论文速递TPAMI2022 - 自蒸馏:迈向高效紧凑的神经网络
Posted 長__安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文速递TPAMI2022 - 自蒸馏:迈向高效紧凑的神经网络相关的知识,希望对你有一定的参考价值。
【论文速递】TPAMI2022 - 自蒸馏:迈向高效紧凑的神经网络
【论文原文】:Self-Distillation: Towards Efficient and Compact Neural Networks
获取地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9381661
CSDN下载:https://download.csdn.net/download/qq_50757624/87387391
博主关键词:知识蒸馏,模型加速,模型压缩,动态神经网络,多出口神经网络,注意力,图像分类
推荐相关论文:
- 无摘要:
在过去的几年里,深度神经网络取得了显著的成就。然而,神经网络精度的突破总是伴随着计算和参数的爆炸式增长,这导致了模型部署的严重限制。在本文中,我们提出了一种名为自蒸馏的新型知识蒸馏技术来解决这个问题。自蒸馏在神经网络的不同深度附加了几个注意力模块和浅层分类器,并将知识从最深的分类器提炼到较浅的分类器。与传统的知识蒸馏方法不同,教师模型的知识转移到另一个学生模型中,自我蒸馏可以被视为同一模型中的知识转移 - 从深层到浅层。此外,自蒸馏中的附加分类器允许神经网络以动态方式工作,从而导致更高的加速度。实验表明,自蒸馏在各种神经网络和数据集上具有一致且显著的有效性。平均而言,在CIFAR100和ImageNet上观察到3.49%和2.32%的精度提升。此外,实验表明,自蒸馏可以与其他模型压缩方法相结合,包括知识蒸馏、修剪和轻量级模型设计。
简介:
深度卷积神经网络在许多应用中都显示出有希望的结果,例如图像分类、目标检测和分割。然而,为了获得良好的性能,现代卷积神经网络总是需要大量的计算和存储,这严重限制了它们在资源有限的设备和实时应用程序的部署。
近年来,这个问题得到了广泛的探索,许多模型压缩和加速方法被提出来解决这个问题。典型的方法包括剪枝,量化,轻量级神经网络设计,低秩分解和知识蒸馏。其中,知识蒸馏是最有效的方法之一,它首先训练一个过度参数化的神经网络作为教师,然后训练一个小的学生网络来模仿教师网络的输出。由于学生模型继承了教师的知识,因此可以替代过度参数化的教师模型,实现模型压缩和快速推理。然而,传统的知识蒸馏一直存在两个问题——教师模型的选择和知识转移的效率。最近,研究人员发现,教师模型的选择对学生模型的准确性有很大影响,准确率最高的老师并不是蒸馏的最佳教师。因此,我们需要大量的实验来寻找最合适的蒸馏教师模型,这可能非常耗时。知识蒸馏的第二个问题是,学生模型不能总是像教师模型那样达到那么高的精度,这可能会导致推理期间不可接受的精度下降。换句话说,仍然很难同时获得准确、高效和紧凑的学生模型。
针对这些问题,该文提出了一种名为自蒸馏的知识蒸馏方法。自蒸馏首先在不同深度的神经网络中间层之后附加几个基于注意力的浅分类器。然后,在训练期间,将更深层次的分类器视为教师模型,并利用它们通过输出上的KL散度损失和特征图上的L2损失来指导学生模型的训练。在推理期间,可以删除所有额外的浅分类器,这样它们就不会带来额外的参数和计算。
与传统知识蒸馏相比,自蒸馏减少了训练开销。由于所提出的自我蒸馏中的教师模型和学生模型都是同一神经网络中的分类器,因此可以避免在常规知识蒸馏中搜索教师模型的大量实验。此外,常规知识蒸馏是一种两阶段的训练方法,我们必须首先训练一个老师,然后用老师来训练学生。相比之下,自我蒸馏是一种单阶段训练方法,其中教师模型和学生模型可以一起训练。自蒸馏的一级特性进一步降低了训练开销。
与传统知识蒸馏相比,自蒸馏可实现更高的精度、加速度和压缩。与传统的知识蒸馏侧重于不同模型之间的知识转移不同,该文所提出的自我蒸馏试图在一个模型中转移知识。实验表明,自蒸馏比其他知识蒸馏方法的效果好得多。此外,我们还发现,自蒸馏和常规知识蒸馏方法可以一起使用,以达到更好的效果。
自蒸馏允许神经网络根据输入图像进行动态推理,从而获得更高的加速度。在通过自蒸馏训练的多分类器神经网络中,深度分类器可以产生更准确的分类结果,而浅分类器可以给出快速分类结果,精度略低。基于这些观察结果,我们进一步提出了一种动态推理机制,该机制允许浅层分类器对简单的图像进行预测,并允许深度分类器预测更难分类的图像。例如,CIFAR100 数据集中超过 95% 的图像可以通过 ResNet18 的最浅分类器进行分类,其精度比基线模型高 3%,加速度提高 3 倍。
大量实验表明,该文所提出的自蒸馏方法在各种数据集和神经网络中实现了显著且一致的精度提升,包括MobileNetV2和ShuffleNetV2等轻量级模型。此外,我们还证明了自蒸馏可用于改善神经网络修剪的结果。
综上所述,本文的主要贡献可以概括如下。
-
我们提出了一种称为自蒸馏的新型蒸馏方法,以实现准确、高效和紧凑的神经网络,与传统的知识蒸馏方法相比,训练开销要少得多。此外,我们证明了自蒸馏和其他蒸馏方法可以一起使用以实现更高的精度。
-
基于自蒸馏,我们提出了一种阈值控制的动态推理机制,该机制允许浅层分类器对简单的图像进行分类,而通过更深的分类器对硬图像进行分类。实验表明,动态推理提供更高的加速度,而不会损失精度。
-
我们评估各种数据集和神经网络中的自蒸馏,并将其与其他最先进的知识蒸馏方法进行比较。已经进行了足够的实验来研究不同因素如何影响自蒸馏以及自蒸馏如何影响不同的模型压缩方法。
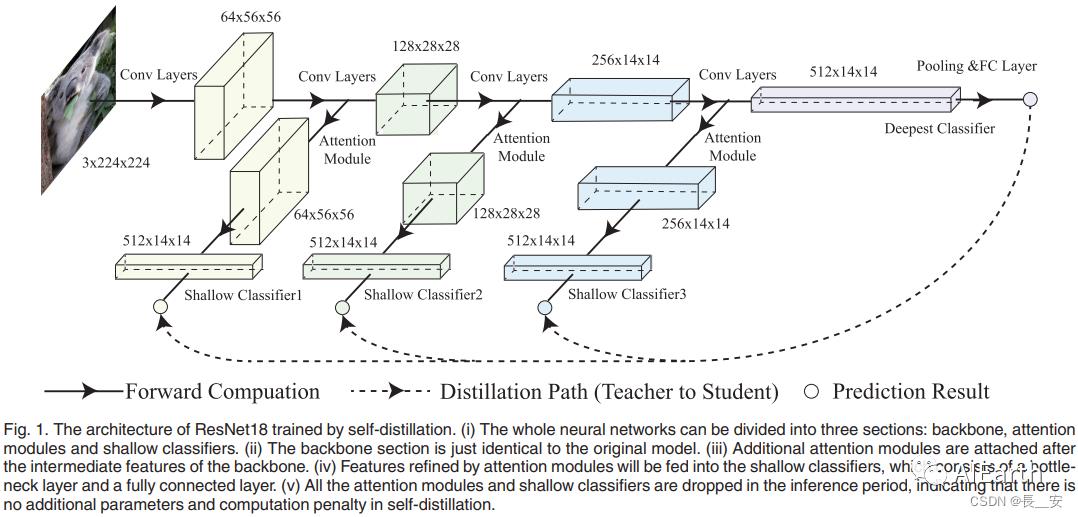
Fig. 1. 由自蒸馏训练的ResNet18的体系结构。(i)整个神经网络可分为主干、注意模块和浅分类器三个部分。(ii)骨干部分与原模型完全相同。(iii)在主干的中间特征之后附加附加注意模块。(iv)将注意模块细化的特征输入到浅分类器中,浅分类器由瓶颈层和全连接层组成。(v)在推理阶段去掉了所有的注意模块和浅分类器,说明自蒸馏过程中不存在额外的参数和计算惩罚。
【社区访问】
 【论文速递 | 精选】
【论文速递 | 精选】
 阅读原文访问社区
阅读原文访问社区
https://bbs.csdn.net/forums/paper
以上是关于论文速递TPAMI2022 - 自蒸馏:迈向高效紧凑的神经网络的主要内容,如果未能解决你的问题,请参考以下文章