storm应用实践:实时事务处理《读书笔记》
Posted tangsilian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm应用实践:实时事务处理《读书笔记》相关的知识,希望对你有一定的参考价值。
文章目录
阅读目的:
地址:https://weread.qq.com/web/reader/b06327c0717cc12cb06c27ek9bf32f301f9bf31c7ff0a60
阅读本书的前四章,了解storm常见的应用场景和实际案例。
第1章介绍大数据和Storm在大数据中所处的地位,该章的目的是展示一个选择Storm的理由和时机,一些关于大数据应用的关键特性,各类用于处理大数据的工具,以及明确Storm的工具类型。
第2章借助一个对某GitHub库提交数的统计案例,解释Storm的核心概念。该章将建立学习Storm的相关术语基础,尝试一小段代码来学习建立Storm工程,而这个案例中的概念也将贯穿本书。
第3章讲解在Storm下设计拓扑结构的最佳实践,同时以一个社交热力图的应用为例,展示了如何将问题基于Storm的结构来做分解,以便适用于程序的上下文实现部署。该章还讨论了如何处理不稳定的数据源,或者是不可靠的外部服务。同时在该章中介绍的首字节并行性,也将成为后续章节中的重点,最后在该章中还深入讨论了高级拓扑设计范式。
第4章以一个信用卡的授权系统为例,探讨Storm如何确保消息以上下文的形式传输,阐述Storm的实现机制,并且如何基于一套方案的部署,提供不同层面的可靠性支持。同时该章在最后做一个总结,说明如何在Storm的拓扑结构上,实现这种不同层次的可靠性支持。
第1章 Storm简介:
Storm是什么
大数据的定义
大数据工具
Storm如何应用于大数据场景
选择Storm的理由
Apache Storm是一个分布式实时计算框架,适用于处理无边界的流数据。将Storm与你当前使用的队列和持久化技术相结合,就能实现多种处理和转换流数据的方式。
1.1 什么是大数据
1.1.1 大数据的四大特性大数据有四个公认的特性:
体量(Volume)、速度(Velocity)、多样性(Variety)和真实性(Veracity)。
1.1.2 大数据工具
数据处理:这些工具主要用于基于指定的计算方式,让数据集释放出有价值的信息。
数据传输:这些工具主要用于将数据收集并提取至数据处理系统,或者在不同组件之间执行数据的传输。数据格式可以不限,但最终它们都会共用一套消息总线(或者称之为消息队列),例如Kafka、Flume、Scribe和Scoop。
数据存储:这些工具主要用于在不同阶段的数据处理期间,为数据集提供存储服务,它们可以是分布式的文件系统,例如分布式文件系统HDFS(Hadoop Distributed File System)或者GlusterFS以及Cassandra这类NoSQL结构的数据库。
数据处理分为批处理和流处理:
批处理:允许你对数据按照不同维度执行连接、合并或者聚合操作,这也是为什么批处理模式目前被广泛应用于机器学习的算法上。
流处理:实现立即输出结果,系统会依次对单点的简单数据执行处理。海量数据按照流的方式输入。
1.2 Storm如何应用于大数据应用场景
Storm是一个分布式实时计算框架,适用于处理无边界的流数据。
将Storm与你当前使用的队列和持久化技术相结合,就能实现多种处理和转换流数据的方式。
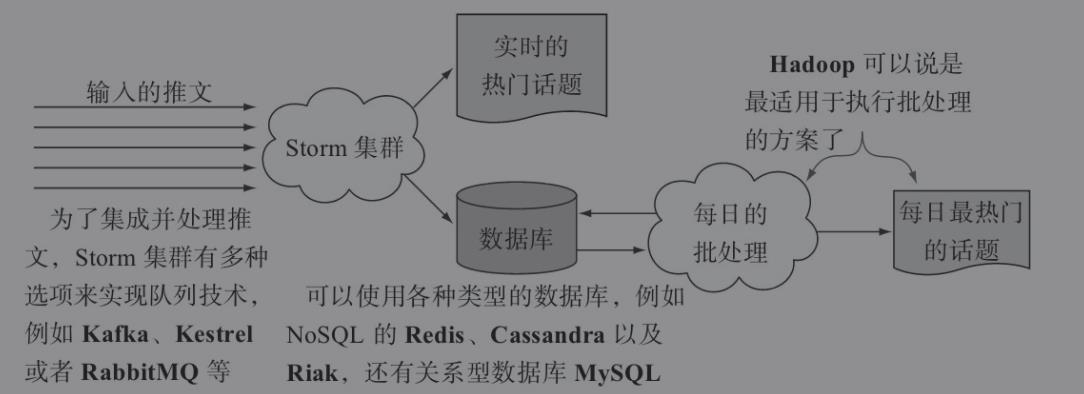
Storm与其他常用工具之间的对比:
Hadoop
在过去基本上是批处理系统的代名词,随着Hadoop的第二代版本发布,它不仅在系统层面更加完善,还可以说是逐渐成为一个具备大数据处理能力的应用平台。它的批处理组件称为Hadoop MapReduce,作业调度器和集群资源管理器的组件叫做YARN,分布式文件系统叫HDFS。

无论Hadoop如何将代码在数据上执行移动运算,Storm做的是将数据指向代码。这在流数据处理的系统中显得更为合理,
Apache Spark
和Hadoop的MapReduce类似,Spark是一个类似的批处理工具,也能运行在Hadoop的YARN资源管理器之上。有意思的一点就是,Spark允许你在中间或是结尾处,将数据缓存至内存中(有必要也可以将输出保存到磁盘上)。这种特性最有价值的一点,就是特别适用于在一个相同的数据集上反复执行运算,并且能将上一次运算按照一定算法保留,作为下一次运算的输入。
Spark Streaming和Storm类似,Spark Streaming用于处理无边界的流数据,但不同点在于,SparkStreaming不会将数据按照类别导入到流处理工具中,取而代之的是将其导入到微型批处理工具中。Spark Streaming是建立在Spark之上的,它需要将输入的流数据标记成一个个数据批次,以便执行操作。
Apache Samza
Samza是一个新兴的流数据处理系统,是由LinkedIn(领英)团队打造,效果完全和Storm不相上下。但你依然会发现一些区别,这里无论是Storm还是Spark或者Spark Streaming,它们都运行在基于YARN的资源管理器上,而Samza则是与YARN系统分开独立运行的。
1.3 为什么你希望使用Storm
[插图]它可以广泛用于各类用户场景中。
[插图]它可以和不同技术协同工作。
[插图]它具备可扩展性,Storm可以轻松将工作分解至不同线程上,并分派至不同JVM(Java虚拟机)上,甚至是不同的物理机上,而这些还不需要在你的代码上做任何调整(只需要修改配置就可以了)。
[插图]它可以确保每个输入的数据至少会被处理一次。
[插图]它相当健壮,你也可以称之为高容错性。Storm中有四个主要的组件,在大部分时间里,摧毁任何一个组件都不会中断数据的处理。
[插图]它与使用的编程语言无关,如果你的程序能在JVM上执行,它就可以在Storm上轻松执行。即使没法在JVM上执行,如果你能在一个*nix命令行中调用它,它也可以在Storm上正常运行(尽管在本书中,我们将限定于使用JVM和Java)。
第2章 Storm核心概念
难理解执行器(executor)和任务(task)
2.1 计算github提交监控看盘
2.2 Storm基础概念
2.2.1 拓扑图
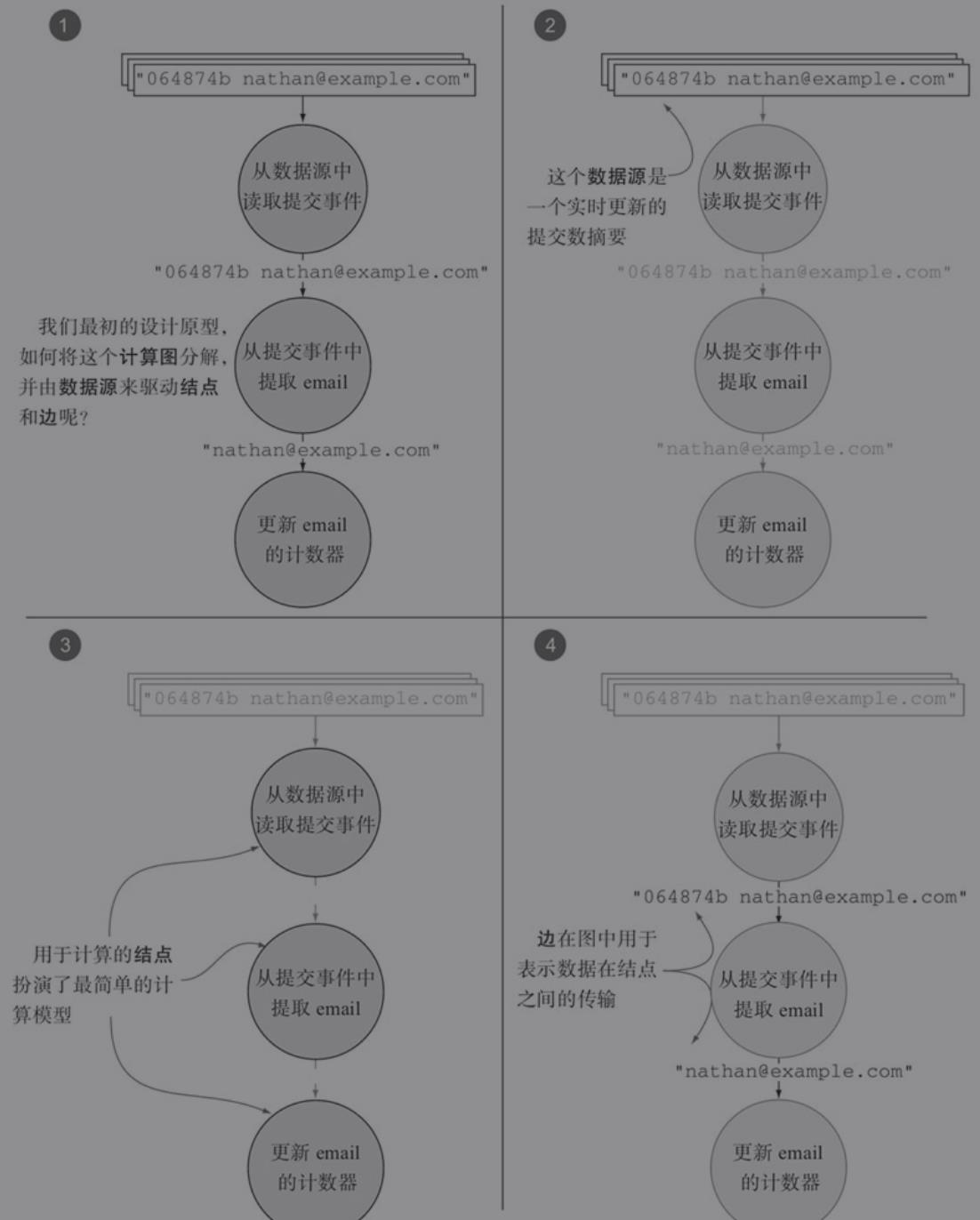
2.2.2 元组
元组(tuple)是拓扑中结点之间传输数据的形式,它本身是一个有序的数值序列,其中每个数值都会被赋予一个命名。一个结点可以创建元组,然后发送(可选)至任意其他结点,这个发送元组到任意结点的过程,称作发射(emit)一个元组。
2.2.3 流
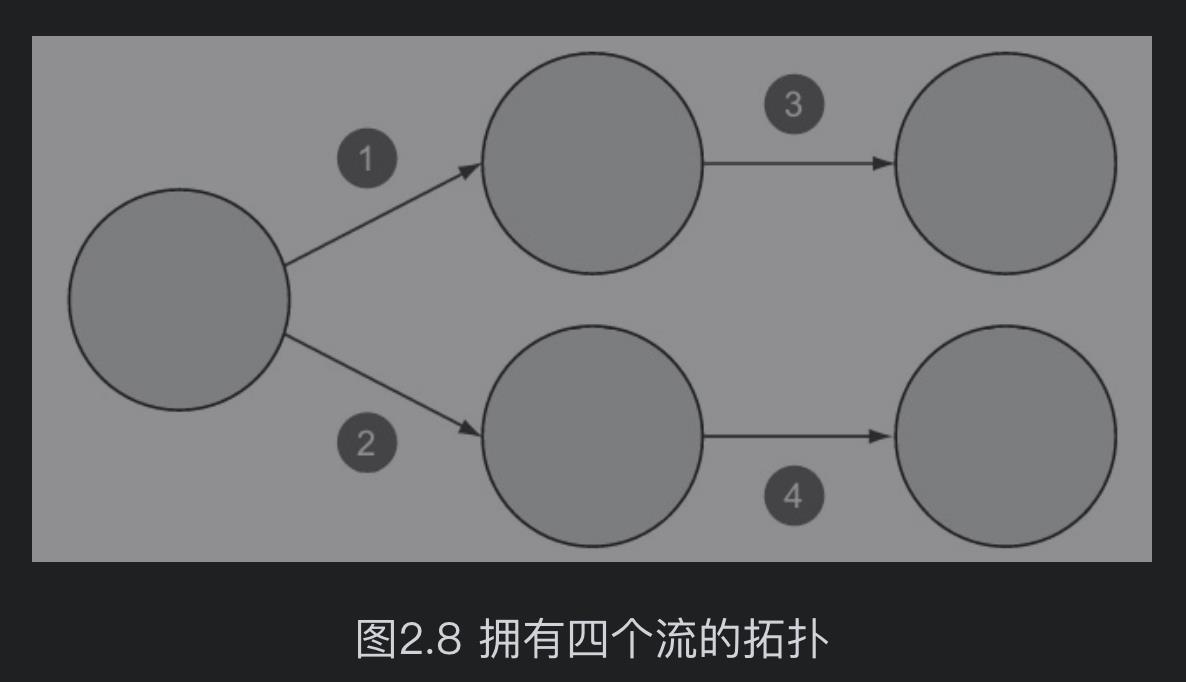
根据Storm维基中的描述,一个流是一个“无边界的元组序列”,这是关于流最恰当的解释。在拓扑中,一个流是拓扑中两个结点间一个无边界的元组序列。
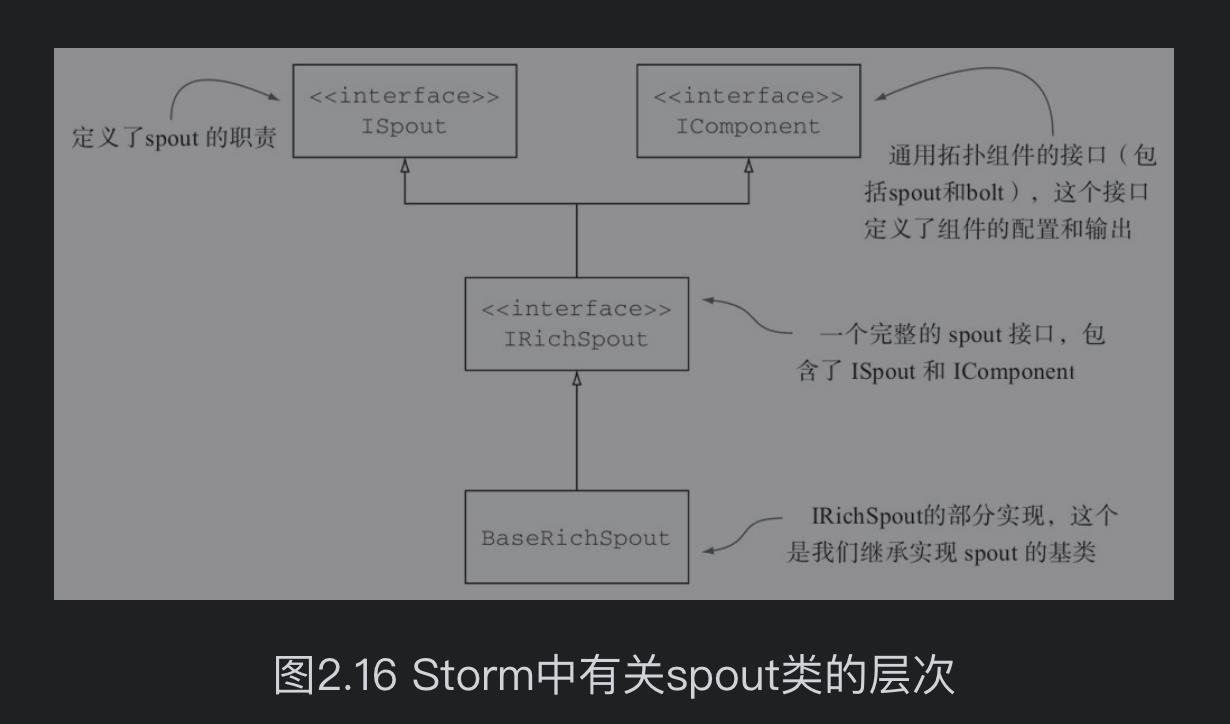
2.2.4 spout
一个spout是拓扑的流数据源头,spout通常会从外部数据源读取数据并且向拓扑中发射元组,它可以实现监听包括消息队列、数据库或者任何其他数据输入源。在我们的例子中,spout监听的是GitHub中代码仓库的提交消息,并将这些实时数据灌入Storm拓扑中。
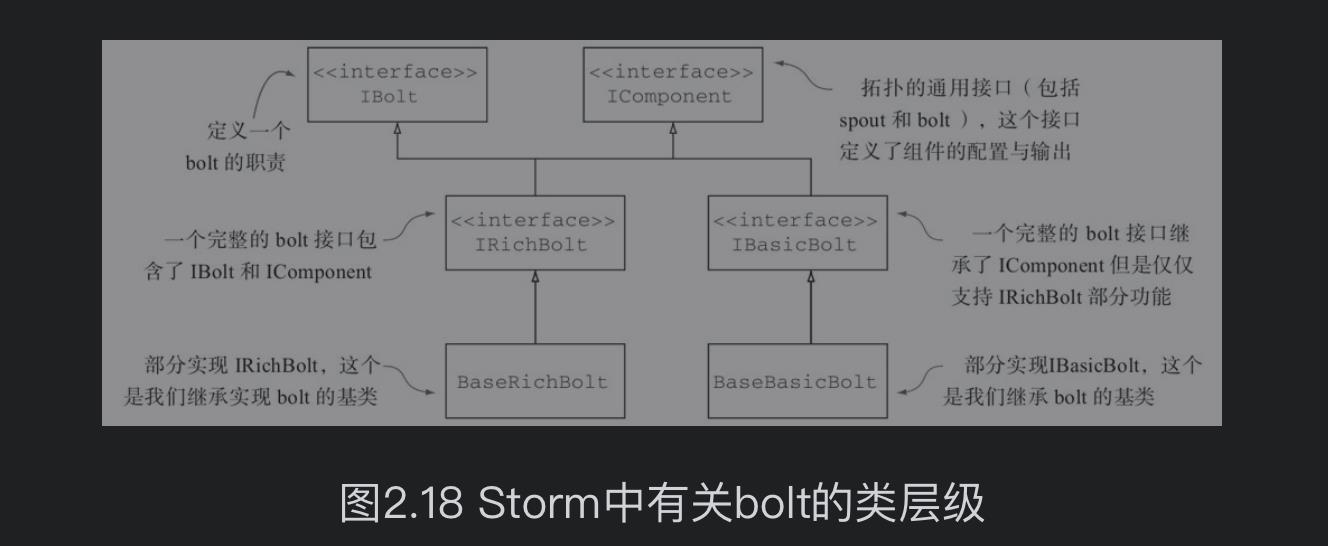
2.2.5 bolt
不同于spout只负责监听数据源,bolt可以完成从输入流的元组接收,对元组进行计算或转换操作,如过滤、聚合和连接等,以及可能会发射新的元组形成输出流。
bolt和spout是如何工作的如图2.9和图2.10所示,spout和bolt都显示为一个独立的组件,仅从逻辑视角看这是没问题的,但当讨论到它们是如何工作的时候,就需要更深入地理解和认识了。在一个运行的拓扑中,通常有大量的bolt和spout实例并行运行。
2.3 在Storm中实现GitHub提交数监控看板
完整代码见:https://github.com/mfilipelino/storm-notes
2.3.2 实现spout
class CommitFeedListener extends BaseRichSpout
private SpoutOutputCollector outputCollector;//发射元组
private List<String> commits;
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
declarer.declare(new Fields("commit"));
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector)
this.outputCollector = collector;
commits = FakeData.changeLog();
@Override
public void nextTuple()
for (String commit : commits)
outputCollector.emit(new Values(commit));
2.3.3 实现bolt
class EmailExtractor extends BaseBasicBolt
@Override
public void execute(Tuple input, BasicOutputCollector collector)
String commit = input.getStringByField("commit");
String[] parts = commit.split(" ");
collector.emit(new Values(parts[1]));
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
declarer.declare(new Fields("email"));
class EmailCounter extends BaseRichBolt
private Map<String, Integer> counts;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector)
initMap();
private void initMap()
this.counts = new HashMap < String, Integer > ();
@Override
public void execute(Tuple input)
String email = input.getStringByField("email");
counts.put(email, countFor(email) + 1);
printCounts();
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
// nada
private Integer countFor(String email)
Integer count = counts.get(email);
return count == null ? 0 : count;
private void printCounts()
for (String email: counts.keySet())
System.out.println(String.format("%s has count of %s", email, counts.get(email)));
class EmailCounter extends BaseRichBolt
private Map<String, Integer> counts;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector)
initMap();
private void initMap()
this.counts = new HashMap < String, Integer > ();
@Override
public void execute(Tuple input)
String email = input.getStringByField("email");
counts.put(email, countFor(email) + 1);
printCounts();
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
// nada
private Integer countFor(String email)
Integer count = counts.get(email);
return count == null ? 0 : count;
private void printCounts()
for (String email: counts.keySet())
System.out.println(String.format("%s has count of %s", email, counts.get(email)));
2.3.4 集成各个部分组成拓扑
我们的spout和bolt代码单独来看是无法运行的,需要先构建拓扑,并定义流和spout以及bolt之间的流分组策略。在此之后,我们就可以运行一个测试来判断拓扑是否能正常工作。Storm提供了你所需要的所有类,如下所示:
[插图]TopologyBuilder,这个类用来将spout和bolt代码片段合并在一起,并定义流和流分组策略。
[插图]Config,这个类用来定义拓扑层的配置。
[插图]StormTopology,这个类是由TopologyBuilder构建出来的,并且会被提交到集群上运行。
[插图]LocalCluster,这个类将在本地模拟一个Storm集群,使得我们可以轻松实现拓扑的运行测试。理解了这些类,我们接下来就要构建拓扑,并提交到本地集群进行测试,如代码清单如下所示。
public class LocalTopologyRunner
private static final int TEN_MINUTES = 600000;
public static void main(String[] args)
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("commit-feed-listener", new CommitFeedListener());
builder.setBolt("email-extractor", new EmailExtractor())
.shuffleGrouping("commit-feed-listener");
builder.setBolt("email-counter", new EmailCounter())
.fieldsGrouping("email-extractor", new Fields("email"));
Config config = new Config();
config.setDebug(true);
StormTopology topology = builder.createTopology();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(
"github-commit-topology",
config,
topology
);
Utils.sleep(TEN_MINUTES);
cluster.killTopology("github-commit-topology");
cluster.shutdown();
第3章 拓扑设计
3.1 拓扑设计方法
拓扑图设计的五个步骤:
1.定义问题/构造一个概念上的解决方案。
2. 将解决方案映射到Storm中。
3.实现初始方案。在这一步中,每个相关组件都将被实现并完成部署。
4.扩展拓扑。
5.一边观察一边优化。
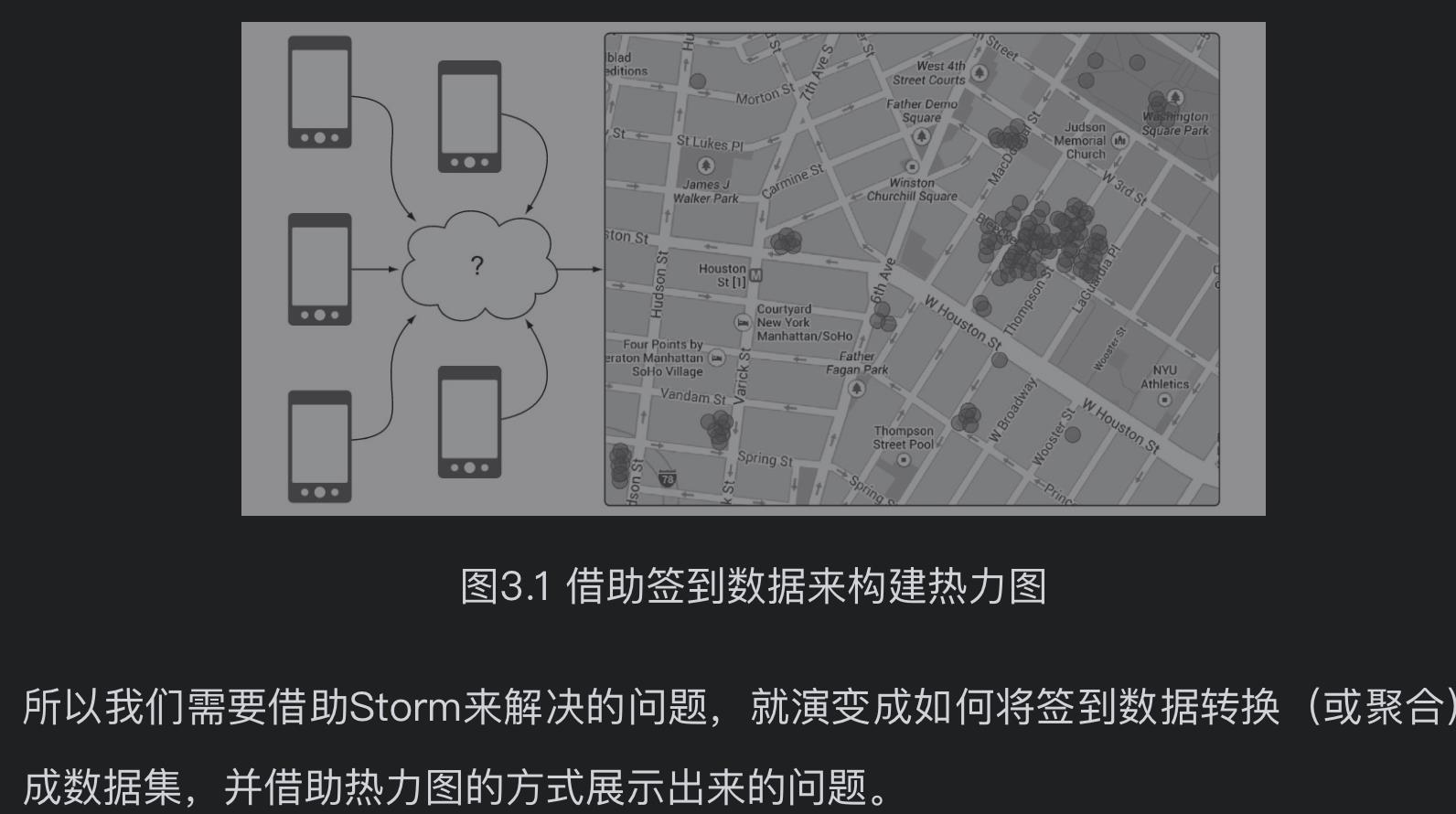
3.2 问题定义:一个社交热力图
构建概念性解决方案
3.3 将解决方案映射至Storm的逻辑
最好的方法是先考虑流经系统的数据的特性,当我们对数据流所包含的特性有足够理解后,对需求的理解也会更清晰,明白接下来应该如何在系统上建立实施。
参考:
问题
YARN系统是什么?
https://baike.baidu.com/item/yarn/16075826?fr=aladdin
以上是关于storm应用实践:实时事务处理《读书笔记》的主要内容,如果未能解决你的问题,请参考以下文章
应用案例 | 从Storm到Flink,有赞五年实时计算效率提升实践