CS294-112 深度强化学习 秋季学期(伯克利)NO.6 Value functions introduction NO.7 Advanced Q learning
Posted ecoflex
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS294-112 深度强化学习 秋季学期(伯克利)NO.6 Value functions introduction NO.7 Advanced Q learning相关的知识,希望对你有一定的参考价值。

--------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------------------------------



understand that correlated samples cause problem. and how paralled solve the problem
another solution is replay buffers, fully ultilizing the advantage of off policy in Q-learning.




there\'s still a problem: Q learning is not gradient descent


divide Q function into two parts: the target net and the evolving net.
sacrifice speed to get the convergence.





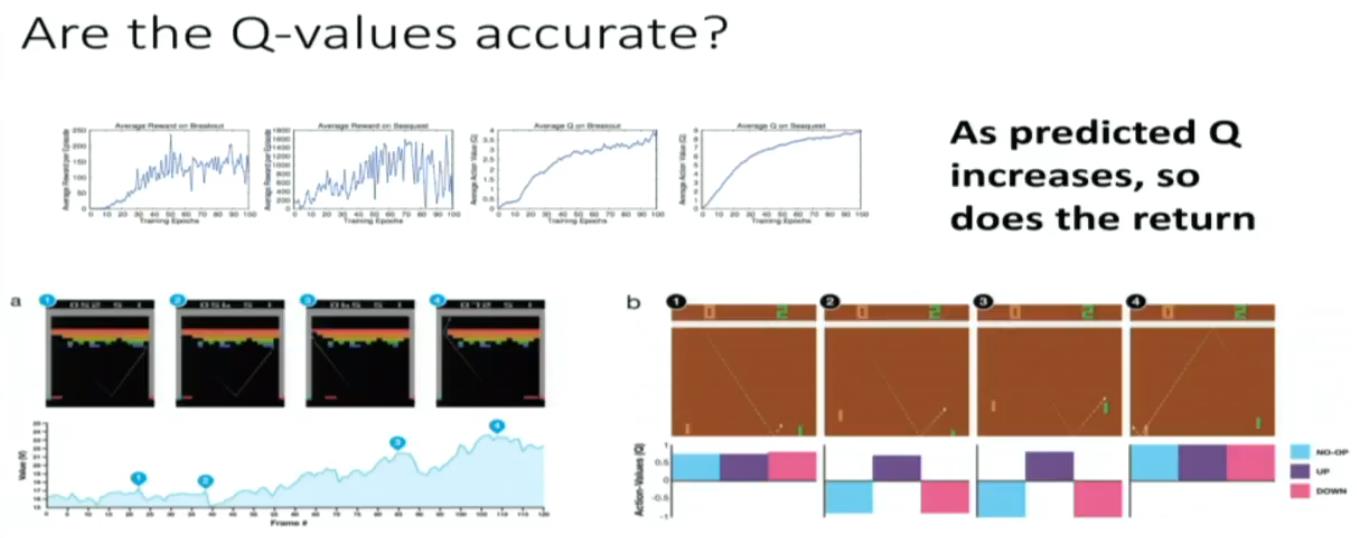

overestimation of Natural DQN








get trouble in left and right dilemma of avoiding bumping on a tree

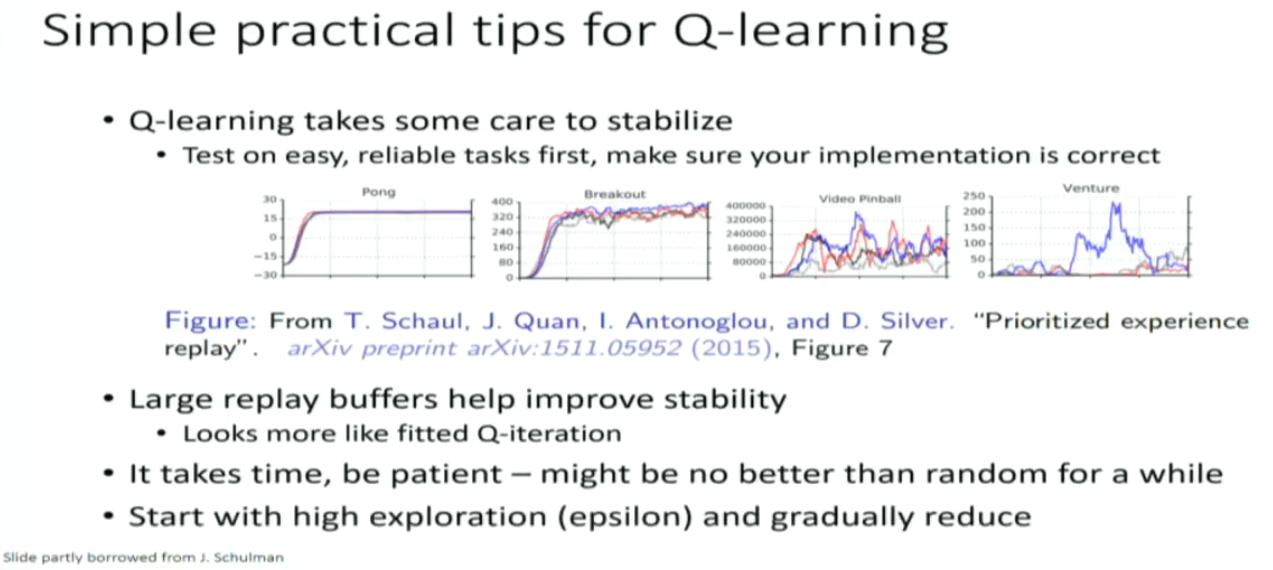


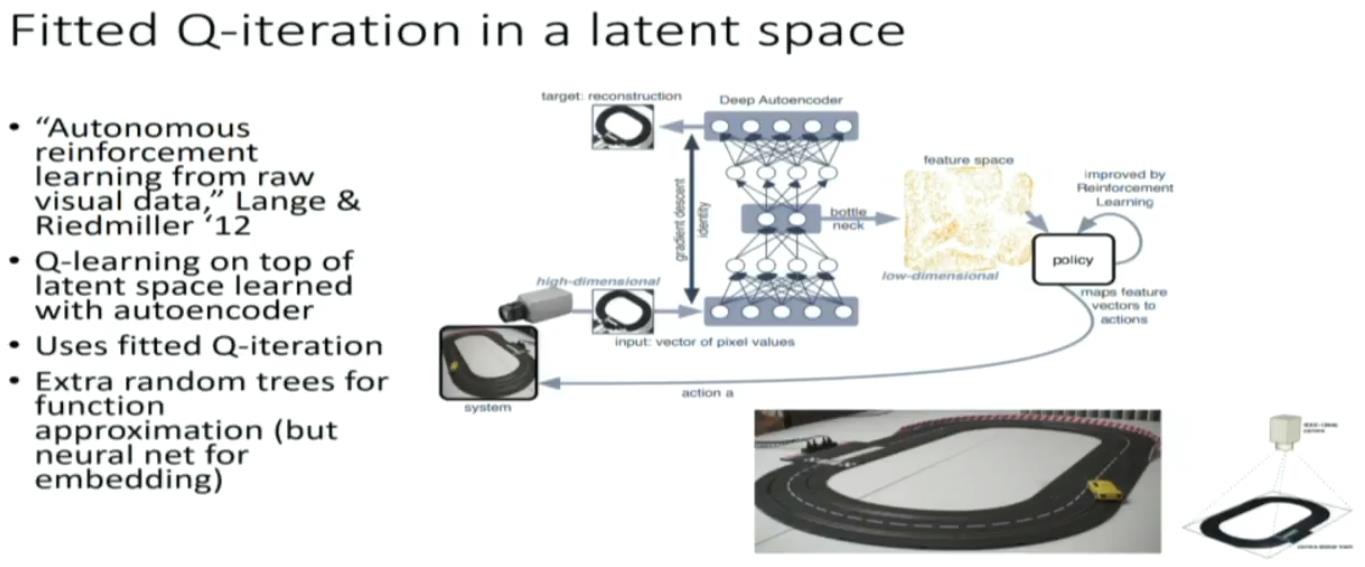




以上是关于CS294-112 深度强化学习 秋季学期(伯克利)NO.6 Value functions introduction NO.7 Advanced Q learning的主要内容,如果未能解决你的问题,请参考以下文章
CS294-112 深度强化学习 秋季学期(伯克利)NO.5 Actor-critic introduction
CS294-112 深度强化学习 秋季学期(伯克利)NO.6 Value functions introduction NO.7 Advanced Q learning
CS294-112 深度强化学习 秋季学期(伯克利)NO.9 Learning policies by imitating optimal controllers
CS294-112 深度强化学习 秋季学期(伯克利)NO.20 Guest lecture: John Schulman (PPO and Applications)
CS294-112 深度强化学习 秋季学期(伯克利)NO.19 Guest lecture: Igor Mordatch (Optimization and Reinforcement Learnin
CS294-112 深度强化学习 秋季学期(伯克利)NO.21 Guest lecture: Aviv Tamar (Combining Reinforcement Learning and Plan