Storm笔记整理:简介与设计思想
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm笔记整理:简介与设计思想相关的知识,希望对你有一定的参考价值。
[TOC]
实时计算概述
有别于传统的离线批处理操作(对很多数据的集合进行的操作),实时处理,说白就是针对一条一条的数据/记录进行操作,所有的这些操作进行一个汇总(截止到目前为止的所有的统计总和)。
实时计算与离线计算比较
Bounded:有界
离线计算面临的操作数据都是有界限的,无论是1G、1T、1P、1EB、1NB
数据的有界必然会导致计算的有界
UnBounded:无界
实时计算面临的操作数据是源源不断的向水流一样,是没有界限的,
数据的无界必然导致计算的无界来自Flink官网的说明:
First, 2 types of datasets
Unbounded: Infinite datasets that are appended to continuously
Bounded: Finite, unchanging datasets
Second, 2 types of execution models
Streaming: Processing that executes continuously as long as data is being produced
Batch: Processing that is executed and runs to completeness in a finite amount of
time, releasing computing resources when finished大数据处理的6大问题
3大计算中心
离线批处理
准实时流计算中心
实时流计算
3大计算引擎
用户交互式计算引擎:SQL/ES
图计算引擎
机器学习计算引擎Storm简介
ApacheStorm是Twitter开源的一个类似于Hadoop的实时数据处理框架,它原来是由BackType开发,后BackType被Twitter收购,将Storm作为Twitter的实时数据分析系统。
Storm能实现高频数据和大规模数据的实时处理。
官网资料显示storm的一个节点1秒钟能够处理100万个100字节的消息([email protected]的CPU,24GB的内存)。(即单节点每秒大概处理95MB左右数据)
Storm和Hadoop比较
-
数据来源
HADOOP处理的是HDFS上TB级别的数据(历史数据),STORM是处理的是实时新增的某一笔数据(实时数据);
-
处理过程
HADOOP是分MAP阶段到REDUCE阶段,STORM是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(SPOUT)或处理逻辑(BOLT);
-
是否结束
HADOOP最后是要结束的,STORM是没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始;
-
处理速度
HADOOP是以处理HDFS上TB级别数据为目的,处理速度慢,STORM是只要处理新增的某一笔数据即可,可以做到很快;
-
适用场景
HADOOP是在要处理批量数据时用的,不讲究时效性,STORM是要处理某一新增数据时用的,要讲时效性。
Storm的设计思想
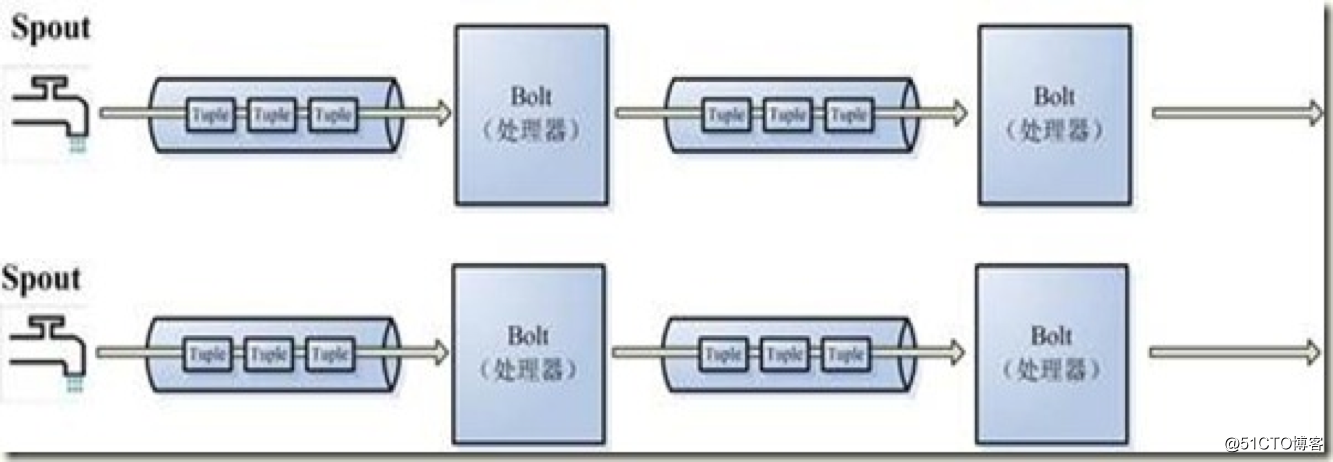
Storm是对流Stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组。
? Storm将流中元素抽象为Tuple,一个tuple就是一个值列表——valuelist,list中的每个value都有一个name,并且该value可以是基本类型,字符类型,字节数组等,当然也可以是其他可序列化的类型。
Storm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头称为Spout。
有了源头即spout也就是有了stream,那么该如何处理stream内的tuple呢。将流的状态转换称为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout(管口)再将spout中流出的tuple导向特定的bolt,又bolt对导入的流做处理后再导向其他bolt或者目的地。
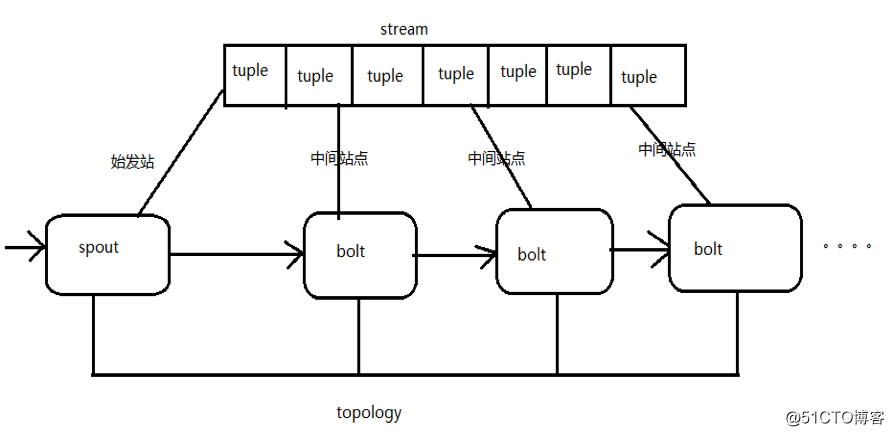
以上处理过程统称为Topology即拓扑。拓扑是storm中最高层次的一个抽象概念,它可以被提交到storm集群执行,一个拓扑就是一个流转换图,图中每个节点是一个spout或者bolt,图中的边表示bolt订阅了哪些流,当spout或者bolt发送元组到流时,它就发送元组到每个订阅了该流的bolt(这就意味着不需要我们手工拉管道,只要预先订阅,spout就会将流发到适当bolt上)。
拓扑的每个节点都要说明它所发出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
以上是关于Storm笔记整理:简介与设计思想的主要内容,如果未能解决你的问题,请参考以下文章
Storm笔记整理:Storm集群安装部署与Topology作业提交
Storm笔记整理:Storm核心概念与验证——并行度与流式分组