Storm笔记整理:Storm核心概念与验证——并行度与流式分组
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm笔记整理:Storm核心概念与验证——并行度与流式分组相关的知识,希望对你有一定的参考价值。
[TOC]
Storm核心概念之并行度
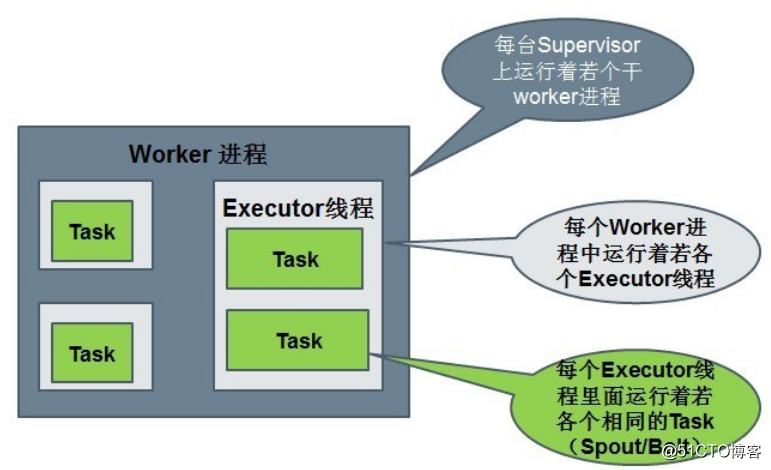
Work
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的(spout或bolt)。因此,1个运行中的topology就是由集群中多台(可能是一台)物理机上的一个或者多个worker进程组成的。
Executor
executor是worker进程启动的一个单独线程。
每个executor只会运行1个topology的1个或者多个(spout或bolt)task(注:task可以是1个或多个,storm默认是1个(spout或bolt)只生成1个task,executor线程会在每次循环里顺序调用所有task实例)。
Task
task是最终运行spout或bolt中代码的执行单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个(spout或bolt)的task数目是固定不变的,但该(spout或bolt)使用的executor线程数可以动态调整(例如:1个executor线程可以执行该(spout或bolt)的1个或多个task实例)。这意味着,对于1个(spout或bolt)存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
默认情况下,一个supervisor节点最多可以启动4个worker进程,每一个topology默认占用一个worker进程,每个spout或者bolt会占用1个executor,每个executor启动1个task。
并行度调整之work进程个数
前面提交作业到集群时,worker、executor和task的数量情况如下:
之前是1个worker进程 3个executor线程 3个task任务
3个executor,分别为:
id_num_spout
id_sum_bolt
__acker现在在代码中将其worker个数设置为2,如下:
package cn.xpleaf.bigdata.storm.parallelism;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class ParallelismWorkerSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt())
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = ParallelismWorkerSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
/**
* 之前是1个worker进程 3个executor线程 3个task任务
* 3个executor,分别为:
* id_num_spout
* id_sum_bolt
* __acker
*
* 将worker进程修改为2个后:
* executor线程数:4个
* task任务数:4个
* 分析:
* 最简单的原因就是,我们的应用程序太小了,完全没有必要开启多个executor线程。
* 也就是说不会简单的进行worker的副本拷贝,这里多出来的一个executor线程是每一个worker进程都有的
* 一个默认的系统级别的bolt,就是__acker
*/
config.setNumWorkers(2); // 设置当前topology启动需要几个worker进程
// config.setNumAckers(0); // 设置__acker数量为0个,这样就不会有其executor线程
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}打包后上传到集群中并提交,在storm ui中查看其状态,如下:
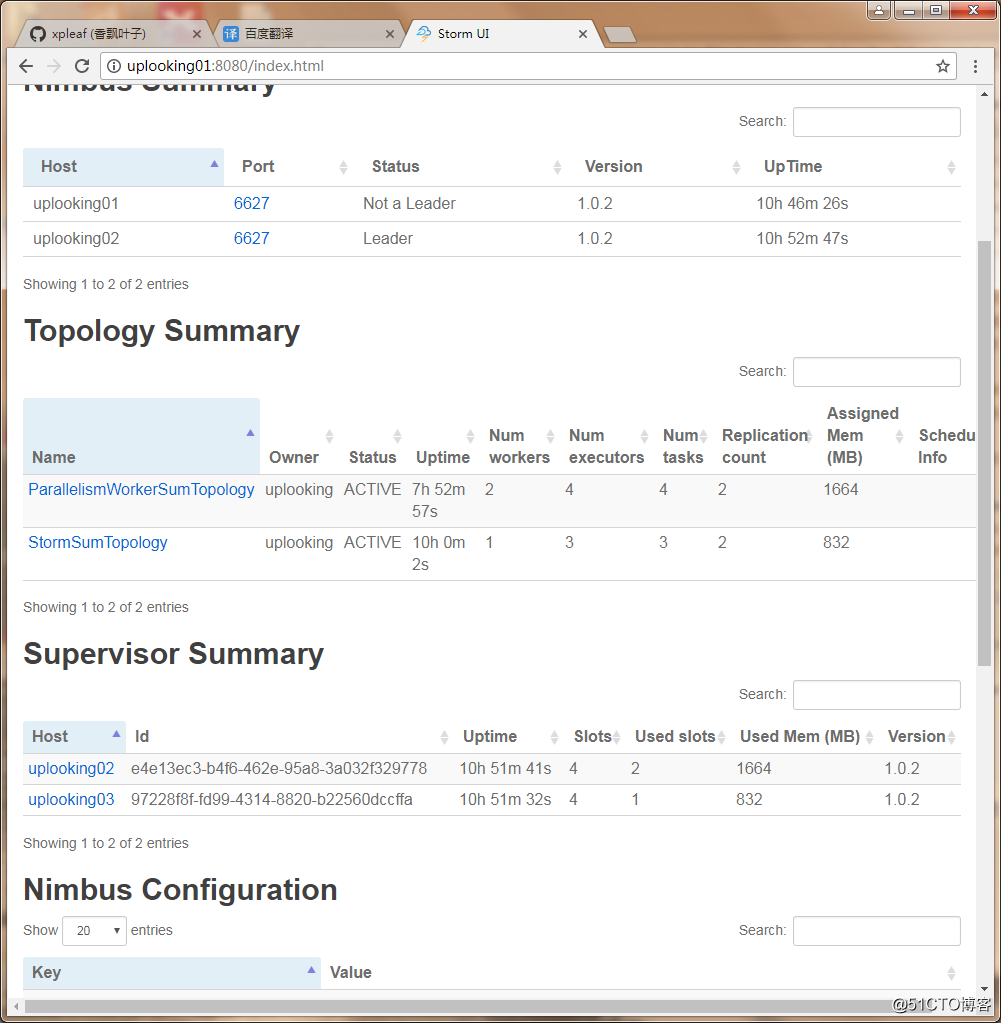
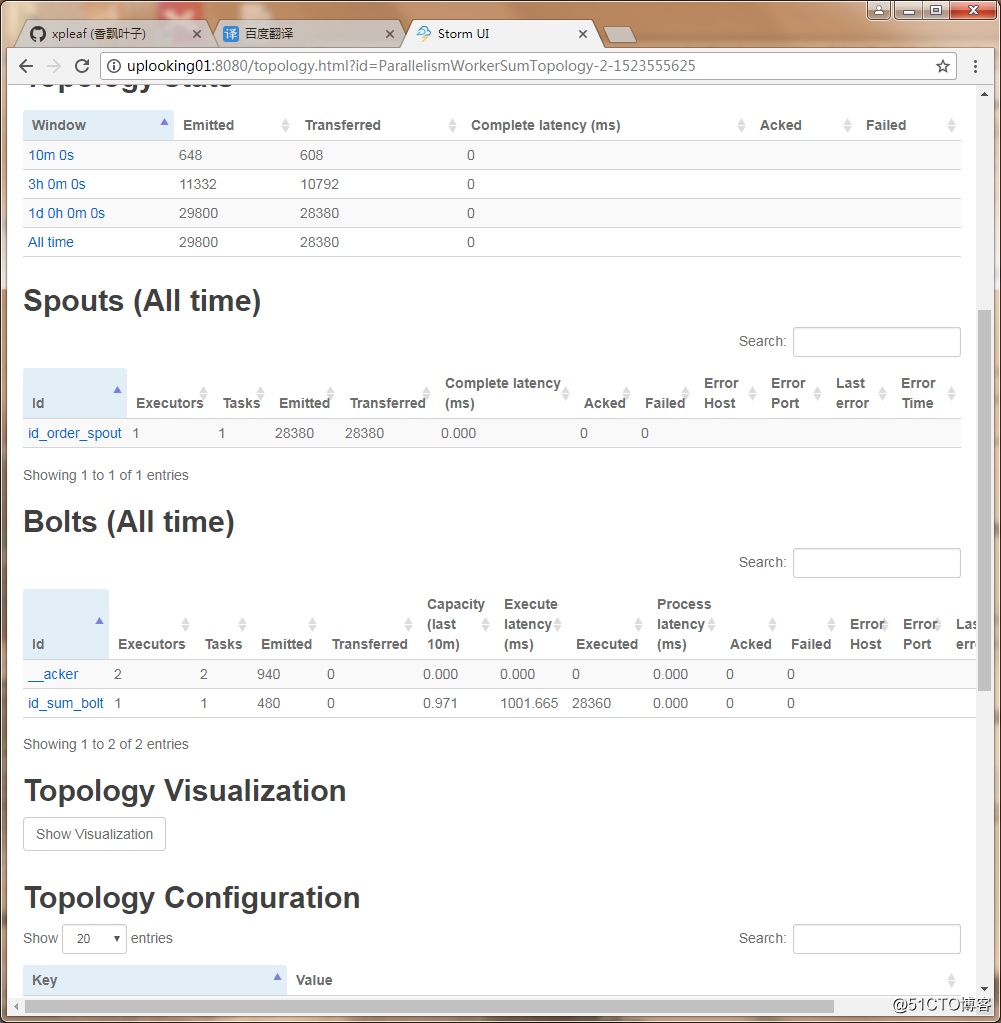
可以看到调整后,三者的数量情况为:
将worker进程修改为2个后:
executor线程数:4个
task任务数:4个
分析:
最简单的原因就是,我们的应用程序太小了,完全没有必要开启多个executor线程。
也就是说不会简单的进行worker的副本拷贝,这里多出来的一个executor线程是每一个worker进程都有的
一个默认的系统级别的bolt,就是__acker如果不希望系统级别的__acker运行,可以在代码中打开注释:
config.setNumAckers(0);即将其个数设置为0个,然后再上传到集群中运行即可。
并行度调整之executor线程个数
需要在设置spout和bolt时指定:
builder.setSpout("id_order_spout", new OrderSpout(), 2);
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件完整程序代码如下:
package cn.xpleaf.bigdata.storm.parallelism;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class ParallelismExecutorSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout(), 2);
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = ParallelismExecutorSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
/**
* 之前是1个worker进程 3个executor线程 3个task任务
* 3个executor,分别为:
* id_num_spout
* id_sum_bolt
* __acker
*
* 现在修改为:builder.setSpout("id_order_spout", new OrderSpout(), 2);
* builder.setBolt("id_sum_bolt", new SumBolt(), 3)
* 所以应该有6个executor,分别为:
* id_num_spout 2个
* id_sum_bolt 3个
* __acker 1个
* 同时task也为6个
*
*/
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}上传到集群中提交作业后,情况如下:
所以应该有6个executor,分别为:
id_num_spout 2个
id_sum_bolt 3个
__acker 1个
同时task也为6个另外,如果这时查看输出的log,会发现spout的输出,很多情况下都是一下子输出两条信息,因为此时有两个线程在运行,而bolt的情况也是类似的。
......
2018-04-13 10:22:30.406 STDIO [INFO] 当前时间20180413102230产生的订单金额:422
2018-04-13 10:22:30.517 STDIO [INFO] 当前时间20180413102230产生的订单金额:422
2018-04-13 10:22:30.519 STDIO [INFO] 商城网站到目前20180413102230的商品总交易额59013
2018-04-13 10:22:30.520 STDIO [INFO] 商城网站到目前20180413102230的商品总交易额55716
2018-04-13 10:22:31.407 STDIO [INFO] 当前时间20180413102231产生的订单金额:423
2018-04-13 10:22:31.411 STDIO [INFO] 商城网站到目前20180413102231的商品总交易额62936
2018-04-13 10:22:31.518 STDIO [INFO] 当前时间20180413102231产生的订单金额:423
2018-04-13 10:22:31.520 STDIO [INFO] 商城网站到目前20180413102231的商品总交易额59434
2018-04-13 10:22:32.408 STDIO [INFO] 当前时间20180413102232产生的订单金额:424
2018-04-13 10:22:32.411 STDIO [INFO] 商城网站到目前20180413102232的商品总交易额63360
2018-04-13 10:22:32.519 STDIO [INFO] 当前时间20180413102232产生的订单金额:424
2018-04-13 10:22:32.521 STDIO [INFO] 商城网站到目前20180413102232的商品总交易额59855
2018-04-13 10:22:32.523 STDIO [INFO] 商城网站到目前20180413102232的商品总交易额56140
2018-04-13 10:22:33.409 STDIO [INFO] 当前时间20180413102233产生的订单金额:425
2018-04-13 10:22:33.520 STDIO [INFO] 当前时间20180413102233产生的订单金额:425
2018-04-13 10:22:33.521 STDIO [INFO] 商城网站到目前20180413102233的商品总交易额60277
2018-04-13 10:22:33.523 STDIO [INFO] 商城网站到目前20180413102233的商品总交易额63785
2018-04-13 10:22:34.410 STDIO [INFO] 当前时间20180413102234产生的订单金额:426
2018-04-13 10:22:34.521 STDIO [INFO] 当前时间20180413102234产生的订单金额:426
2018-04-13 10:22:34.535 STDIO [INFO] 商城网站到目前20180413102234的商品总交易额60700
2018-04-13 10:22:34.535 STDIO [INFO] 商城网站到目前20180413102234的商品总交易额64211
2018-04-13 10:22:35.411 STDIO [INFO] 当前时间20180413102235产生的订单金额:427
2018-04-13 10:22:35.522 STDIO [INFO] 当前时间20180413102235产生的订单金额:427
......并行度调整之task任务个数
需要在设置spout和bolt时指定:
builder.setSpout("id_order_spout", new OrderSpout()).setNumTasks(2);
builder.setBolt("id_sum_bolt", new SumBolt()).setNumTasks(3)
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件完整程序代码如下:
package cn.xpleaf.bigdata.storm.parallelism;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class ParallelismTaskSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout()).setNumTasks(2);
builder.setBolt("id_sum_bolt", new SumBolt()).setNumTasks(3)
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = ParallelismTaskSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
/**
* 之前是1个worker进程 3个executor线程 3个task任务
* 3个executor,分别为:
* id_num_spout
* id_sum_bolt
* __acker
*
* 现在修改为:builder.setSpout("id_order_spout", new OrderSpout()).setNumTasks(2);
* builder.setBolt("id_sum_bolt", new SumBolt()).setNumTasks(3)
* 所以应该有3个executor,分别为:
* id_num_spout 1个
* id_sum_bolt 1个
* __acker 1个
* 同时task为6个:
* id_num_spout 2个
* id_sum_bolt 3个
* __acker 1个
*
*/
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}运行后,其情况如下:
所以应该有3个executor,分别为:
id_num_spout 1个
id_sum_bolt 1个
__acker 1个
同时task为6个:
id_num_spout 2个
id_sum_bolt 3个
__acker 1个并行度调整总结
-
Worker(slot)
- 默认一个从节点上面可以启动4个worker进程,参数是supervisor.slots.ports。在storm配置文件中已经配置过了,默认是在strom-core.jar包中的defaults.yaml中配置的有。
- 默认一个topology只使用一个worker进程,可以通过代码来设置使用多个worker进程。
- 通过config.setNumWorkers(workers)设置
- 通过conf.setNumAckers(0);可以取消acker任务(点击topology页面最下面的show system stats,可以显示系统级别的bolt,可以验证acker线程的存在)
- 最好一台机器上的一个topology只使用一个worker,主要原因是减少了worker之间的数据传输
- 如果worker使用完的话再提交topology就不会执行,会处于等待状态
注意:worker之间通信是通过Netty?进行通信的
- Executor
- 默认情况下一个executor运行一个task,可以通过在代码中设置
- builder.setSpout(id, spout, parallelism_hint);
- builder.setBolt(id, bolt, parallelism_hint);
- Task
- 通过boltDeclarer.setNumTasks(num);来设置实例的个数
- executor的数量会小于等于task的数量(为了rebalance)
并行度动态调整
- 通过UI调整
不推荐使用- 通过代码调整
topologyBuilder.setBolt("green-bolt", new GreenBolt(),2)
.setNumTasks(4).shuffleGrouping("blue-spout);- 通过shell调整
# 10秒之后开始调整
# Reconfigure the topology "mytopology" to use 5 worker processes,
# the spout "blue-spout" to use 3 executors and
# the bolt "yellow-bolt" to use 10 executors.
storm rebalance topologyName -w 10 -n 5 -e spout_id=3 -e id_bolt=10注意:acker数目运行时是不会变化的,所以多指定几个worker进程,acker线程数也不会增加。 -w:表示超时时间,rebalance首先会在一个超时时间内注销掉拓扑,然后在整个集群中重新分配 worker。
问题:
-e spout_id=3 -e id_bolt=10 有时不会增加并发度原因:
You can only increase the parallelism (number of executors) to the number of tasks. So if your
component is having for example (number of executors: 50, number of tasks: 50) then you can not
increase the parallelism, however you can decrease it.
就是说spout和bolt的并行数,最多可以调整到它的taskNum,默认情况下,taskNum是和你设置的paralismNum相同的。
#threads<=#tasks并行度设置参考
那么到底并行度设置多少合适呢,理论参考值:
- 单spout每秒大概可以发送500个tuple
- 单bolt每秒大概可以接收2000个tuple
- 单acker每秒大概可以接收6000个tuple
- 根据上面的指标可以根据当前业务的数据量对并行度进行动态调整。
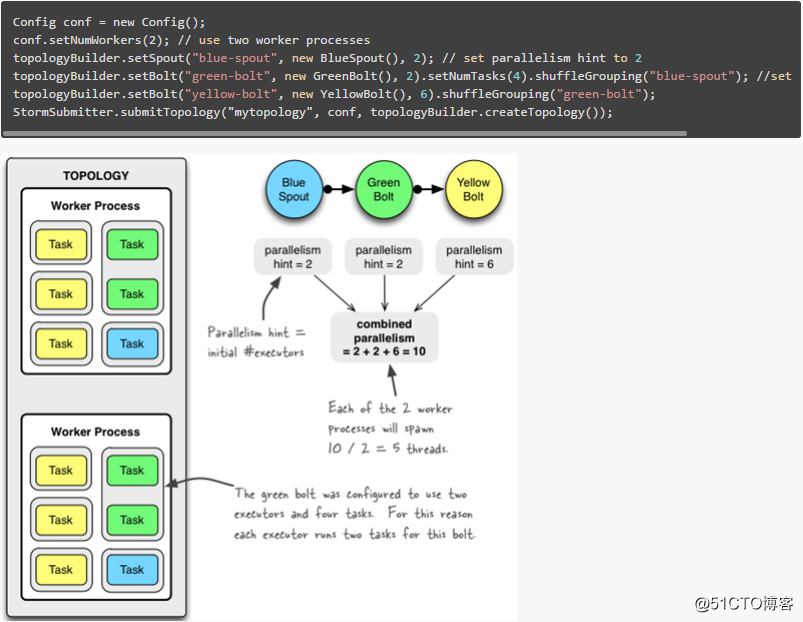
上面的案例对于分析storm的并行度会有非常大的帮助,同时也非常清晰地说明了worker、executor、task三者之间的关系。
Storm核心概念之流式分组(storm grouping)
假设storm集群现在有三个节点。一个作为nimbus,两个作为supervisor。到这里先介绍一下storm逻辑上有两个component,一个是Spout,另一个是Bolt。stream由Spout发出,在不同的Bolt之间进行处理,在其中传递的是storm的基本处理单位:Tuple。由Spout发出一个一个Tuple,然后Bolt接收Tuple进行各种各样的处理。这一整个过程构成一个DAG(有向无环图)。在storm里面叫做Topology。
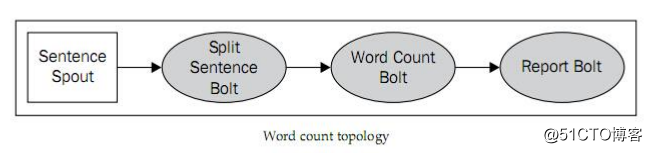
上图中spout的处理逻辑是将一句话发出给下一个Bolt,然后下一个Bolt做句子的单词分割,下一个做计数,最后的Bolt做汇总显示。这里可以有多个Bolt或者Spout进行并行处理。
那么这里有一个问题,数据是如何从spout到bolt中的呢,如果bolt是多个情况呢?这就是我们所说的流分组,也就是在Spout与Bolt、Bolt与Bolt之间传递Tuple的方式,我们称之为流分组storm grouping。
Storm Group分类
-
Shuffle Grouping
随机分组, 随机派发stream里面的tuple, 保证bolt中的每个任务接收到的tuple数目相同.(它能实现较好的负载均衡)
-
Fields Grouping
按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到同一任务, 而不同的userid则会被分配到不同的任务
-
All Grouping
广播发送,对于每一个tuple,Bolts中的所有任务都会收到.
-
Global Grouping
全局分组,这个tuple被分配到storm中的一个bolt的其中一个task.再具体一点就是分配给id值最低的那个task.
-
Non Grouping
随机分派,意思是说stream不关心到底谁会收到它的tuple.目前他和Shuffle grouping是一样的效果,
-
Direct Grouping
直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者具体由消息接收者的哪个task处理这个消息.只有被声明为Direct Stream的消息流可以声明这种分组方法.而且这种消息tuple必须使用emitDirect方法来发射.消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
-
localOrShuffleGrouping
是指如果目标Bolt 中的一个或者多个Task 和当前产生数据的Task 在同一个Worker 进程里面,那么就走内部的线程间通信,将Tuple 直接发给在当前Worker 进程的目的Task。否则,同shuffleGrouping。(在工作中使用的频率还是比较高的)
-
CustomStreamGrouping
自定义流式分组。
Storm流式分组之Shuffle Grouping
将计算总和的例子,spout并行度设置为1,bolt并行度设置为3,group方式设置为Shuffle Grouping,程序代码如下:
package cn.xpleaf.bigdata.storm.group;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class ShuffleGroupingSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("线程ID:" + Thread.currentThread().getId() + " ,商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = ShuffleGroupingSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}在集群中启动后,查看输出的日志信息:
......
2018-04-13 11:53:58.848 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413115358的商品总交易额31
2018-04-13 11:53:59.846 STDIO [INFO] 当前时间20180413115359产生的订单金额:14
2018-04-13 11:53:59.850 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413115359的商品总交易额30
2018-04-13 11:54:00.847 STDIO [INFO] 当前时间20180413115400产生的订单金额:15
2018-04-13 11:54:00.851 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413115400的商品总交易额45
2018-04-13 11:54:01.848 STDIO [INFO] 当前时间20180413115401产生的订单金额:16
2018-04-13 11:54:01.851 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413115401的商品总交易额60
2018-04-13 11:54:02.849 STDIO [INFO] 当前时间20180413115402产生的订单金额:17
2018-04-13 11:54:02.852 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413115402的商品总交易额62
2018-04-13 11:54:03.851 STDIO [INFO] 当前时间20180413115403产生的订单金额:18
2018-04-13 11:54:03.855 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413115403的商品总交易额78
2018-04-13 11:54:04.852 STDIO [INFO] 当前时间20180413115404产生的订单金额:19
2018-04-13 11:54:04.856 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413115404的商品总交易额50
2018-04-13 11:54:05.853 STDIO [INFO] 当前时间20180413115405产生的订单金额:20
2018-04-13 11:54:05.858 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413115405的商品总交易额70
2018-04-13 11:54:06.855 STDIO [INFO] 当前时间20180413115406产生的订单金额:21
......可以看到有bolt有3个线程在执行。
Storm流式分组之All Grouping
将计算总和的例子,spout并行度设置为1,bolt并行度设置为3,group方式设置为AllGrouping,程序代码如下:
package cn.xpleaf.bigdata.storm.group;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class AllGroupingSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("线程ID:" + Thread.currentThread().getId() + " ,商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.allGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = AllGroupingSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}上传到集群提交后,输出结果如下:
2018-04-13 12:42:36.992 STDIO [INFO] 当前时间20180413124236产生的订单金额:1
2018-04-13 12:42:36.998 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413124236的商品总交易额1
2018-04-13 12:42:36.999 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413124236的商品总交易额1
2018-04-13 12:42:37.000 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413124236的商品总交易额1
2018-04-13 12:42:37.995 STDIO [INFO] 当前时间20180413124237产生的订单金额:2
2018-04-13 12:42:37.999 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413124237的商品总交易额3
2018-04-13 12:42:38.000 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413124237的商品总交易额3
2018-04-13 12:42:38.000 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413124238的商品总交易额3
2018-04-13 12:42:38.996 STDIO [INFO] 当前时间20180413124238产生的订单金额:3
2018-04-13 12:42:39.000 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413124239的商品总交易额6
2018-04-13 12:42:39.000 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413124239的商品总交易额6
2018-04-13 12:42:39.001 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413124239的商品总交易额6
2018-04-13 12:42:39.998 STDIO [INFO] 当前时间20180413124239产生的订单金额:4
2018-04-13 12:42:40.001 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413124240的商品总交易额10
2018-04-13 12:42:40.002 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413124240的商品总交易额10
2018-04-13 12:42:40.002 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413124240的商品总交易额10
2018-04-13 12:42:40.999 STDIO [INFO] 当前时间20180413124240产生的订单金额:5
2018-04-13 12:42:41.002 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413124241的商品总交易额15
2018-04-13 12:42:41.003 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413124241的商品总交易额15
2018-04-13 12:42:41.003 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413124241的商品总交易额15
2018-04-13 12:42:42.000 STDIO [INFO] 当前时间20180413124242产生的订单金额:6
2018-04-13 12:42:42.004 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413124242的商品总交易额21
2018-04-13 12:42:42.004 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413124242的商品总交易额21
2018-04-13 12:42:42.004 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413124242的商品总交易额21
......可以看到有三个输出的bolt都同时收到了spout发送过来的tuple,这确实有点浪费资源。
注意,上面查看bolt的输出结果,这与多个线程只输出一份数据不一样,因为其三个输出都会同时输出相同的一份数据,而如果只是多个线程非AllGrouping的情况下,不会同一份数据输出多次的,这点尤其需要注意。
Storm流式分组之Global Grouping
将计算总和的例子,spout并行度设置为1,bolt并行度设置为3,group方式设置为GlobalGrouping,程序代码如下:
package cn.xpleaf.bigdata.storm.group;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*/
public class GlobalGroupingSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num));
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("线程ID:" + Thread.currentThread().getId() + " ,商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.globalGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = GlobalGroupingSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}打包上传到集群运行后,查看其输出结果如下:
2018-04-13 12:56:06.506 STDIO [INFO] 当前时间20180413125606产生的订单金额:1
2018-04-13 12:56:06.515 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125606的商品总交易额1
2018-04-13 12:56:07.512 STDIO [INFO] 当前时间20180413125607产生的订单金额:2
2018-04-13 12:56:07.516 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125607的商品总交易额3
2018-04-13 12:56:08.513 STDIO [INFO] 当前时间20180413125608产生的订单金额:3
2018-04-13 12:56:08.517 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125608的商品总交易额6
2018-04-13 12:56:09.515 STDIO [INFO] 当前时间20180413125609产生的订单金额:4
2018-04-13 12:56:09.519 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125609的商品总交易额10
2018-04-13 12:56:10.518 STDIO [INFO] 当前时间20180413125610产生的订单金额:5
2018-04-13 12:56:10.521 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125610的商品总交易额15
2018-04-13 12:56:11.519 STDIO [INFO] 当前时间20180413125611产生的订单金额:6
2018-04-13 12:56:11.523 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125611的商品总交易额21
2018-04-13 12:56:12.520 STDIO [INFO] 当前时间20180413125612产生的订单金额:7
2018-04-13 12:56:12.524 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125612的商品总交易额28
2018-04-13 12:56:13.521 STDIO [INFO] 当前时间20180413125613产生的订单金额:8
2018-04-13 12:56:13.525 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413125613的商品总交易额36
......可以看到这与AllGrouping完全不同,三个bolt的executor线程,但是却只有一个在执行操作。
通过前面三个流式分组方式的验证,可以非常清晰地了解其含义:
ShuffleGrouping:三个bolt线程,同时执行,但对于同一个tuple数据,只有一个bolt会接收到,并且是随机的。
AllGrouping:三个bolt线程,同时执行,但对于同一个tuple数据,3个bolt都会接收到。
GlobalGrouping:三个bolt线程,同时执行,但对于同一个tuple数据,只有固定一个bolt会接收到,其它2个bolt不会接收到。
Storm流式分组之Fields Grouping
在计算总和的例子上,再添加一个user_id的field,对其进行取模计算,同时在设置流式分组方式为根据user_id进行分组,并且为了验证其概念,设置bolt的并行度为3,这样理论上来说是,spout上产生的模为1 2 0的的userId的tuple会分别发送到三个不同线程ID的bolt上,后面我们只需要观察输出即可。
程序代码如下:
package cn.xpleaf.bigdata.storm.group;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*
* 流式分组之filedsGrouping,字段分组
* 有点像SQL中的group by
* 或者可以理解为hash取模分区
*/
public class FieldsGroupingSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
long userId = num % 3; // 0 1 2
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + ",用户-->" + userId + "<--产生的订单金额:" + num);
this.collector.emit(new Values(userId, num));
StormUtil.sleep(1000);
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("user_id", "order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long userId = input.getLongByField("user_id");
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("线程ID:" + Thread.currentThread().getId() + " ,商城网站到目前" +
StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "用户-->" + userId + "<--的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.fieldsGrouping("id_order_spout", new Fields("user_id")); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = FieldsGroupingSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}打包上传到集群并提交作业后,输出结果如下:
2018-04-13 15:53:37.836 STDIO [INFO] 当前时间20180413155337,用户-->1<--产生的订单金额:1
2018-04-13 15:53:37.843 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413155337用户-->1<--的商品总交易额1
2018-04-13 15:53:38.839 STDIO [INFO] 当前时间20180413155338,用户-->2<--产生的订单金额:2
2018-04-13 15:53:38.844 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413155338用户-->2<--的商品总交易额2
2018-04-13 15:53:39.841 STDIO [INFO] 当前时间20180413155339,用户-->0<--产生的订单金额:3
2018-04-13 15:53:39.845 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413155339用户-->0<--的商品总交易额3
2018-04-13 15:53:40.842 STDIO [INFO] 当前时间20180413155340,用户-->1<--产生的订单金额:4
2018-04-13 15:53:40.846 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413155340用户-->1<--的商品总交易额5
2018-04-13 15:53:41.844 STDIO [INFO] 当前时间20180413155341,用户-->2<--产生的订单金额:5
2018-04-13 15:53:41.850 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413155341用户-->2<--的商品总交易额7
2018-04-13 15:53:42.848 STDIO [INFO] 当前时间20180413155342,用户-->0<--产生的订单金额:6
2018-04-13 15:53:42.851 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413155342用户-->0<--的商品总交易额9
2018-04-13 15:53:43.849 STDIO [INFO] 当前时间20180413155343,用户-->1<--产生的订单金额:7
2018-04-13 15:53:43.852 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413155343用户-->1<--的商品总交易额12
2018-04-13 15:53:44.850 STDIO [INFO] 当前时间20180413155344,用户-->2<--产生的订单金额:8
2018-04-13 15:53:44.853 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413155344用户-->2<--的商品总交易额15
2018-04-13 15:53:45.852 STDIO [INFO] 当前时间20180413155345,用户-->0<--产生的订单金额:9
2018-04-13 15:53:45.855 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413155345用户-->0<--的商品总交易额18
2018-04-13 15:53:46.853 STDIO [INFO] 当前时间20180413155346,用户-->1<--产生的订单金额:10
2018-04-13 15:53:46.856 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413155346用户-->1<--的商品总交易额22
2018-04-13 15:53:47.854 STDIO [INFO] 当前时间20180413155347,用户-->2<--产生的订单金额:11
2018-04-13 15:53:47.859 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413155347用户-->2<--的商品总交易额26
2018-04-13 15:53:48.855 STDIO [INFO] 当前时间20180413155348,用户-->0<--产生的订单金额:12
2018-04-13 15:53:48.860 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413155348用户-->0<--的商品总交易额30
2018-04-13 15:53:49.857 STDIO [INFO] 当前时间20180413155349,用户-->1<--产生的订单金额:13
2018-04-13 15:53:49.860 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413155349用户-->1<--的商品总交易额35
2018-04-13 15:53:50.859 STDIO [INFO] 当前时间20180413155350,用户-->2<--产生的订单金额:14
2018-04-13 15:53:50.862 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413155350用户-->2<--的商品总交易额40
2018-04-13 15:53:51.860 STDIO [INFO] 当前时间20180413155351,用户-->0<--产生的订单金额:15
2018-04-13 15:53:51.863 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413155351用户-->0<--的商品总交易额45
2018-04-13 15:53:52.861 STDIO [INFO] 当前时间20180413155352,用户-->1<--产生的订单金额:16
2018-04-13 15:53:52.863 STDIO [INFO] 线程ID:45 ,商城网站到目前20180413155352用户-->1<--的商品总交易额51
2018-04-13 15:53:53.862 STDIO [INFO] 当前时间20180413155353,用户-->2<--产生的订单金额:17
2018-04-13 15:53:53.866 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413155353用户-->2<--的商品总交易额57
2018-04-13 15:53:54.863 STDIO [INFO] 当前时间20180413155354,用户-->0<--产生的订单金额:18
2018-04-13 15:53:54.867 STDIO [INFO] 线程ID:47 ,商城网站到目前20180413155354用户-->0<--的商品总交易额63
......那么结果就显而易见了,user_id模为1的tuple都发送到ID为45的线程上,user_id模为2的tuple都发送到ID为39的线程上,user_id模为0的tuple都发送到ID为47的线程上。
Storm流式分组之Custom Grouping
自定义流式分组,自定义的Custom Grouping如下:
/**
* 自定义的流式分组
* 模拟globalGrouping--->将所有的数据,传递到其中的一个task中
* 模拟fieldsGrouping(后面有时间自己可以实现这一个)
*/
class MyCustomStreamingGrouping implements CustomStreamGrouping {
private WorkerTopologyContext context;
private GlobalStreamId stream;
private List<Integer> targetTasks;
/**
* 类似自定义spout或bolt的初始化动作
* @param context
* @param stream
* @param targetTasks bolt对应的task的列表,如果我们在bolt.setNum(3)--->targetTasks的大小就是3
*/
@Override
public void prepare(WorkerTopologyContext context, GlobalStreamId stream, List<Integer> targetTasks) {
this.context = context;
this.stream = stream;
this.targetTasks = targetTasks;
System.out.println("bolt对应的task列表: " + targetTasks);
}
/**
*
* @param taskId
* @param values 就是tuple
* @return
*/
@Override
public List<Integer> chooseTasks(int taskId, List<Object> values) {
if(targetTasks.size() < 1) {
throw new RuntimeException("bolt的task个数居然为0,没有任务执行作业");
}
return Arrays.asList(targetTasks.get(0));
}
}其实这就是模拟Global Grouping的自定义流式分组,依然是计算总和的例子,其代码如下:
package cn.xpleaf.bigdata.storm.group;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.GlobalStreamId;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.grouping.CustomStreamGrouping;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.task.WorkerTopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.Map;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
*
* 流式分组之customGrouping,用户自定义分组
*/
public class CustomGroupingSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
long num = 0;
while (true) {
num++;
long userId = num % 3; // 0 1 2
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + ",用户-->" + userId + "<--产生的订单金额:" + num);
this.collector.emit(new Values(userId, num));
StormUtil.sleep(1000);
}
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("user_id", "order_cost"));
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long userId = input.getLongByField("user_id");
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
System.out.println("线程ID:" + Thread.currentThread().getId() + " ,商城网站到目前" +
StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "用户-->" + userId + "<--的商品总交易额" + sumOrderCost);
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt(), 3)
.customGrouping("id_order_spout", new MyCustomStreamingGrouping()); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = CustomGroupingSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}上传到集群并提交作业,其输出结果如下:
2018-04-13 16:21:23.919 STDIO [INFO] 当前时间20180413162123,用户-->1<--产生的订单金额:1
2018-04-13 16:21:23.924 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162123用户-->1<--的商品总交易额1
2018-04-13 16:21:24.922 STDIO [INFO] 当前时间20180413162124,用户-->2<--产生的订单金额:2
2018-04-13 16:21:24.926 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162124用户-->2<--的商品总交易额3
2018-04-13 16:21:25.923 STDIO [INFO] 当前时间20180413162125,用户-->0<--产生的订单金额:3
2018-04-13 16:21:25.926 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162125用户-->0<--的商品总交易额6
2018-04-13 16:21:26.925 STDIO [INFO] 当前时间20180413162126,用户-->1<--产生的订单金额:4
2018-04-13 16:21:26.928 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162126用户-->1<--的商品总交易额10
2018-04-13 16:21:27.926 STDIO [INFO] 当前时间20180413162127,用户-->2<--产生的订单金额:5
2018-04-13 16:21:27.930 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162127用户-->2<--的商品总交易额15
2018-04-13 16:21:28.928 STDIO [INFO] 当前时间20180413162128,用户-->0<--产生的订单金额:6
2018-04-13 16:21:28.931 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162128用户-->0<--的商品总交易额21
2018-04-13 16:21:29.929 STDIO [INFO] 当前时间20180413162129,用户-->1<--产生的订单金额:7
2018-04-13 16:21:29.932 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162129用户-->1<--的商品总交易额28
2018-04-13 16:21:30.930 STDIO [INFO] 当前时间20180413162130,用户-->2<--产生的订单金额:8
2018-04-13 16:21:30.934 STDIO [INFO] 线程ID:39 ,商城网站到目前20180413162130用户-->2<--的商品总交易额36
2018-04-13 16:21:31.932 STDIO [INFO] 当前时间20180413162131,用户-->0<--产生的订单金额:9
......可以看到只有一个executor接收到tuple数据,也就是说,通过使用自定义流式分组,确实实现了Global Grouping的功能。
以上是关于Storm笔记整理:Storm核心概念与验证——并行度与流式分组的主要内容,如果未能解决你的问题,请参考以下文章
Storm笔记整理:Storm集群安装部署与Topology作业提交