spark是如何改进优化hadoop框架的
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark是如何改进优化hadoop框架的相关的知识,希望对你有一定的参考价值。
参考技术A 在spark优化hadoop中的思路,就是优化了hadoop的shuffle过程。shuffle落入磁盘,需要将数据序列化。spark已经将shuffle过程优化,在此基础上进一步优化,需要对序列化进行优化。一种 Hadoop 和 Spark 框架的性能优化系统
文章目录
背景介绍
大数据概念
大数据(Big Data),又称为巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理的时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。
但大数据是个抽象的概念,业界对大数据还没有一个统一的定义,而且用上面的定义似乎难以理解,所以就有了以下用 “4V” 来定义大数据的方法。
大数据特征
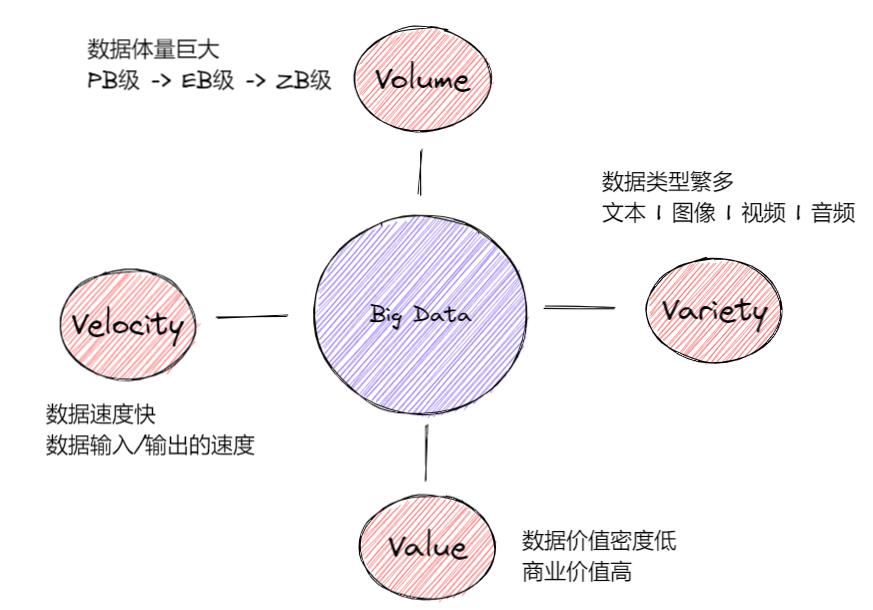
说到大数据的特征,就不得不提到“4V”。那什么是“4V”呢?
“4V” 即四个用来描述大数据特征的英文单词:Volume(体积)、Velocity(速度)、Variety(多样) 和 Value(价值)。用“4V”的方式给大数据下个中文定义,那就是满足 数据体量巨大、数据速度快速、数据种类繁多和数据价值密度低 的数据即大数据。
每天大家都在使用微信、QQ与好友开黑聊天,用支付宝、淘宝完成线上下支付。时过境迁,目前互联网产生的数据已经远远地超过很多年前的“3G时代”。比如下图,生动形象地描述了2021年各大互联网公司每分钟所产生的数据。

像是 Tiktok 每分钟就产生了5000次下载,197.6 百万条电子邮件被发出,500 个小时的视频被上传。虽然不是国内的数据,但也能反映出国内的一些情况,更能让我们体会到大数据时代下的数据量之大,数据种类之繁杂。侧面也能反映出处理这些数据的困难。
问题解决
那么大数据是怎样一步步发展到今天的呢?在回答这个问题之前,我们先来介绍一下两个由著名的 Apache 基金会开源出来的非常重要的项目 Apache Spark 和 Apache Hadoop。
Apache Hadoop 介绍
Apache Hadoop 是一个开源的,可靠的,可扩展的分布式计算框架,是下面这位大佬 Doug Cutting 发明的。这个项目的名称以及Logo来源也很有趣,就是大佬手中拿着的玩具的名字,对比一下 Apache Hadoop 的 Logo,是不是感觉有异曲同工之处?

Apache Hadoop 能做些什么呢?搭建大型的数据仓库以及PB级别的数据的存储、处理、分析、统计等业务,这些 Hadoop 都不在话下。而且,在搜索引擎时代,数据仓库时代、数据挖掘时代以及如今的机器学习时代,Hadoop 都分别担当着重要的作用。
Apache Spark 介绍
Apache Spark 是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架。具有运行速度快、易用性好、通用性强以及随处运行的特点。

Apache Spark 支持使用内存中处理来提升大数据分析应用程序的性能。 大数据解决方案旨在处理对传统数据库来说太大或太复杂的数据,而使用Spark 处理内存中的大量数据,会比基于磁盘的替代方法要快得多。
两者的联系
Apache Hadoop 提供分布式数据存储功能HDFS,还提供了用于数据处理的 MapReduce。虽然 MapReduce 是可以不依靠 Apache Spark 进行数据的处理,Apache Spark 也可以不依靠 HDFS 来完成数据存储功能,但如果两者结合在一起,让 Apache Hadoop 来提供分布式集群和分布式 文件系统,Apache Spark 可以依附 HDFS 来代替 MapReduce 去弥补 MapReduce 计算能力不足的问题。
或许,有了上面的两个框架,处理如今的大数据时代所产生的问题已经很完美了,但是看一看下图对全球数据量以及其增速的预测,就知道我们的技术仍然需要精进。

如何精进
从 Hadoop 源头
此时,或许我们应该了解一下 Apache Hadoop 的来源。Apache Hadoop 最早起源于Nutch。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003~2014 年 Google 发表的三篇论文为这个问题带来了解决的方案。三篇论文中分别提到了三个至关重要的技术点 GFS,MapReduce 以及 BigTable。最终分别演变成了 Hadoop 生态中的 HDFS,Hadoop MapReduce 以及 HBase。
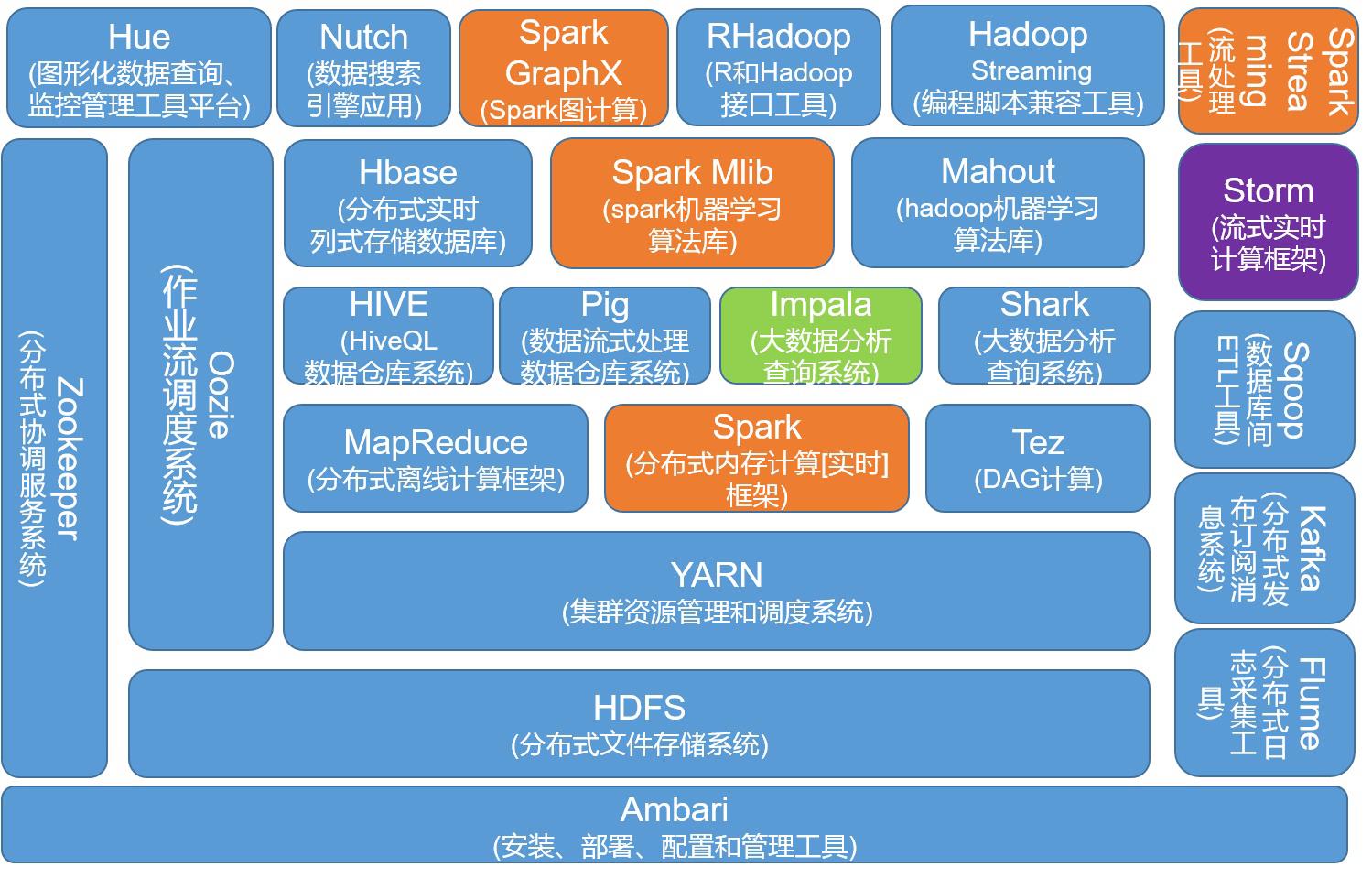
而其中的 Hadoop MapReduce 就是 Apache Hadoop 中重要的组成部分之一,它是数据中心的一个重要的数据处理引擎,它可以帮助用户避免维护物理基础设施的成本。许多研究都集中在 MapReduce 的任务上,来提高数据中心的性能并将能源的消耗大幅降低。这期阅读的论文也是研究了与 MapReduce 相关的数据压缩。
从数据压缩入手
数据压缩算法的权衡取决于各种因素,比如压缩程度、数据质量、压缩算法类型或者数据类型。最终的数据大小或是 I/O 减少的程度取决于压缩比,而压缩比取决于数据和压缩算法。这意味着更低的比率将会减少内存以及I/O的使用。
从 Hadoop 特性
下面是 Hadoop 中可用的压缩格式的摘要
| 序号 | 压缩格式 | 文件扩展名 | 是否可拆分 |
|---|---|---|---|
| 1 | gzip | .gz | 否 |
| 2 | bzip | .bz2 | 是 |
| 3 | snappy | .snappy | 是(container file formats) |
| 4 | Lzo | .lzo | 是(indexing algorithm) |
| 5 | lz4 | .4mc | 是(4MC library) |
| 6 | zstandart | .4mz | 是 (4MC library) |
由于数据需要被安全的存储,所以作者选择的上表中所有选择的压缩编码器以及解码器都是无损的。
gzip 和 deflate 编解码器都使用 deflate 算法来替代 lz77 和 Huffman 编码的组合。两者的区别在于 Huffman 编码阶段
可拆分压缩 bzip2 编解码器使用 Burrows-Wheeler(块排序)文本压缩和 Huffman 编码算法。Bzip2 可以独立压缩数据块,也可以并行压缩数据块。
Snappy 是一个快速的数据压缩和解压缩库,使用了 lz77 的思想。Snappy 块是不可分割的,但是 Snappy 块中的文件是可分割的。
lzo (Lempel- Ziv-Oberhumer)压缩算法是 lz77 压缩算法的变体。该算法分为查找匹配,写入未匹配的文字数据,确定匹配的长度,以及写入匹配令牌部分。
压缩的数据文件由 lz4 序列组成,该序列包含一个标记、文字长度、偏移量和匹配长度。
Zstandart 是 Facebook 开发的一种基于 lz77 的算法,支持字典、大规模搜索框和使用有限状态熵和霍夫曼编码的熵编码步骤。
Hadoop 支持的压缩格式太多,因此需要一种可以动态选择压缩方式的算法,根据数据类型对压缩格式进行选择。
相关工作
关于 I/O 性能。作者分析了几篇论文,找到提升 I/O 性能并能提高能源效率的方法。
- 首先作者阅读量三篇论文,该论文中的作者将 4 个计算机节点集群,来研究部分数据压缩对 MapReduce 小工作量的情况下对性能的提高以及对能源的利用情况。
- 其次该论文中的作者从已有的几种方法和压缩算法来确定压缩方法,以减少数据加载时间和提高并发性。
- 最后,该论文中的作者研究了两种可动态选择的算法,通过周期性的压缩算法特征分析和实时系统资源状态的监控来实现最佳的 I/O 性能。
关于能源效率。作者选取了几篇论文,分析了不同的能源模型来预测 MapReduce 作业时的能源消耗。
- 通过调整数据复制系数和数据块大小参数,最小化了作业的执行时间和能耗。
- 其次,作者通过另一篇论文的一个预测 MapReduce 工作负载能耗的线性回归模型,发现了了通过精确的资源分配和只能的动态电压和频率缩放调度,可以显著节省能源。
- 还有,作者了解了修改 Hadoop 以实现可操作集群规模缩减方面的早期工作。
- 最后,作者阅读了一篇调整HPC集群并行度,网络带宽以及电源管理功能的策略,来达到高效执行 MapReduce 的目的。
作者最终通过修改Hadoop/Spark 框架中关于能源效率的各种配置参数,以达到提升 Hadoop MapReduce 作业的性能的目的。论文旨在提出一个选择最佳压缩工具并调整压缩因子以达到最佳性能的系统。
引文
- [1]Astsatryan H, Kocharyan A, Hagimont D, et al. Performance Optimization System for Hadoop and Spark Frameworks[J]. Cybernetics and Information Technologies, 2020, 20(6): 5-17.
- [2]Professional Hadoop Solutions
- [3]Big data challenge: a data management perspective[J]. 中国计算机科学前沿:英文版, 2013(2):8.
- [4]Nitu V, Kocharyan A, Yaya H, et al. Working set size estimation techniques in virtualized environments: One size does not fit all[J]. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 2018, 2(1): 1-22.
 2022深度学习开发者峰会
2022深度学习开发者峰会
 5月20日13:00让我们相聚云端,共襄盛会!
5月20日13:00让我们相聚云端,共襄盛会!
以上是关于spark是如何改进优化hadoop框架的的主要内容,如果未能解决你的问题,请参考以下文章