Deep RL Bootcamp Frontiers Lecture I: Recent Advances,
Posted ecoflex
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep RL Bootcamp Frontiers Lecture I: Recent Advances,相关的知识,希望对你有一定的参考价值。



high bias
if the robot has learnt something (no changes appear with iterations)
however, in the real world tasks, the task could change a little bit, then the robot will failed to generalize.

no matter how well we train the robot in situations, there\'s always something that happens and messes up the system.






14 robot, sharing their own experience to each other



here the goal is to grasp anything. no task here









a few clips of our best trained neural network, picking up four objects that are visually kind of similar. They are all blue and roughly the same size, roughly rectangular.















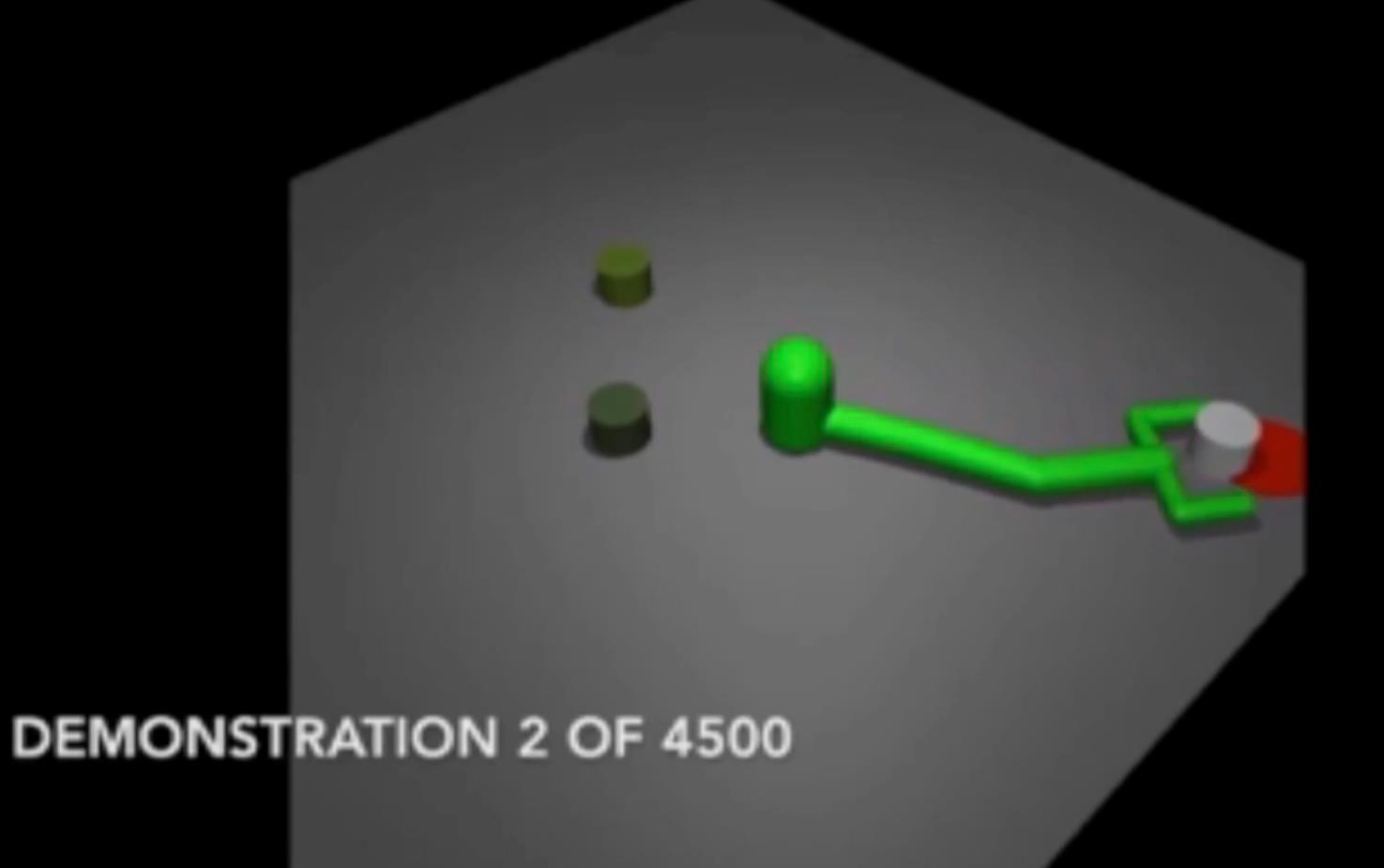



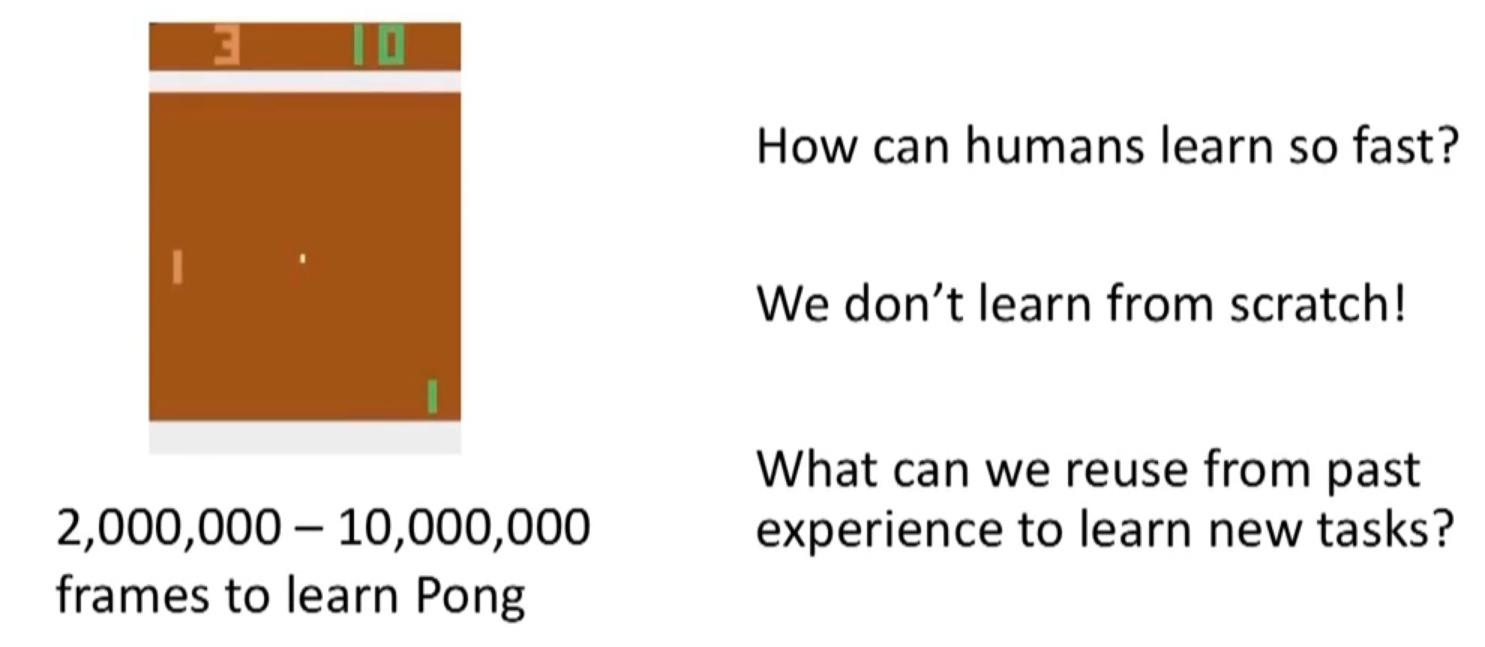









imitation learning










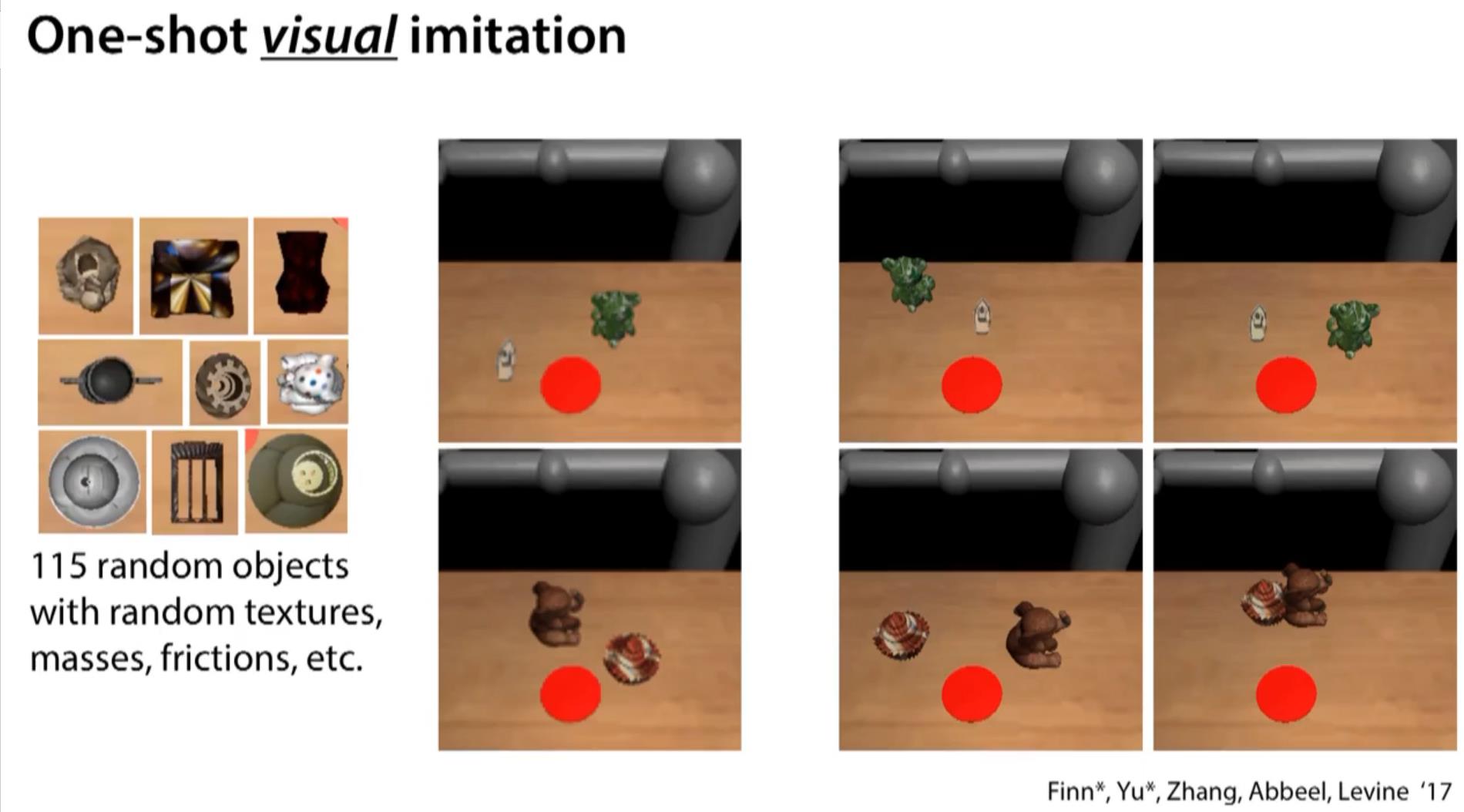
 push the green tedy bear to the red spot
push the green tedy bear to the red spot











终于结束了,接下来需要
1,学习使用tensorflow和pytorch
2,对CNN、RNN、GAN动手实践,做项目
(大概需要20天)
3,学习基础的ML(大概需要4天)
4,学习raspberry pi和arduino(大概需要4天)
以上是关于Deep RL Bootcamp Frontiers Lecture I: Recent Advances,的主要内容,如果未能解决你的问题,请参考以下文章
Deep RL Bootcamp Lecture 4A: Policy Gradients
Deep RL Bootcamp Lecture 8 Derivative Free Methods
Deep RL Bootcamp Lecture 4B Policy Gradients Revisited
Deep RL Bootcamp Lecture 5: Natural Policy Gradients, TRPO, PPO
Deep RL Bootcamp Lecture 7: SVG, DDPG, and Stochastic Computation Graphs
Deep RL Bootcamp Lecture 2: Sampling-based Approximations and Function Fitting