Storm笔记整理:可靠性分析定时任务与Storm UI参数详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm笔记整理:可靠性分析定时任务与Storm UI参数详解相关的知识,希望对你有一定的参考价值。
[TOC]
特别说明:前面的四篇Storm笔记中,关于计算总和的例子中的spout,使用了死循环的逻辑,实际上这样做是不正确的,原因很简单,Storm提供给我们的API中,nextTuple方法就是循环执行了,这相当于是做了双层循环。因为后面在做可靠性acker案例分析时发现,加入死循环逻辑后,该nextTuple所属于的那个task根本就没有办法跳出这个nextTuple方法,也就没有办法执行后面的ack或者是fail方法,这点尤其需要注意。
Storm可靠性分析
基本原理
-
worker进程死掉
worker进程挂掉,storm集群会在重新启动一个worker进程。
-
supervisor进程死掉
supervisor进程挂掉,不会影响之前已经提交的topology,只是后期不能向这个节点分配任务,因为这个节点已经不是集群的一员了。
-
nimbus进程死掉(存在HA的问题)快速失败
nimbus进程挂掉,也不会影响之前已经提交的topology,只是后期不能向集群再提交新的topology了。1.0以下的版本存在HA的问题,1.0之后已经修复了这个问题,可以有多个备选nimbus。
-
节点宕机
-
ack/fail消息确认机制(确保一个tuple被完全处理)
- 在spout中发射tuple的时候需要同时发送messageid,这样才相当于开启了消息确认机制
- 如果你的topology里面的tuple比较多的话, 那么把acker的数量设置多一点,效率会高一点。
- 通过config.setNumAckers(num)来设置一个topology里面的acker的数量,默认值是1。
- 注意: acker用了特殊的算法,使得对于追踪每个spout tuple的状态所需要的内存量是恒定的(20 bytes) (可以了解一下其算法,目前暂时不做这个算法的深入理解,百度storm acker就能找到相关的分析文章)
- 注意:如果一个tuple在指定的timeout(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS默认值为30秒)时间内没有被成功处理,那么这个tuple会被认为处理失败了。
-
完全处理tuple
在storm里面一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所衍生的所有的tuple都被成功处理。
可靠性acker案例
前面也提到了,如果希望使用qck/fail确认机制,则需要做下面的事情:
1.在我们的spout中重写ack和fail方法
2.spout发送tuple时需要携带messageId
3.bolt成功或失败处理后要主动进行回调根据上面的说明,程序代码如下,注意其中体现的这几点:
package cn.xpleaf.bigdata.storm.acker;
import cn.xpleaf.bigdata.storm.utils.StormUtil;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Date;
import java.util.Map;
import java.util.UUID;
/**
* 1°、实现数字累加求和的案例:数据源不断产生递增数字,对产生的数字累加求和。
* <p>
* Storm组件:Spout、Bolt、数据是Tuple,使用main中的Topology将spout和bolt进行关联
* MapReduce的组件:Mapper和Reducer、数据是Writable,通过一个main中的job将二者关联
* <p>
* 适配器模式(Adapter):BaseRichSpout,其对继承接口中一些没必要的方法进行了重写,但其重写的代码没有实现任何功能。
* 我们称这为适配器模式
* <p>
* storm消息确认机制---可靠性分析
* acker
* fail
*/
public class AckerSumTopology {
/**
* 数据源
*/
static class OrderSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private long num = 0;
/**
* 接收数据的核心方法
*/
@Override
public void nextTuple() {
String messageId = UUID.randomUUID().toString().replaceAll("-", "").toLowerCase();
// while (true) {
num++;
StormUtil.sleep(1000);
System.out.println("当前时间" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "产生的订单金额:" + num);
this.collector.emit(new Values(num), messageId);
// }
}
/**
* 是对发送出去的数据的描述schema
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("order_cost"));
}
@Override
public void ack(Object msgId) {
System.out.println(msgId + "对应的消息被处理成功了");
}
@Override
public void fail(Object msgId) {
System.out.println(msgId + "---->对应的消息被处理失败了");
}
}
/**
* 计算和的Bolt节点
*/
static class SumBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Long sumOrderCost = 0L;
/**
* 处理数据的核心方法
*/
@Override
public void execute(Tuple input) {
Long orderCost = input.getLongByField("order_cost");
sumOrderCost += orderCost;
if (orderCost % 10 == 1) { // 每10次模拟消息失败一次
collector.fail(input);
} else {
System.out.println("线程ID:" + Thread.currentThread().getId() + " ,商城网站到目前" + StormUtil.df_yyyyMMddHHmmss.format(new Date()) + "的商品总交易额" + sumOrderCost);
collector.ack(input);
}
StormUtil.sleep(1000);
}
/**
* 如果当前bolt为最后一个处理单元,该方法可以不用管
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,相当于在MapReduce中构建Job
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
builder.setSpout("id_order_spout", new OrderSpout());
builder.setBolt("id_sum_bolt", new SumBolt(), 1)
.shuffleGrouping("id_order_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = AckerSumTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
}运行后(本地运行或上传到集群上提交作业),输出如下:
当前时间20180413215706产生的订单金额:1
当前时间20180413215707产生的订单金额:2
7a4ce596fd3a40659f2d7f80a7738f55---->对应的消息被处理失败了
线程ID:133 ,商城网站到目前20180413215707的商品总交易额3
当前时间20180413215708产生的订单金额:3
0555a933a49f413e94480be201a55615对应的消息被处理成功了
线程ID:133 ,商城网站到目前20180413215708的商品总交易额6
当前时间20180413215709产生的订单金额:4
4b923132e4034e939c875aca368a8897对应的消息被处理成功了
线程ID:133 ,商城网站到目前20180413215709的商品总交易额10
当前时间20180413215710产生的订单金额:5
51f159472e854ba282ab84a2218459b8对应的消息被处理成功了
线程ID:133 ,商城网站到目前20180413215710的商品总交易额15
......Storm定时任务
一般的业务数据存储,最终还是要落地,存储到RDBMS,但是RDBMS无法达到高访问量,能力达不到实时处理,或者说处理能力是有限的,会造成连接中断等问题,为了数据落地,我们可以采取迂回方式,可以采用比如说先缓存到高速内存数据库(如redis),然后再将内存数据库中的数据定时同步到rdbms中,而且可以定期定时来做。
- 可以每隔指定的时间将数据整合一次存入数据库。
- 或者每隔指定的时间执行一些
可以在storm中使用定时任务来实现这些定时数据落地的功能,不过需要先了解storm定时任务。
全局定时任务
在main中设置
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 60); // 设置多久发送一个系统的tuple定时发射数据但是我们一般都会对特定的bolt设置定时任务,而没有必要对全局每一个bolt都发送系统的tuple,这样非常的耗费资源,所以就有了局部定时任务,也是我们常用的。
注意:storm会按照用户设置的时间间隔给拓扑中的所有bolt发送系统级别的tuple。在main函数中设置定时器,storm会定时给拓扑中的所有bolt都发送系统级别的tuple,如果只需要给某一个bolt设置定时功能的话,只需要在这个bolt中覆盖getComponentConfiguration方法,里面设置定时间隔即可。
测试代码如下:
package cn.xpleaf.bigdata.storm.quartz;
import org.apache.storm.Config;
import org.apache.storm.Constants;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.shade.org.apache.commons.io.FileUtils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.io.File;
import java.io.IOException;
import java.util.*;
/**
* 2°、单词计数:监控一个目录下的文件,当发现有新文件的时候,
把文件读取过来,解析文件中的内容,统计单词出现的总次数
E:\data\storm
研究storm的定时任务
有两种方式:
1.main中设置,全局有效
2.在特定bolt中设置,bolt中有效
*/
public class QuartzWordCountTopology {
/**
* Spout,获取数据源,这里是持续读取某一目录下的文件,并将每一行输出到下一个Bolt中
*/
static class FileSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
File directory = new File("D:/data/storm");
// 第二个参数extensions的意思就是,只采集某些后缀名的文件
Collection<File> files = FileUtils.listFiles(directory, new String[]{"txt"}, true);
for (File file : files) {
try {
List<String> lines = FileUtils.readLines(file, "utf-8");
for(String line : lines) {
this.collector.emit(new Values(line));
}
// 当前文件被消费之后,需要重命名,同时为了防止相同文件的加入,重命名后的文件加了一个随机的UUID,或者加入时间戳也可以的
File destFile = new File(file.getAbsolutePath() + "_" + UUID.randomUUID().toString() + ".completed");
FileUtils.moveFile(file, destFile);
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
/**
* Bolt节点,将接收到的每一行数据切割为一个个单词并发送到下一个节点
*/
static class SplitBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
@Override
public void execute(Tuple input) {
if (!input.getSourceComponent().equalsIgnoreCase(Constants.SYSTEM_COMPONENT_ID) ) { // 确保不是系统发送的tuple,才使用我们的业务逻辑
String line = input.getStringByField("line");
String[] words = line.split(" ");
for (String word : words) {
this.collector.emit(new Values(word, 1));
}
} else {
System.out.println("splitBolt: " + input.getSourceComponent().toString());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
/**
* Bolt节点,执行单词统计计算
*/
static class WCBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Map<String, Integer> map = new HashMap<>();
@Override
public void execute(Tuple input) {
if (!input.getSourceComponent().equalsIgnoreCase(Constants.SYSTEM_COMPONENT_ID) ) { // 确保不是系统发送的tuple,才使用我们的业务逻辑
String word = input.getStringByField("word");
Integer count = input.getIntegerByField("count");
/*if (map.containsKey(word)) {
map.put(word, map.get(word) + 1);
} else {
map.put(word, 1);
}*/
map.put(word, map.getOrDefault(word, 0) + 1);
System.out.println("====================================");
map.forEach((k, v) -> {
System.out.println(k + ":::" + v);
});
} else {
System.out.println("sumBolt: " + input.getSourceComponent().toString());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,组装Spout和Bolt节点,相当于在MapReduce中构建Job
*/
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
// dag
builder.setSpout("id_file_spout", new FileSpout());
builder.setBolt("id_split_bolt", new SplitBolt()).shuffleGrouping("id_file_spout");
builder.setBolt("id_wc_bolt", new WCBolt()).shuffleGrouping("id_split_bolt");
StormTopology stormTopology = builder.createTopology();
LocalCluster cluster = new LocalCluster();
String topologyName = QuartzWordCountTopology.class.getSimpleName();
Config config = new Config();
config.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 10);
cluster.submitTopology(topologyName, config, stormTopology);
}
}输出:
splitBolt: __system
sumBolt: __system
splitBolt: __system
sumBolt: __system
......局部定时任务
在bolt中使用下面代码判断是否是触发用的bolt
tuple.getSourceComponent().equals(Constants.SYSTEM_COMPONENT_ID)如果为true,则执行定时任务需要执行的代码,最后return,如果为false,则执行正常的tuple处理的业务逻辑。
即对于需要进行数据落地的bolt,我们可以只给该bolt设置定时任务,这样系统会定时给该bolt发送系统级别的tuple,在我们该bolt的代码中进行判断,如果接收到的是系统级别的bolt,则进行数据落地的操作,比如将数据写入数据库或其它操作等,否则就按照正常的逻辑来执行我们的业务代码。
工作中常用这一种方式进行操作。
测试程序如下:
package cn.xpleaf.bigdata.storm.quartz;
import clojure.lang.Obj;
import org.apache.storm.Config;
import org.apache.storm.Constants;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.shade.org.apache.commons.io.FileUtils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.io.File;
import java.io.IOException;
import java.util.*;
/**
* 2°、单词计数:监控一个目录下的文件,当发现有新文件的时候,
把文件读取过来,解析文件中的内容,统计单词出现的总次数
E:\data\storm
研究storm的定时任务
有两种方式:
1.main中设置,全局有效
2.在特定bolt中设置,bolt中有效
*/
public class QuartzPartWCTopology {
/**
* Spout,获取数据源,这里是持续读取某一目录下的文件,并将每一行输出到下一个Bolt中
*/
static class FileSpout extends BaseRichSpout {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private SpoutOutputCollector collector; // 发送tuple的组件
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
File directory = new File("D:/data/storm");
// 第二个参数extensions的意思就是,只采集某些后缀名的文件
Collection<File> files = FileUtils.listFiles(directory, new String[]{"txt"}, true);
for (File file : files) {
try {
List<String> lines = FileUtils.readLines(file, "utf-8");
for(String line : lines) {
this.collector.emit(new Values(line));
}
// 当前文件被消费之后,需要重命名,同时为了防止相同文件的加入,重命名后的文件加了一个随机的UUID,或者加入时间戳也可以的
File destFile = new File(file.getAbsolutePath() + "_" + UUID.randomUUID().toString() + ".completed");
FileUtils.moveFile(file, destFile);
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
/**
* Bolt节点,将接收到的每一行数据切割为一个个单词并发送到下一个节点
*/
static class SplitBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split(" ");
for (String word : words) {
this.collector.emit(new Values(word, 1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
/**
* Bolt节点,执行单词统计计算
*/
static class WCBolt extends BaseRichBolt {
private Map conf; // 当前组件配置信息
private TopologyContext context; // 当前组件上下文对象
private OutputCollector collector; // 发送tuple的组件
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Map<String, Integer> map = new HashMap<>();
@Override
public void execute(Tuple input) {
if (!input.getSourceComponent().equalsIgnoreCase(Constants.SYSTEM_COMPONENT_ID) ) { // 确保不是系统发送的tuple,才使用我们的业务逻辑
String word = input.getStringByField("word");
Integer count = input.getIntegerByField("count");
/*if (map.containsKey(word)) {
map.put(word, map.get(word) + 1);
} else {
map.put(word, 1);
}*/
map.put(word, map.getOrDefault(word, 0) + 1);
System.out.println("====================================");
map.forEach((k, v) -> {
System.out.println(k + ":::" + v);
});
} else {
System.out.println("sumBolt: " + input.getSourceComponent().toString() + "---" + System.currentTimeMillis());
}
}
@Override
public Map<String, Object> getComponentConfiguration() { // 修改局部bolt的配置信息
Map<String, Object> config = new HashMap<>();
config.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 10);
return config;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
/**
* 构建拓扑,组装Spout和Bolt节点,相当于在MapReduce中构建Job
*/
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
// dag
builder.setSpout("id_file_spout", new FileSpout());
builder.setBolt("id_split_bolt", new SplitBolt()).shuffleGrouping("id_file_spout");
builder.setBolt("id_wc_bolt", new WCBolt()).shuffleGrouping("id_split_bolt");
StormTopology stormTopology = builder.createTopology();
LocalCluster cluster = new LocalCluster();
String topologyName = QuartzPartWCTopology.class.getSimpleName();
Config config = new Config();
cluster.submitTopology(topologyName, config, stormTopology);
}
}输出如下:
sumBolt: __system---1523631954330
sumBolt: __system---1523631964330
sumBolt: __system---1523631974329
sumBolt: __system---1523631984329
sumBolt: __system---1523631994330
sumBolt: __system---1523632004330
sumBolt: __system---1523632014329
sumBolt: __system---1523632024330
......Storm UI参数介绍
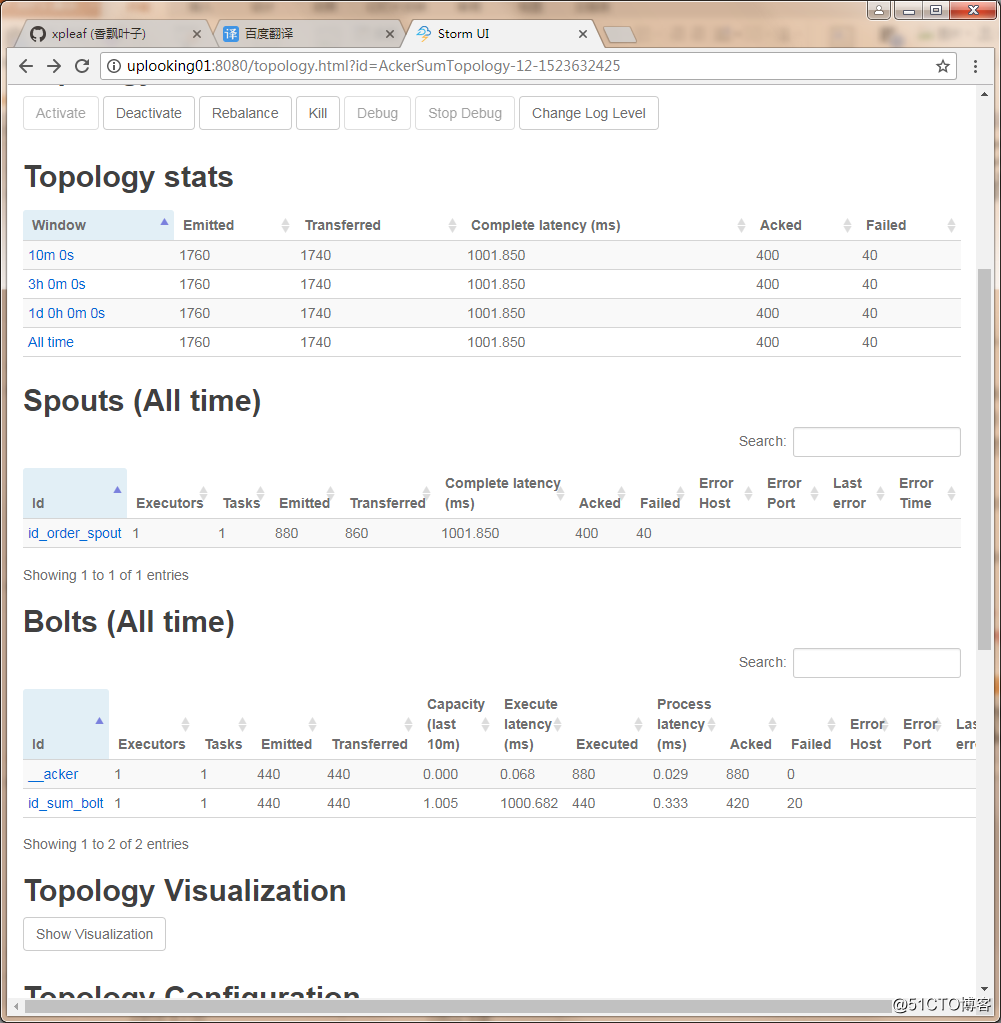
-
deactive:未激活(暂停)
-
emitted: emitted tuple数
-
transferred: transferred tuple数
emitted的区别:如果一个task,emitted一个tuple到2个task中,则 transferred tuple数是emitted tuple数的两倍
-
complete latency: spout emitting 一个tuple到spout ack这个tuple的平均时间(可以认为是tuple以及该tuple树的整个处理时间)
-
process latency: bolt收到一个tuple到bolt ack这个tuple的平均时间,如果没有启动acker机制,那么值为0
-
execute latency:bolt处理一个tuple的平均时间,不包含acker操作,单位是毫秒(也就是bolt 执行 execute 方法的平均时间)
- capacity:这个值越接近1,说明bolt或者spout基本一直在调用execute方法,说明并行度不够,需要扩展这个组件的executor数量。
总结:execute latency和proces latnecy是处理消息的时效性,而capacity则表示处理能力是否已经饱和,从这3个参数可以知道topology的瓶颈所在。
以上是关于Storm笔记整理:可靠性分析定时任务与Storm UI参数详解的主要内容,如果未能解决你的问题,请参考以下文章
Storm笔记整理:Storm本地开发案例—总和计算与单词统计
Storm笔记整理:Storm集群安装部署与Topology作业提交