Nebula Graph -- 7. 图论中的路径简介
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nebula Graph -- 7. 图论中的路径简介相关的知识,希望对你有一定的参考价值。
参考技术A 图论中一个非常重要的概念是路径,路径是指一个有限或无限的边序列,这些边连接着一系列点。路径的类型分为三种: walk 、 trail 、 path 。以下图为例对路径的类型进行说明。
walk 类型的路径由有限或无限的边序列构成。 遍历时点和边可以重复 。
查看示例图,由于 C、D、E 构成了一个环,因此该图包含无限个路径,例如 A->B->C->D->E 、 A->B->C->D->E->C 、 A->B->C->D->E->C->D 。
GO语句采用的是walk类型路径。
trail 类型的路径由有限的边序列构成。 遍历时只有点可以重复,边不可以重复 。
柯尼斯堡七桥问题的路径类型就是 trail 。
查看示例图,由于边不可以重复,所以该图包含有限个路径,最长路径由 5 条边组成: A->B->C->D->E->C 。
MATCH、FIND PATH和GET SUBGRAPH语句采用的是trail类型路径。
path 类型的路径由有限的边序列构成。 遍历时点和边都不可以重复 。
查看示例图,由于点和边都不可以重复,所以该图包含有限个路径,最长路径由 4 条边组成: A->B->C->D->E 。
Nebula graph 源码 学习笔记
一、概述
Nebula Graph 是一个开源的分布式图数据库,采用了存算分离的设计,存储采用rocksdb。
数据库内核:
1)graph : 用于计算
2)storage:用于存储
3)meta:用于存储元数据
此外,nebula还提供了周边工具,如数据导入(exchange)、监控、可视化、图计算等。
1.1、总体架构
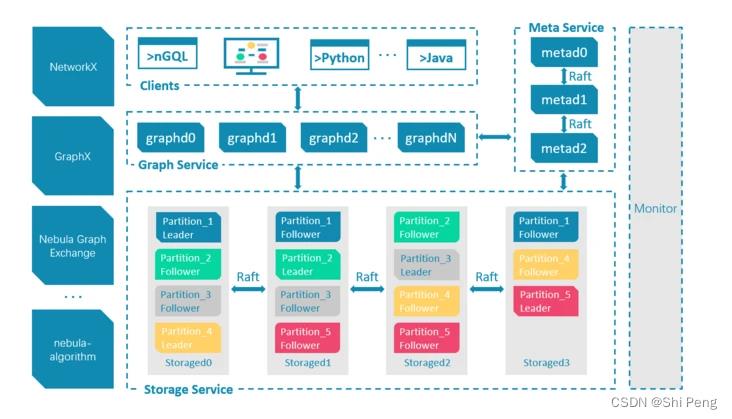
meta:负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。
Graph :服务负责处理计算请求
Storage: 服务负责存储数据
graph 和 storage 通过心跳定期向 meta汇报自身信息, 心跳通过 fbthrift实现,graph 和storage 进程中的成员变量 metaClient_
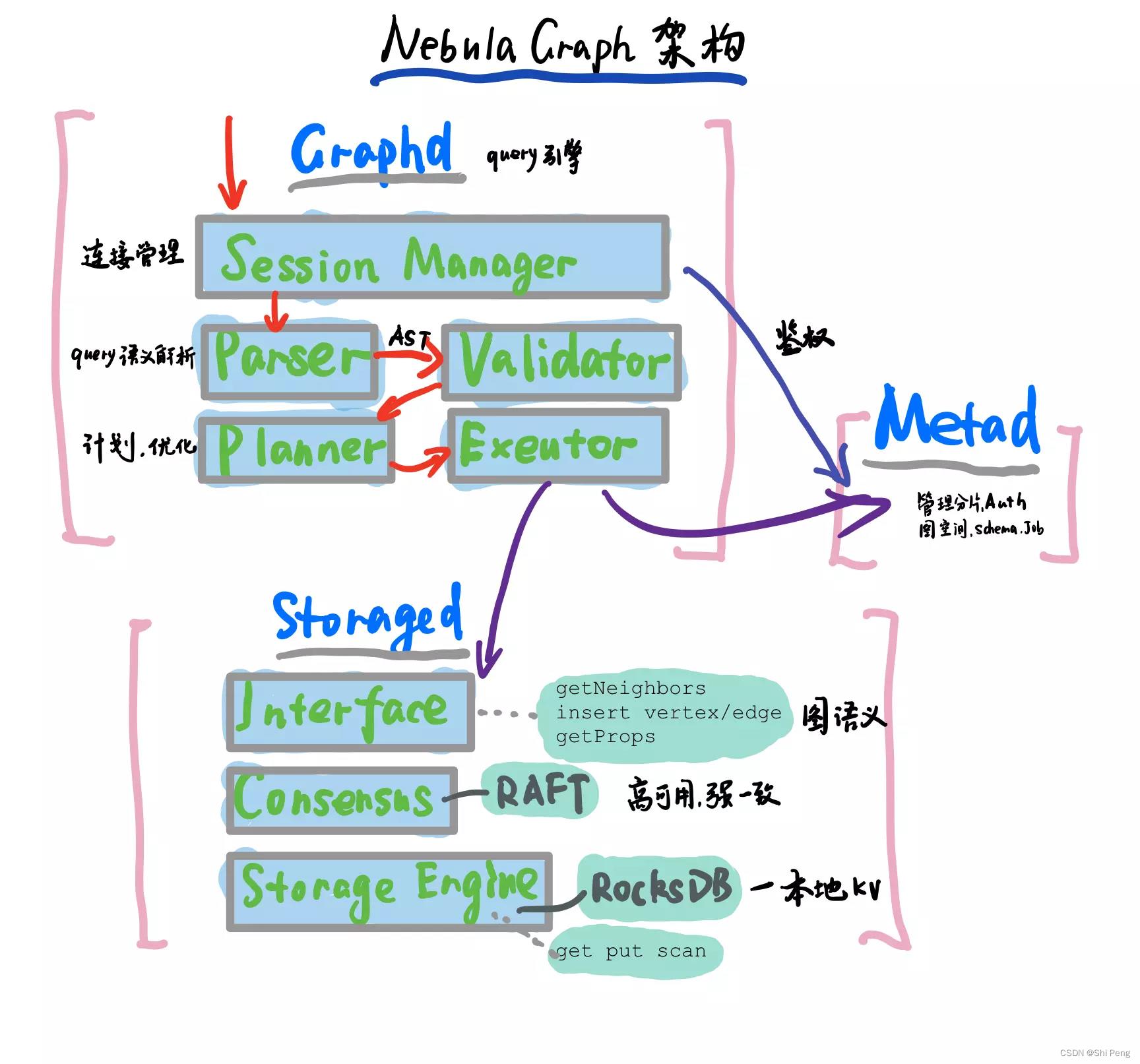
1.2、查询计算引擎架构
查询引擎采用无状态设计,可轻松实现横向扩展,分为语法分析、语义分析、优化器、执行引擎等几个主要部分。
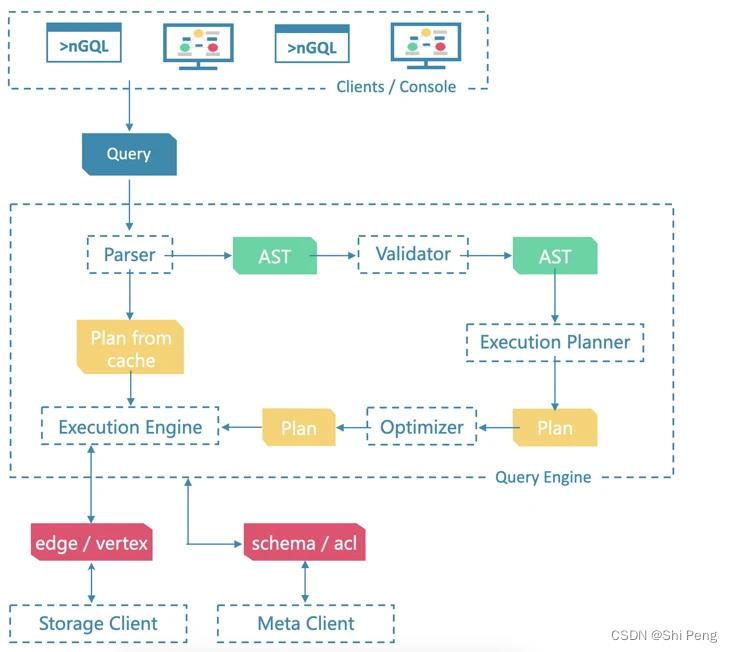
1.3、存储引擎设计
Storage 包含两个部分:
1、meta 相关的存储, 称之为 Meta Service
2、data 相关的存储, 称之为 Storage Service。
Storage Service 共有三层:
1)最底层是 Store Engine;
2)之上便是 Consensus 层,实现了 Multi Group Raft;
3)最上层,是 Storage interfaces,这一层定义了一系列和图相关的 API。
二、源码概览
Nebula的源码地址在:https://github.com/vesoft-inc
vesoft(欧若数网科技有限公司) 是2018年成立于杭州的公司,nebula graph是他们开发的。
2.1、源码模块分类
1、计算查询引擎
https://github.com/vesoft-inc/nebula-graph
2、存储引擎
https://github.com/vesoft-inc/nebula-storage
3、内核工具包
https://github.com/vesoft-inc/nebula-common
4、客户端SDK
1)Java:https://github.com/vesoft-inc/nebula-java
2)C++:https://github.com/vesoft-inc/nebula-cpp
3)Golang:https://github.com/vesoft-inc/nebula-go
4)Python:https://github.com/vesoft-inc/nebula-python
5、工具
1)importer(基于 Go 客户端实现的 csv–>nebula 导入工具):https://github.com/vesoft-inc/nebula-importer
2)基于spark的导入工具,包括Nebula Exchange、Nebula Spark Connector 和 Nebula Algorithm:https://github.com/vesoft-inc/nebula-spark-utils
3)备份恢复工具:https://github.com/vesoft-inc/nebula-br
4)部署工具:https://github.com/vesoft-inc/nebula-ansible,https://github.com/vesoft-inc/nebula-operator(用于容器)
6、测试工具
1)压力与性能测试:https://github.com/vesoft-inc/nebula-bench
2)混沌测试:https://github.com/vesoft-inc/nebula-chaos
7、编译工具
1)Nebula Graph 图数据库内核依赖的第三方包:https://github.com/vesoft-inc/nebula-third-party
2)Nebula Graph 图数据库内核工具链:https://github.com/vesoft-inc/nebula-gears
8、可视化工具
https://github.com/vesoft-inc/nebula-studio
2.2、重点模块结构
2.2.1、计算查询引擎Nebula Graph
├── cmake
├── conf
├── LICENSES
├── package
├── resources
├── scripts
├── src
│ ├── context
│ ├── daemons
│ ├── executor
│ ├── optimizer
│ ├── parser
│ ├── planner
│ ├── scheduler
│ ├── service
│ ├── session
│ ├── stats
│ ├── util
│ ├── validator
│ └── visitor
└── tests
├── admin
├── bench
├── common
├── data
├── job
├── maintain
├── mutate
├── query
└── tck
conf/:查询引擎配置文件目录
package/:graph 打包脚本
resources/:资源文件
scripts/:启动脚本
src/:查询引擎源码目录
src/context/:查询的上下文信息,包括 AST(抽象语法树),Execution Plan(执行计划),执行结果以及其他计算相关的资源。
src/daemons/:查询引擎主进程
src/executor/:执行器,各个算子的实现
src/optimizer/:RBO(基于规则的优化)实现,以及优化规则
src/parser/:词法解析,语法解析,:AST结构定义
src/planner/:算子,以及执行计划生成
src/scheduler/:执行计划的调度器
src/service/:查询引擎服务层,提供鉴权,执行 Query 的接口
src/session/:Session 管理
src/stats/:执行统计,比如 P99、慢查询统计等
src/util/:工具函数
src/validator/:语义分析实现,用于检查语义错误,并进行一些简单的改写优化
src/visitor/:表达式访问器,用于提取表达式信息,或者优化
tests/:基于 BDD 的集成测试框架,测试所有 Nebula Graph 提供的功能
2.2.2、存储引擎Nebula Storage
├── cmake
├── conf
├── docker
├── docs
├── LICENSES
├── package
├── scripts
└── src
├── codec
├── daemons
├── kvstore
├── meta
├── mock
├── storage
├── tools
├── utils
└── version
conf/:存储引擎配置文件目录
package/:storage 打包脚本
scripts/:启动脚本
src/:存储引擎源码目录
src/codec/:序列化反序列化工具
src/daemons/:存储引擎和元数据引擎主进程
src/kvstore/:基于 raft 的分布式 KV 存储实现
src/meta/:基于 KVStore 的元数据管理服务实现,用于管理元数据信息,集群管理,长耗时任务管理等
src/storage/:基于 KVStore 的图数据存储引擎实现
src/tools/:一些小工具实现
src/utils/:代码工具函数
2.2.3、内核工具包Nebula Common
├── cmake
│ └── nebula
├── LICENSES
├── src
│ └── common
│ ├── algorithm
│ ├── base
│ ├── charset
│ ├── clients
│ ├── concurrent
│ ├── conf
│ ├── context
│ ├── cpp
│ ├── datatypes
│ ├── encryption
│ ├── expression
│ ├── fs
│ ├── function
│ ├── graph
│ ├── hdfs
│ ├── http
│ ├── interface
│ ├── meta
│ ├── network
│ ├── plugin
│ ├── process
│ ├── session
│ ├── stats
│ ├── test
│ ├── thread
│ ├── thrift
│ ├── time
│ ├── version
│ └── webservice
└── third-party
Nebula Common 仓库代码是 Nebula 内核代码的工具包,提供一些常用工具的高效实现。这里只对其中和图数据库密切相关的目录进行说明。
src/common/clients/:meta,storage 客户端的 CPP 实现
src/common/datatypes/:Nebula Graph 中数据类型及计算的定义,比如 string,int,bool,float,Vertex,Edge 等。
rc/common/expression/:nGQL 中表达式的定义
src/common/function/:nGQL 中的函数的定义
src/common/interface/:graph、meta、storage 服务的接口定义
二、Storage源码
2.1、Storage概览回顾
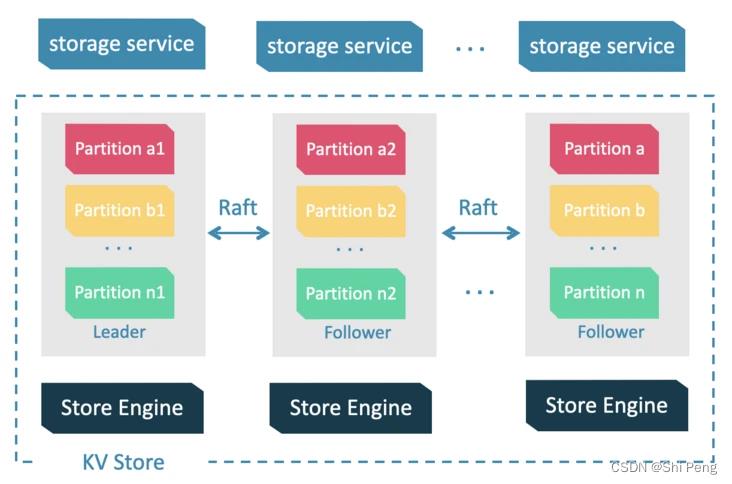
2.1.1、Storage进程
storage 进程分为三层
1、storage interface
这一层定义了一系列和图相关的 API。 这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 kv 操作。比如:getBeightors, Add/delete vertes/edge等等
2、Consensus
实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group,这里的 Partition 就是数据分片。目前 Nebula 的分片策略采用了 静态hash的方式;
用户在创建 SPACE 时需指定 Partition 数,Partition 数量一旦设置便不可更改,一般来讲,Partition 数目要能满足业务将来的扩容需求。
3、Store Engine
单机版 local store engine,提供了对本地数据的 get / put / scan / delete 操作,相关的接口放在 KVStore / KVEngine.h 文件里面,目前 Nebula 提供了基于 RocksDB 实现的 Store Engine。
2.1.2、代码结构
├── cmake
├── conf
├── docker
├── docs
├── LICENSES
├── package
├── scripts
└── src
├── codec
├── daemons
├── kvstore
├── meta
├── mock
├── storage
├── tools
├── utils
└── version
conf/:存储引擎配置文件目录
package/:storage 打包脚本
scripts/:启动脚本
src/:存储引擎源码目录
src/codec/:序列化反序列化工具
src/daemons/:存储引擎和元数据引擎主进程
src/kvstore/:基于 raft 的分布式 KV 存储实现
src/meta/:基于 KVStore 的元数据管理服务实现,用于管理元数据信息,集群管理,长耗时任务管理等
src/storage/:基于 KVStore 的图数据存储引擎实现
src/tools/:一些小工具实现
src/utils/:代码工具函数
2.2、源码阅读
2.2.1、StorageServer类(storage目录下)
2.2.1.1、成员变量
1、std::shared_ptrfolly::IOThreadPoolExecutor ioThreadPool_;
线程池用来处理网络IO任务,从连接中读取请求数据并反序列化
2、std::shared_ptrapache::thrift::concurrency::ThreadManager workers_;
负责处理用户的业务逻辑
3、std::unique_ptrnebula::WebService webSvc_;
监听port: HTTP[19779], HTTP2[19780]
接收外部http命令,比如显示一些flags
4、std::unique_ptrapache::thrift::ThriftServer storageServer_;
监听port:9779
与graph的通信,raft一致性协议使用thrift进行通信,addvertex/edge等
client端提供给grapth进程
5、std::unique_ptrapache::thrift::ThriftServer adminServer_;
监听port:9778
执行任务进程,比如balance,addpart等
client端提供给meta进程
6、std::unique_ptrapache::thrift::ThriftServer internalStorageServer_;
监听port:9777
toss一致性
client端提供给peer storage进程
7、std::unique_ptrmeta::MetaClient metaClient_;
与meta的通信,得到schema信息,心跳等
8、std::unique_ptr interClient_;
InternalStorageService 的客户端,toss一致性
2.2.1.2、StorageServer启动过程
进程启动的入口在:storage/StorageServer.cpp bool StorageServer::start() 函数
主要流程:
1、创建IO线程池,用于处理网络IO
ioThreadPool_ = std::make_shared<folly::IOThreadPoolExecutor>(FLAGS_num_io_threads);
2、创建works_,用于用户的业务请求
workers_ = apache::thrift::concurrency::PriorityThreadManager::newPriorityThreadManager(
numWorkerThreads);
3、创建meta客户端
metaClient_用来与meta进行通信,metaClient_→waitForMetadReady() 会在里面注册发送心跳的请求
storage进行的indexmanger 和 schemamanager去得到相关的index和schma 内部都是用的metaClient的接口
metaClient_ = std::make_unique<meta::MetaClient>(ioThreadPool_, metaAddrs_, options);
4、初始化schemaManager
schemaMan_ = meta::ServerBasedSchemaManager::create(metaClient_.get());
5、初始化indexManager
indexMan_ = meta::ServerBasedIndexManager::create(metaClient_.get());
6、初始化kvstore
kvstore用于实现raft协议. 端口用的9780,包括多个storage 副本之间的数据同步,心跳,将数据写入到rocksdb中.
kvstore_ = getStoreInstance();
7、初始化interClient_
interClient_ = std::make_unique<InternalStorageClient>(ioThreadPool_, metaClient_.get());
8、创建txnMan_
txnMan_ = std::make_unique<TransactionManager>(env_.get());
9、创建taskMgr_
taskMgr_ = AdminTaskManager::instance(env_.get());
10、初始化storageServer_
storageServer_ = getStorageServer();
11、初始化adminServer_
adminServer_ = getAdminServer();
12、internalStorageServer_
internalStorageServer_ = getInternalServer();
关于ioThreadPool_和workers_线程的区分:
1)创建的三个thrift的server对象 StorageServer, Adminserver。interServe 都是以workers_ 为业务线程,ioThreadPool_为IO线程
2)创建kvstore的raftserver也是以workers_ 为业务线程,ioThreadPool_为IO线程
2.2.2、NebulaStore类(kvstore目录下)
2.2.2.1、成员变量
1、SpacePartInfo
SpacePartInfo结构体,用于存储:
1)partitionId–> Part的映射
Part类继承自RaftPart类,其属性包括:
* @param spaceId
* @param partId
* @param localAddr Local address of the Part
* @param walPath Listener's wal path
* @param engine Pointer of kv engine
* @param pool IOThreadPool for listener
* @param workers Background thread for listener
* @param handlers Worker thread for listener
* @param snapshotMan Snapshot manager
* @param clientMan Client manager
* @param diskMan Disk manager
* @param vIdLen Vertex id length of space
注意: 这里的engine,也就是下面engines_里面的engine
2)vector<std::unique_ptr> engines_;
存储有序集合: engines_
每新创建一个space,都会对应rocksdb的一个instance,这个engines_里就保存了每个space的rocksdb instance。
struct SpacePartInfo
~SpacePartInfo()
parts_.clear();
engines_.clear();
std::unordered_map<PartitionID, std::shared_ptr<Part>> parts_;
std::vector<std::unique_ptr<KVEngine>> engines_;
;
2、SpaceListenerInfo结构体
SpaceListenerInfo用于存储partitionId–> ListenerMap的映射
struct SpaceListenerInfo
std::unordered_map<PartitionID, ListenerMap> listeners_;
;
这是ListenerMap的定义:
using ListenerMap = std::unordered_map<meta::cpp2::ListenerType, std::shared_ptr<Listener>>;
3、其他成员变量
* @param options
* @param ioPool IOThreadPool
* @param serviceAddr Address of NebulaStore, used in raft
* @param workers Worker thread
2.2.2.2、NebulaStore初始化过程
NebulaStore初始化入口在 bool NebulaStore::init() 函数,其主要过程为:
1、启动处理线程
bgWorkers_ = std::make_shared<thread::GenericThreadPool>();
bgWorkers_->start(FLAGS_num_workers, "nebula-bgworkers");
storeWorker_ = std::make_shared<thread::GenericWorker>();
2、启动raftService
raftService_ = raftex::RaftexService::createService(ioPool_, workers_, raftAddr_.port);
3、初始化导入
if (!isListener())
// 如果当前storage不是一个Listener
// TODO(spw): need to refactor, we could load data from local regardless of partManager,
// then adjust the data in loadPartFromPartManager.
loadPartFromDataPath();
loadPartFromPartManager();
loadRemoteListenerFromPartManager();
else
// 如果当前storage是一个Listener
loadLocalListenerFromPartManager();
下面重点看loadPartFromDataPath()和loadPartFromPartManager()的过程:
loadPartFromDataPath()的过程
Step1:扫描本地路径,并初始化spaces_
1)把rootPath赋值为:配置文件中的data_path + "/nebula"目录,如/data1/mmdb/storage/nebula
2)对rootPath目录下的所有目录做遍历,/data1/mmdb/storage/nebula的下级目录是每个space的spaceId
3)对spaceId为0的目录跳过
4)为每个spaceId都newEngine,即创建一个rocksdb instance:
auto engine = newEngine(spaceId, path, options_.walPath_);
Step2:为保存到本地的part信息做负载均衡
过程待补充
Step3:load保存到本地engine的part ids
过程待补充
Step4:创建part并加入到space
过程待补充
loadPartFromPartManager()过程
1)根据storeSvcAddr_从cache中获取partsMap
2)遍历partsMap,拿到spaceId后, addSpace(spaceId);
3)把每个peerPart存入 vector partIds,并排序
4)对partIds遍历,并执行 addPart(spaceId, partId, false, partPeers[partId].hosts_);
addSpace的过程
newEngine有两个地方被触发:
1) loadPartFromDataPath()的过程
2)loadPartFromPartManager() 中addSpace当engine不存在时
newEngine的过程:会创建一个rocksdb的instance并返回
return std::make_unique<RocksEngine>(
spaceId, vIdLen, dataPath, walPath, options_.mergeOp_, cfFactory);
addSpace的过程:
Step1:加写锁
Step2:如果当前storage不是Listener角色:则遍历所有engine以确保每一个dataPath都有一个engine
1、如果spaceId在std::unordered_map<GraphSpaceID, std::shared_ptr> spaces_中:
1)拼装出dataPath:配置中的dataPath + “/nebula/” + spaceId
2)从RocksDBEngine.h缓存dataPath_中查询auto dPath = (*iter)->getDataRoot();
3)比较二者是否一致,从而判断engine是否存在
4)如果engine不存在,则newEngine,并新创建的Engine即rocksdb instance存放到SpacePartInfo结构体中的std::vector<std::unique_ptr> engines_;中。
2、如果spaceId不在std::unordered_map<GraphSpaceID, std::shared_ptr> spaces_中:
则newEngine,并新创建的Engine即rocksdb instance存放到SpacePartInfo结构体中的std::vector<std::unique_ptr> engines_;中。
Step3:如果当前storage是Listener角色
1、如果spaceId在std::unordered_map<GraphSpaceID, std::shared_ptr> spaces_中:
打印spaceId已存在,然后返回
2、如果spaceId不在std::unordered_map<GraphSpaceID, std::shared_ptr> spaces_中:
创建SpaceListenerInfo实例
2.2.2.3、NebulaStore的ingest过程
NebulaStore的ingest过程在NebulaStore.cpp的nebula::cpp2::ErrorCode NebulaStore::ingest(GraphSpaceID spaceId)函数。
ingest指根据spaceId找到Engine并读取.sst文件写入nebula的过程:
Step1:根据spaceid去std::unordered_map<GraphSpaceID, std::shared_ptr> spaces_; 这个map中找到SpacePartInfo结构体
Step2:从SpacePartInfo结构体中找到他的成员vector<std::unique_ptr> engines_;
Step3:对vector<std::unique_ptr> engines_遍历,找出每个RocksEngine
Step4:对每个Engine,列出其所有的partition
Step5:对其列出的每个partition遍历
1)从std::unordered_map<GraphSpaceID, std::shared_ptr> spaces_; 中根据spaceid找到shared_ptr,
从SpacePartInfo中找到std::unordered_map<PartitionID, std::shared_ptr> parts_;
从parts_中找到KVEngine,即为RocksEngine
2)先拼装出其下载的目录:如/data1/mmdb/storage/download/spaceid
3)遍历目录下的所有文件,做rocksdb的IngestExternalFile(files, options)
以上是关于Nebula Graph -- 7. 图论中的路径简介的主要内容,如果未能解决你的问题,请参考以下文章