logistic回归与手写识别例子的实现
Posted 烟囱小巫hn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了logistic回归与手写识别例子的实现相关的知识,希望对你有一定的参考价值。
本文主要介绍logistic回归相关知识点和一个手写识别的例子实现
一、logistic回归介绍:
logistic回归算法很简单,这里简单介绍一下:
1、和线性回归做一个简单的对比
下图就是一个简单的线性回归实例,简单一点就是一个线性方程表示

(就是用来描述自变量和因变量已经偏差的方程)
2、logistic回归
可以看到下图,很难找到一条线性方程能将他们很好的分开。这里也需要用到logistic回归来处理了。

logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测。g(z)可以将连续值映射到0和1上。
logistic回归的假设函数如下,线性回归假设函数只是![]() 。
。
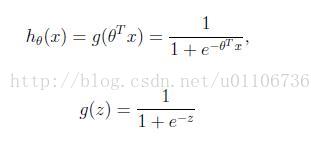
logistic回归用来分类0/1问题,也就是预测结果属于0或者1的二值分类问题。这里假设了二值满足伯努利分布,也就是

其实这里求的是最大似然估计,然后求导,最后得到迭代公式结果为
![]()
可以看到与线性回归类似。
3、logistic回归原理介绍
(1)找一个合适的预测函数,一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
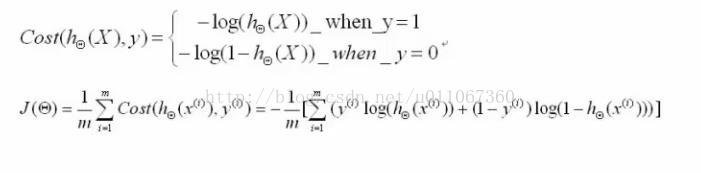
实际上这里的Cost函数和J(θ)函数是基于最大似然估计推导得到的,这里也就不详细讲解了。
(3)我们可以看出J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值,Logistic Regression实现时有的是梯度下降法(Gradient Descent)。
![]()
梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
梯度方向由J(θ)对θ的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。结果为
![]()
迭代更新的方式有两种,一种是批梯度下降,也就是对全部的训练数据求得误差后再对θ进行更新,另外一种是增量梯度下降,每扫描一步都要对θ进行更新。前一种方法能够不断收敛,后一种方法结果可能不断在收敛处徘徊。
二、手写识别的例子实现
讲到用logistic算法识别数字0~9,这是个十类别问题,如果要用logistic回归,得做10次logistic回归,第一次将0作为一个类别,1~9作为另外一个类别,这样就可以识别出0或非0。同样地可以将1作为一个类别,0、2~9作为一个类别,这样就可以识别出1或非1........
本文的实例为了简化,我只选出0和1的样本,这是个二分类问题。
输入格式:每个手写数字已经事先处理成32*32的二进制文本,存储为txt文件。
工程文件目录说明:

logistic regression.py实现的功能:从train里面读取训练数据,然后用梯度上升算法训练出参数Θ,接着用参数Θ来预测test里面的测试样本,同时计算错误率。
打开test或者train一个文件看看:

2、简单实现:
(1)将每个图片(即txt文本)转化为一个向量,即32*32的数组转化为1*1024的数组,这个1*1024的数组用机器学习的术语来说就是特征向量。
(2)训练样本中有m个图片,可以合并成一个m*1024的矩阵,每一行对应一个图片。
(3)用梯度下降法计算得到回归系数。
(4)分类,根据参数weigh对测试样本进行预测,同时计算错误率。
代码如下:
- # -*- coding: utf-8 -*-
- from numpy import *
- from os import listdir
- """
- (1)将每个图片(即txt文本)转化为一个向量,即32*32的数组转化为1*1024的数组,这个1*1024的数组用机器学习的术语来说就是特征向量。
- 实现的功能是从文件夹中读取所有文件,并将其转化为矩阵返回
- 如调用loadData(\'train\'),则函数会读取所有的txt文件(\'0_0.txt\'一直到\'1_150.txt\')
- 并将每个txt文件里的32*32个数字转化为1*1024的矩阵,最终返回大小是m*1024的矩阵
- 同时返回每个txt文件对应的数字,0或1
- """
- def loadData(direction):
- print(direction)
- trainfileList=listdir(direction)
- m=len(trainfileList)
- dataArray= zeros((m,1024))
- labelArray= zeros((m,1))
- for i in range(m):
- returnArray=zeros((1,1024)) #每个txt文件形成的特征向量
- filename=trainfileList[i]
- fr=open(\'%s/%s\' %(direction,filename))
- for j in range(32):
- lineStr=fr.readline()
- for k in range(32):
- returnArray[0,32*j+k]=int(lineStr[k])
- dataArray[i,:]=returnArray #存储特征向量
- filename0=filename.split(\'.\')[0]
- label=filename0.split(\'_\')[0]
- labelArray[i]=int(label) #存储类别
- return dataArray,labelArray
- #sigmoid(inX)函数
- def sigmoid(inX):
- return 1.0/(1+exp(-inX))
- #用梯度下降法计算得到回归系数,alpha是步长,maxCycles是迭代步数。
- def gradAscent(dataArray,labelArray,alpha,maxCycles):
- dataMat=mat(dataArray) #size:m*n
- labelMat=mat(labelArray) #size:m*1
- m,n=shape(dataMat)
- weigh=ones((n,1))
- for i in range(maxCycles):
- h=sigmoid(dataMat*weigh)
- error=labelMat-h #size:m*1
- weigh=weigh+alpha*dataMat.transpose()*error
- return weigh
- #分类函数,根据参数weigh对测试样本进行预测,同时计算错误率
- def classfy(testdir,weigh):
- dataArray,labelArray=loadData(testdir)
- dataMat=mat(dataArray)
- labelMat=mat(labelArray)
- h=sigmoid(dataMat*weigh) #size:m*1
- m=len(h)
- error=0.0
- for i in range(m):
- if int(h[i])>0.5:
- print (int(labelMat[i]),\'is classfied as: 1\')
- if int(labelMat[i])!=1:
- error+=1
- print (\'error\')
- else:
- print (int(labelMat[i]),\'is classfied as: 0\')
- if int(labelMat[i])!=0:
- error+=1
- print (\'error\')
- print (\'error rate is:\',\'%.4f\' %(error/m))
- """
- 用loadData函数从train里面读取训练数据,接着根据这些数据,用gradAscent函数得出参数weigh,最后就可以用拟
- 合参数weigh来分类了。
- """
- def digitRecognition(trainDir,testDir,alpha=0.07,maxCycles=10):
- data,label=loadData(trainDir)
- weigh=gradAscent(data,label,alpha,maxCycles)
- classfy(testDir,weigh)
- #运行函数
- digitRecognition(\'train\',\'test\',0.01,50)
当然,digitRecognition(\'train\',\'test\',0.01,50) 这里面的0.01 和 50都是可以调整的
最终结果如下:
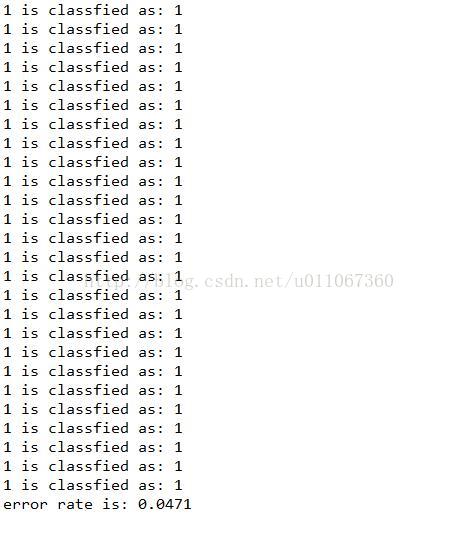
整个工程文件包括源代码、训练集、测试集,可到点击下载
参考资料:
https://www.coursera.org/course/ml
http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971867.html
http://blog.csdn.net/dongtingzhizi/article/details/15962797
以上是关于logistic回归与手写识别例子的实现的主要内容,如果未能解决你的问题,请参考以下文章
模式识别与机器学习——logistic regression