CS294-112深度增强学习课程(加州大学伯克利分校 2017)NO.4 Learning policies by imitating optimal controllers
Posted ecoflex
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS294-112深度增强学习课程(加州大学伯克利分校 2017)NO.4 Learning policies by imitating optimal controllers相关的知识,希望对你有一定的参考价值。



There are some problems: mismatch of model and reality; gradient explosion
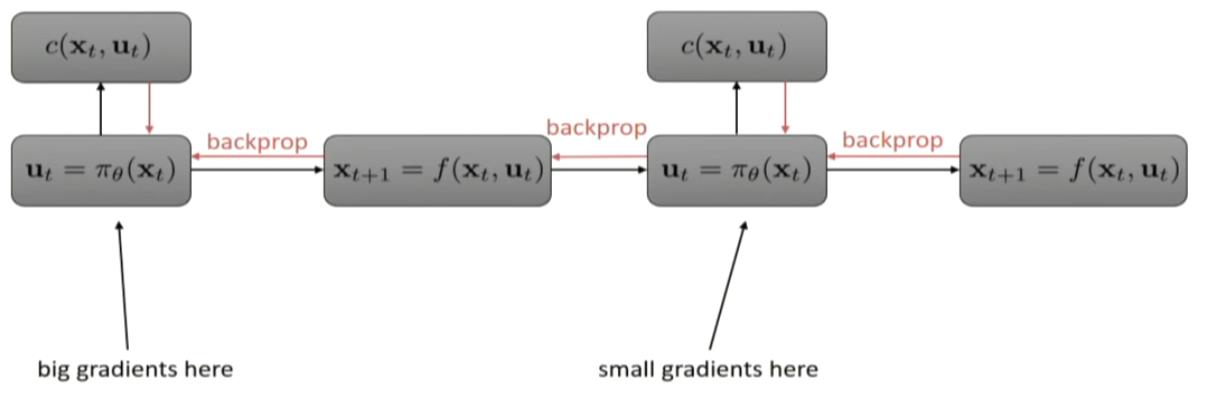

so, the dynamics can be quite messy, and backpropogating can be quite problematic.
sudden change in velocity and so on. schochastic system. gradient descent can be tough.
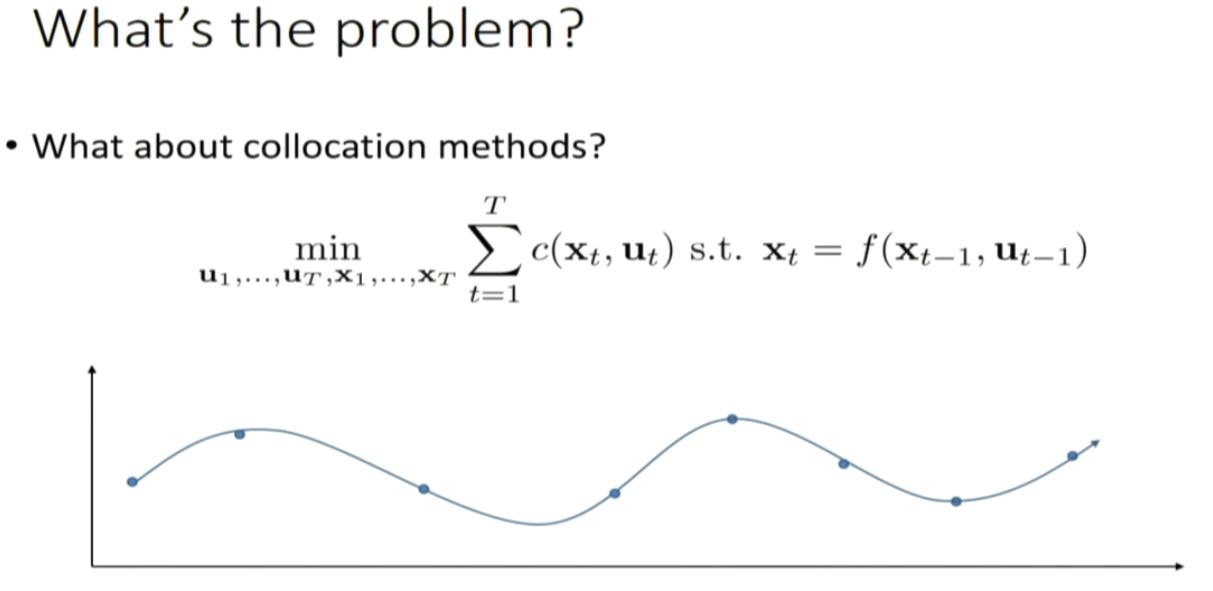
can we apply this trajectory optimization method to optimize policy?

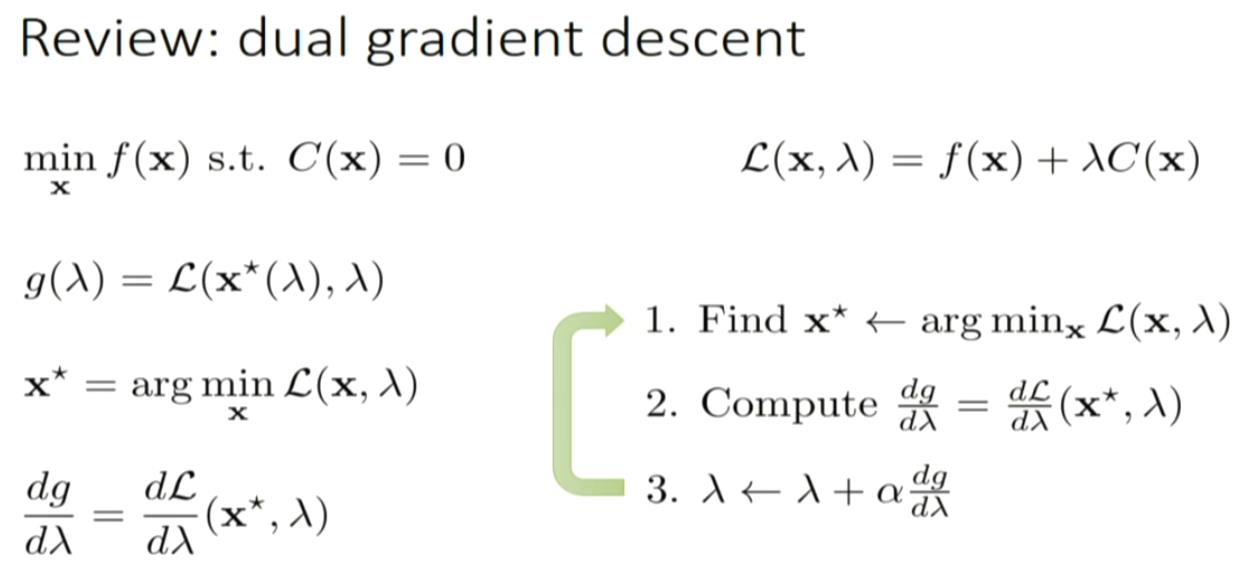
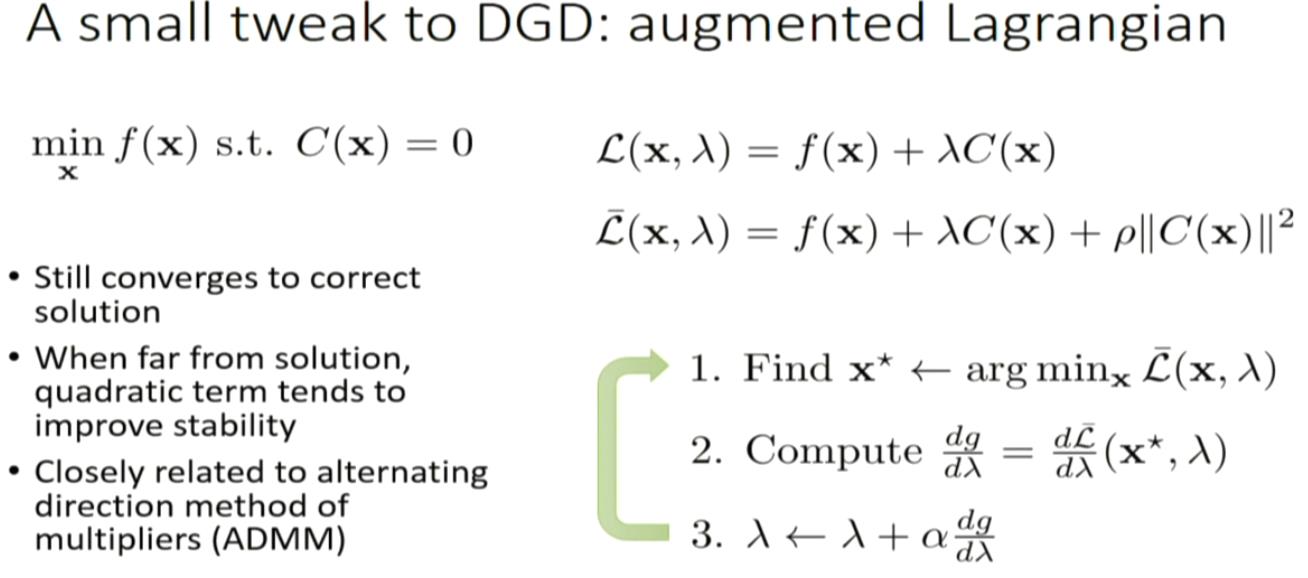



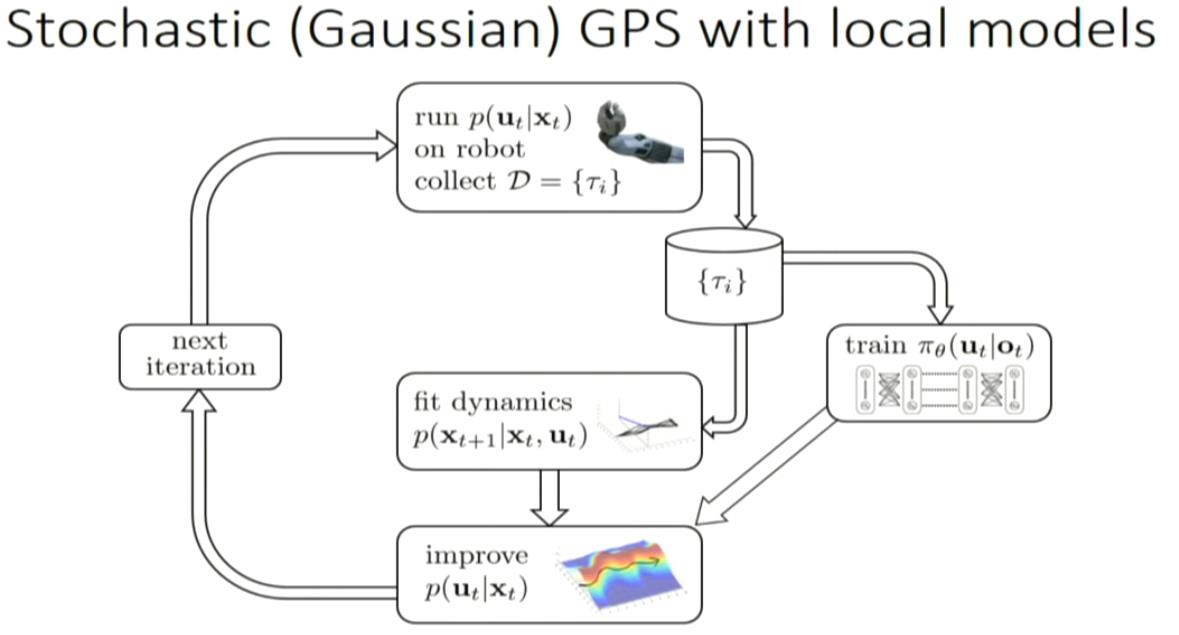
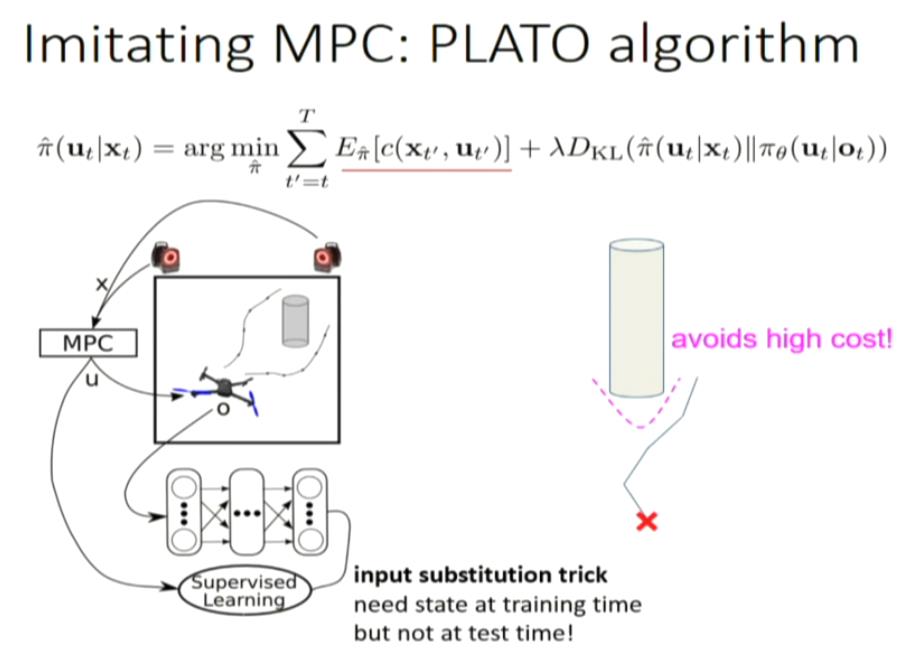
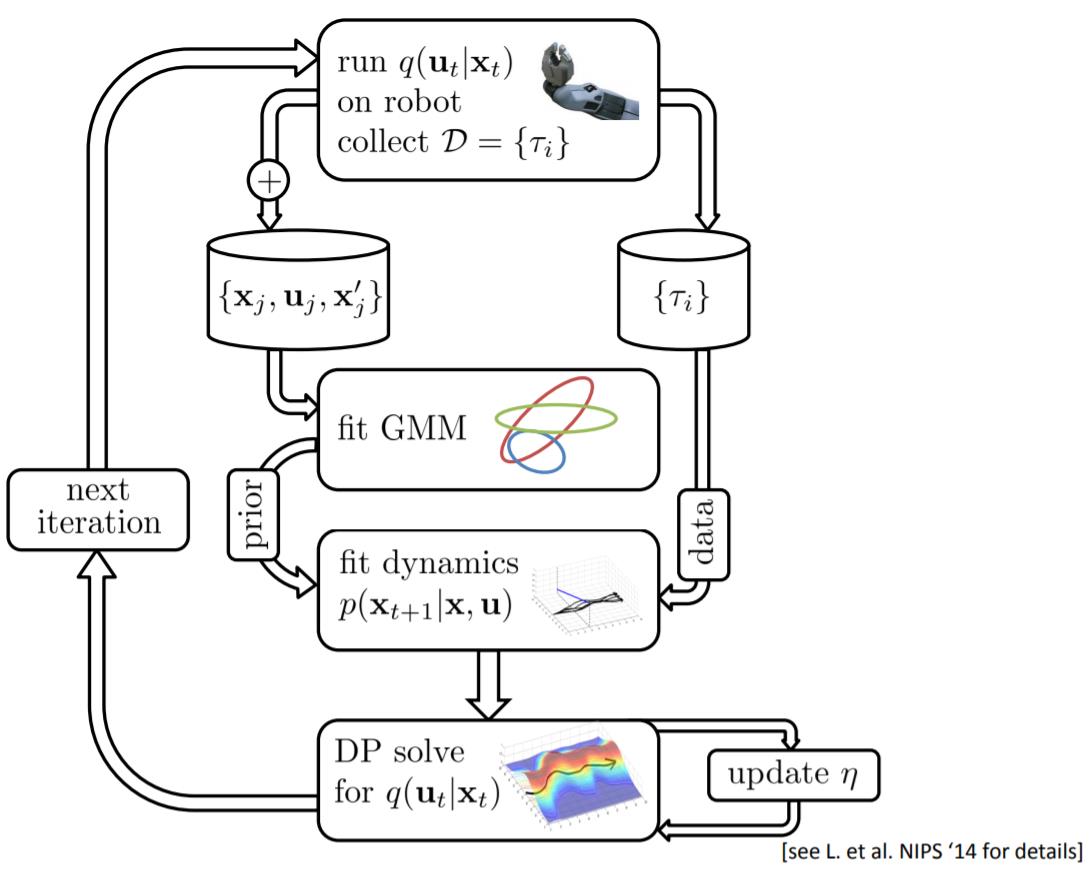
GPS: guided policy search
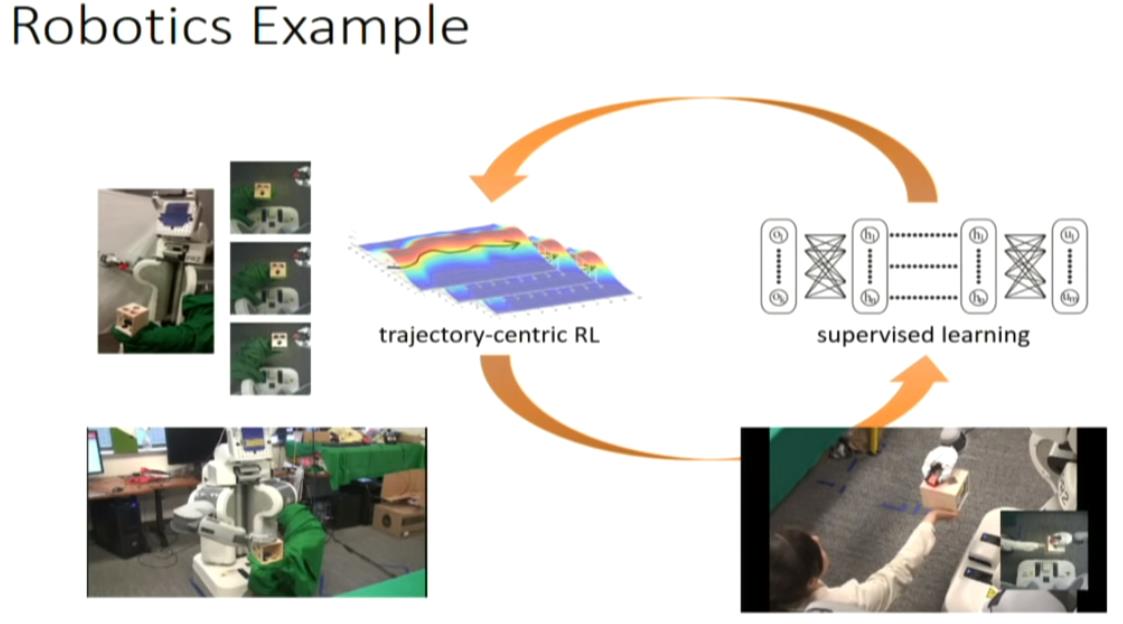
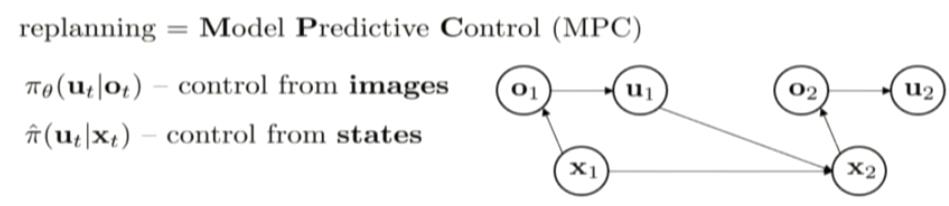
in this case, ot is from the camera and the joint velocity















https://katefvision.github.io/katefSlides/imitate_controlers_katef.pdf
以上是关于CS294-112深度增强学习课程(加州大学伯克利分校 2017)NO.4 Learning policies by imitating optimal controllers的主要内容,如果未能解决你的问题,请参考以下文章
CS294-112 深度强化学习 秋季学期(伯克利)NO.15 Exploration 2
CS294-112 深度强化学习 秋季学期(伯克利)NO.4 Policy gradients introduction
CS294-112 深度强化学习 秋季学期(伯克利)NO.5 Actor-critic introduction
CS294-112 深度强化学习 秋季学期(伯克利)NO.6 Value functions introduction NO.7 Advanced Q learning
CS294-112 深度强化学习 秋季学期(伯克利)NO.9 Learning policies by imitating optimal controllers
CS294-112 深度强化学习 秋季学期(伯克利)NO.20 Guest lecture: John Schulman (PPO and Applications)