning」用小模型去拟合大模型不同层特征之间的转换关系(flow of the solution procedure),其用一个 FSP 矩阵(特征的内积)来表示不同层特征之间的关系,计算公式如下:
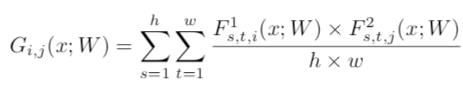
大模型和小模型不同层之间分别获得多个 FSP 矩阵,对于 Resnet 网络结构,每个 stage 可产生一个 FSP 矩阵,然后使用 L2 loss 让小模型的对应层 FSP 矩阵和大模型对应层的 FSP 矩阵尽量一致。
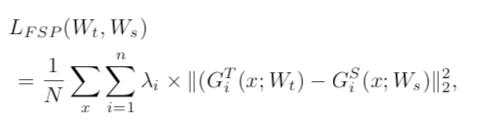
整个过程如图 13 所示。
图 13
这种方法的优势,通俗的解释是,比如将蒸馏类比成 teacher(大模型)教 student(小模型)解决一个问题,传统的蒸馏是直接告诉小模型问题的答案,让小模型学习,而学习 FSP 矩阵是让小模型学习解决问题的中间过程和方法,因此其学到的信息更多,最终效果也更好。
下载最新版本的Paddle Fluid v1.5,请点击阅读原文或查看以下链接:
http://www.paddlepaddle.org.cn?fr=jqzx
以上是关于自动模型压缩与架构搜索,这是飞桨PaddleSlim最全的解读的主要内容,如果未能解决你的问题,请参考以下文章
23个系列分类网络,10万分类预训练模型,这是飞桨PaddleClas百宝箱