spark优化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark优化相关的知识,希望对你有一定的参考价值。
优化一般考虑资源优化
一、资源优化
I 集群方面的:driver的内存,worker内存,核数
方法
1.配置文件:spark-env.sh(配置worker的信息)
SPARK_WORKER_CORE 每个worker的使用总核数
SPARK_WORKER_MEMORY 每个worker所使用的内存数(shuffer阶段利用netty
传输文件还会使用到的executor堆外内存也在其中)
SPARK_WORKER_INSTANCE 每台节点上启动的worker数量(standalone集群上
默认为1个,运行在yarn上默认是2个)
2.提交job的时候进行设置(配置excutor的信息)
--executor-cores 默认情况下每一个Executor使用这台Worker所有的core
--executor-memory 1
--driver-cores 1
--driver-memory 1
--total-executor-cores
堆外内存设置(传输过程中netty框架使用,较小可能到导致excutor挂掉)
--conf spark.yarn.executor.memoryOverhead=2048(yarn)
--conf spark.executor.memoryOverhead=2048 (stabdalone)
excutor间通信超时时间(防止在gc发生期间连接导致传输失败)
--conf spark.core.connection.ack.wait.timeout=60
II excutor的内存分布

III 根据配置的资源情况调节并行度,也就是task的个数
合理设置并行度,就可以完全充分利用你的集群计算资源,合理设置并行度,就可以完全充分利用你的集群计算资源,让每个task处理的数据量尽量减少来提高速度.
task的数量:至少设置成与集群cpu core数量相同(理想化的状态:每个核分配到任务之后,并行处理,结束的时间基本相同)
官方推荐task的数量为总的cpu core的数量的2~3倍
但是实际情况与理想情况会产生偏差(由于每个核的处理性能和每个核处理的数据量(例如一
条数据包含的量比较大)),所以将task的数量设置为2~3倍,可以有效地使处理速度快的核处理
更多的数据
设置task的数量方法(主要由stage中的finalRDD中的partition数来决定的--因为管道模式执行)
1.job执行过程中shuffle 之后reducer的分区数,默认是跟上一个rdd相同
--conf spark.default.parallelism(sparkcore)
--conf spark.sql.shuffle.partitions(sparksql) 默认200
2.数据源是hdfs,可以增加block块的大小
3.读取文件的方法:textFile(filePath,numPartitions)
4.shuffer类的算子 可以传入numPartitions
5.自定义的分区器
6.reparttion,coalesce
sparkStreaming+kafka情况下:
recerver(接收模式): block.interval 默认200ms
dirct(直联模式): 读取的topics数 KafkaUtils.createDirectStream()
二、代码优化
代码优化主要通过调节框架执行的参数与代码使用的算子层面进行优化
1.避免创建重复的RDD:性能没有影响
2.尽可能的复用RDD
3.对多次使用的RDD进行持久化
cache MEMORY_ONLY
persist 选择的优先顺序
I MEMORY_ONLY
II MEMORY_ONLY_SER
III MEMORY_AND_DISK_SER
IV 不建议使用DISK_ONLY
checkpoint(主要是为了防止数据丢失,最好在调用之前cache一下)
I 持久化数据到 HDFS
II 切断RDD之间的依赖关系
执行流程:
1、我们的job 的 job执行完成后,会从final RDD 从后往前回溯
2、在回溯的过程,哪一个RDD调用了checkpoint就对这个RDD
做一个标记
3、框架会自动重新启动一个新的job,重新计算这些RDD,然
后将结果持久化到HDFS上
4、切断这些RDD的依赖关系,统一改名为checkpointRDD
4.避免使用shuffle类的算子 主要指join
可以利用广播变量改变 用在一个RDD数量较大,一个较小的情况
join = 广播变量 + filter 获取的数据只与其中一个RDD有关
join = 广播变量 + mapToPair(或者map) 获取的结果用到了两个RDD中的数据
注意: 广播变量大小不能超过executor内存的54%
5.使用map-side预处理shuffer的操作,也就是多使用有combine操作的shuffle算子
reduceByKey 代替 groupByKey
aggregateByKey
combineByKey
6.使用高性能的算子
mapPartition <- map
foreachPartition <- foreach
reduceByKey
aggreateByKey
reparttion(增加分区)
filter+coalesce(减少分区,也就是task的数量)
7.广播变量
如果不适用广播变量情况下,算子的方法中用到了driver中的变量(其实是常量),那么每个task都会有一个变量副本,使用广播变量会是副本数量减小到每个executor一份
8.序列化的时候 采用Kyro序列化方式
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer").registerKryoClasses(new Class[]{XXXXX.class}))
在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输
将自定义的类型作为RDD的泛型类型时(比如JavaRDD<>,SXT是自定义类
型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必
须实现Serializable接口。
使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中
的每个partition都序列化成一个大的字节数组。
9.优化数据结构
10. 使用高性能的库fastutil 例如IntValue来代替List<Integer>
三、shuffle调优
1.选择shuffle的类型
spark.shuffle.manager 1.2以及以后版本默认为sort
hash (开启合并机制) spark.shuffle.consolidateFiles false默认未开启
sort (开启byPass机制) spark.shuffle.sort.bypassMergeThreshold > shuffle read task
2.buffer 大小 默认32k spark.shuffle.file.buffer
3.reduce task 拉取数据的失败等待时间,失败的重试次数
spark.shuffle.io.maxRetries spark.shuffle.io.retryWait
4.reduce task 拉取数据 一次拉取的量 spark.reducer.maxSizeInFlight 默认48m
四.JVM调优
通过woker的4040UI页面查看task的GC时间 如果GC时间过大 考虑调节GC时间
调节方式
1.降低RDD缓存所占比例
2.降低shuffle聚合数据所占内存比例
3.增大executor的内存
五.task的数据本地化调优
task需要的数据与task最好位于同一个excutor中,可以充分的减少网络io开销
本地化级别分为
PROCESS_LOCAL
task执行所须得数据位于同一excutor的内存中
NODE_LOCAL
task执行所需要的数据位于同一台机器的内存中,可以是其他excutor的内存中
NO_PREF
ROCK_LOCAL
task执行所需要的数据位于同一个机架上的机器的内存中或者磁盘中
ANY
task与数据在集群的任意地方
taskscheduler发送task的时候首先选择process_local,但是由于excutor中可能存在task执行
那么会造成任务的失败,taskscheduler会等待3秒后进行重试,重试5次之后会降低本地化级别
进行发送task
通过UI页面查看每个任务的本地化级别,如果级别都是过低,那么就应该调节本地化级别
调节等待时间:
spark.locality.wait
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
六.数据倾斜的处理(一个stage的执行速度取决于最慢的task执行的速度)
主要针对join进行调优
1.让hive解决 治标不治本
2.过滤掉导致倾斜的key 此操作可能是好的作用 可以去除机械点击或者爬虫产生的数据
3.提高shuffer的并行度 当数据比较均匀的条件下使用
4.双重聚合 当数据量比较大,并进行聚合操作的时候
先将key打上随机的reduce task以下的数作为前缀,进行一次聚合
去掉前缀,再次进行聚合
5.将reduce join 装化为 map join 使用与join的其中一个RDD数量比较小(几百兆到一两个G)
利用广播变量 来替代join
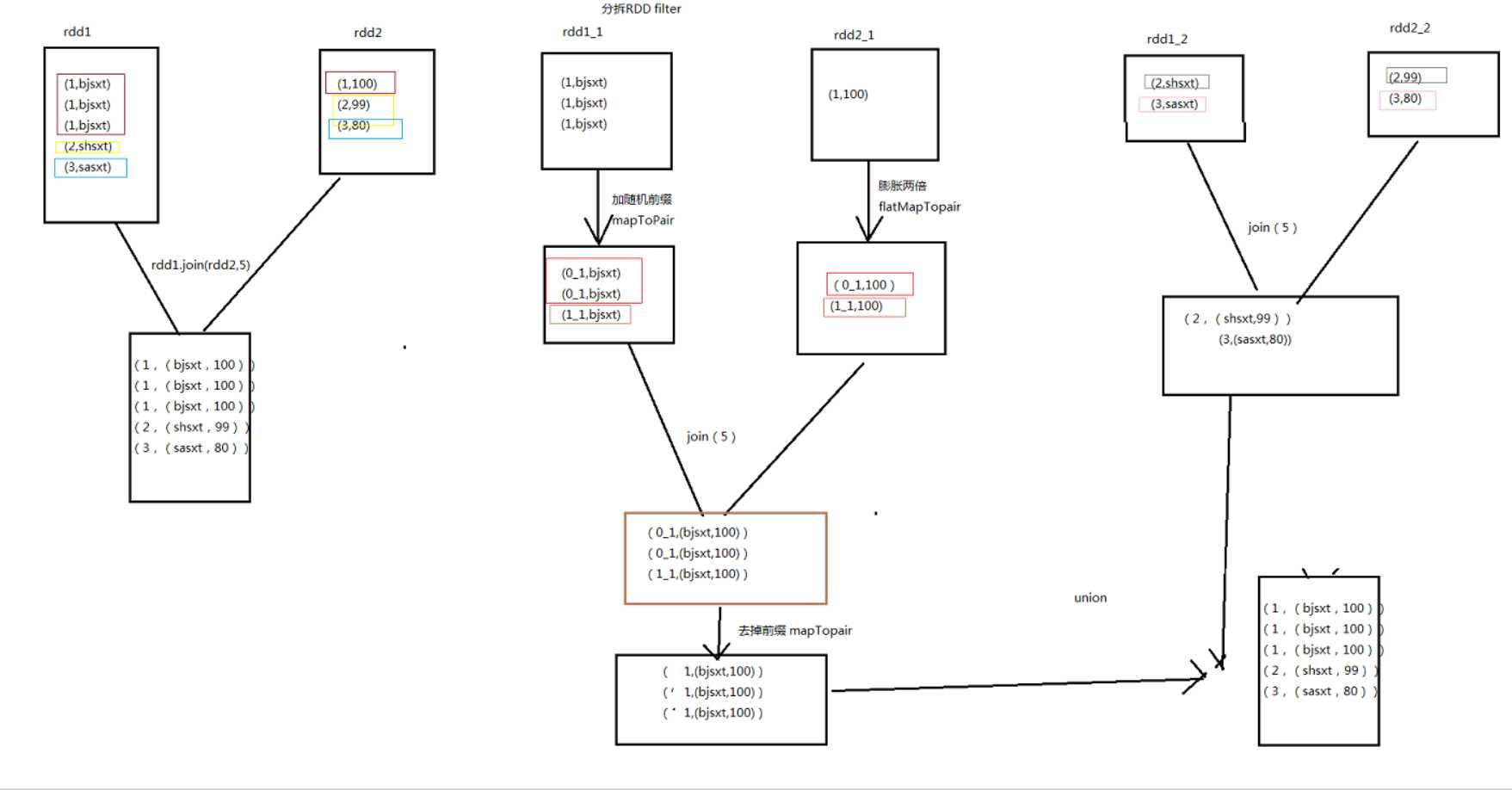
6.拆分其中导致数据倾斜的RDD 一个RDD,少量key对应很多数据量,另一个比较均匀
I 抽样查询其中key对应数据量较多的键值对
II 将两个RDD中的TopN的key过滤出来变为四个RDD,两个包含导致倾斜的key的RDD,
两个都是不会倾斜key的RDD
III 包含导致倾斜key的两个RDD 其中导致倾斜的RDD进行拼接reduce task 以内随机数的
前缀,另外一个进行扩充reduce task倍并拼接从0到reduce task 前缀的操作,利用
reduce task个task进行join操作,将join后的结果key去除前缀
IV 将不会倾斜的RDD进行join计算
V 将两个得到的结果进行union 拼接得到最终的join的结果
7.大量的key导致数据倾斜 一个RDD,少量key对应很多数据量,另一个比较均匀
直接将导致倾斜的RDD打上N以内的随机数前缀
另一个扩充N倍并打上从0到N的的前缀
利用N个task来进行join
shuffle file 找不到问题分析:
问题分析:
Executor挂掉了,BlockManager对象就没了
Executor没有挂掉,而是在建立通信或者在数据传输的环节出现了问题
解决:
如果是Executor挂掉了,
堆内内存不足
1、检查代码 2、提高Executor的内存 --executor-memory
堆外内存不足导致
--conf spark.yarn.executor.memoryOverhead=2048(yarn)
--conf spark.executor.memoryOverhead=2048 (stabdalone)
注意:是在提交application的时候设置
如果Executor没有挂掉
建立通信出现了问题(可能是遇到map的excutor正处于gc状态)
增加建立通信的超时时间-conf spark.core.connection.ack.wait.timeout=60
注意:是在提交application的时候设置
数据传输的环节出现了问题:
提高拉数据的重试次数以及等待时间
以上是关于spark优化的主要内容,如果未能解决你的问题,请参考以下文章