spark学习之作业优化
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark学习之作业优化相关的知识,希望对你有一定的参考价值。
💅在前面的spark优化学习中,我们学习了spark的语法、资源调度、sql语法优化和数据倾斜的技巧,今天我们来学习spark中的作业优化,也就是job优化。对往期内容感兴趣的同学可以参考👇:
- 链接: spark学习之处理数据倾斜.
- 链接: spark学习之sparksql语法优化.
- 链接: spark学习之资源调度.
- 链接: spark学习之执行计划explain.
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🙈关于spark的作业优化,主要是对map端和reduce端作业这两个部分进行优化,优化的内容可能和处理数据倾斜时的内容有点重复,重复的部分就当作复习啦。
目录
1. map端优化
1.1 map端预聚合
map-side 预聚合:就是在每个节点本地对相同的 key 进行一次聚合操作,类似于MapReduce 中的本地 combiner。map-side 预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的 key 都被聚合起来了。其他节点在拉取所有节点上的相同 key 时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘 IO 以及网络传输开销。( 使用sparksql时,会自动使用HashAggregte 实现本地预聚合+全局聚合)
操作RDD :建议使用 reduceByKey 或者 aggregateByKey 算子来替代掉 groupByKey 算子。因为 reduceByKey 和 aggregateByKey 算子都会使用用户自定义的函数对每个节点本地的相同 key 进行预聚合。而 groupByKey 算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
1.1 读取小文件
读取的数据源有很多小文件,会造成查询性能的损耗,大量的数据分片信息以及对应产生的 Task 元信息也会给 Spark Driver 的内存造成压力,带来单点问题。
hive的处理方式:在hive中,我们在map端执行前合并小文件,使用的是combinerhiveinputformat方法,对小文件进行合并,而hiveinputformat没有对小文件合并的功能。
#设置方法如下:
set hive.input.format=org.apche.hadoop.hive.sq.io.CombinerHiveInputFormat
spark的处理方式:spark也可以通过设置参数,设置多个小文件读取到同一个分区中,达到小文件合并的目的。
#设置一个分区的最大字节数
spark.sql.files.maxPartitionBytes=128MB #默认 128m
#设置打开一个文件的开销
spark.files.openCostInBytes=4194304 #默认 4m
这里我们解释一下这两个参数的作用:
- 对于一个小文件的大小,他的组成有2部分:自身的文件大小和打开文件的开销,即: 文 件 大 小 = 文 件 自 身 大 小 + 打 开 文 件 开 销 ( o p e n C o s t I n B y t e s ) 文件大小=文件自身大小+打开文件开销(openCostInBytes) 文件大小=文件自身大小+打开文件开销(openCostInBytes)
- 合并多个小文件时,考虑的是满足以下关系才能进行合并: ( 文 件 1 大 小 ) + ( 文 件 2 大 小 ) + ( 文 件 3 大 小 ) + . . . . . . < m a x P a r t i t i o n B y t e s (文件1大小)+(文件2大小)+(文件3大小)+......<maxPartitionBytes (文件1大小)+(文件2大小)+(文件3大小)+......<maxPartitionBytes
1.2 增加map 溢写时输出流 buffer
map端任务执行的流程图:
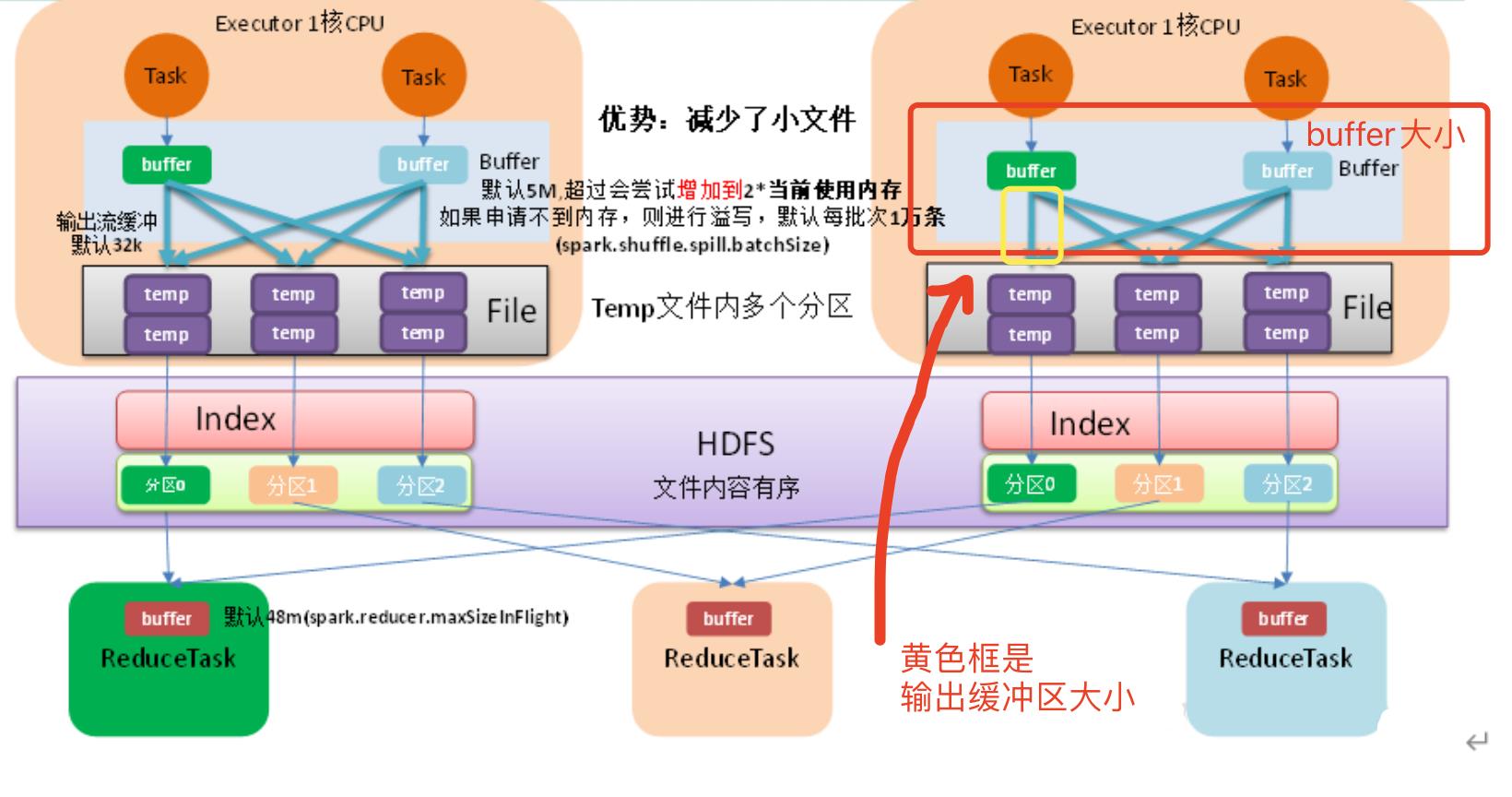
增加map端的缓冲区大小也能提高效率,缓冲区的参数主要有以下几个:
- map 端 Shuffle Write 有一个缓冲区(类似hadoop的collect),初始阈值 5m,超过会尝试增加到 2当前使用内存。如果申请不到内存,则进行溢写。(比如,我的缓冲文件大小为6m>5m,则申请内存的大小为:26-5=7m,但我们无法设置该大小)
- 溢写时使用输出流缓冲区默认 32k,这些缓冲区减少了磁盘搜索和系统调用次数,适当提高可以提升溢写效率。(这个参数是将缓冲区文件写出的大小,即传输缓冲区文件每次可传输多大的文件)
- Shuffle 文件涉及到序列化,是采取批的方式读写,默认按照每批次 1 万条去读写。设置得太低会导致在序列化时过度复制,因为一些序列化器通过增长和复制的方式来翻倍内部数据结构(这个参数用户也无法指定)
综上可知,我们只能通过设置输出流缓冲区的大小来提高效率:
spark.shuffle.file.buffer=64 #将输出流缓冲区大小从32k调整到64k
2. reduce端优化
2.1 合理设置 Reduce 数
关于这个部分,主要是对cpu资源的分配,并发度、并行度等的设置,大家可以参考下面的文章:
- 链接: spark学习之资源调度.
2.2 输出产生小文件优化
2.2.1 join结果
当我们把几张表join之后的结果插入新表后,生成的文件数数等于 shuffle 并行度,默认就是 200 份文件插入到hdfs 上。
优化方式:
- 可以在插入表数据前进行缩小分区操作来解决小文件过多问题,如 coalesce、repartition 算子实现。
- 调整 shuffle 并行度,设置 reduce的个数spark.sql.shuffle.partitions
2.2.2 动态分区插入数据
- 没有 Shuffle 的情况下。最差的情况下,每个 Task 中都有表各个分区的记录,那文件数最终文件数将达到 Task 数量 * 表分区数。这种情况下是极易产生小文件的。
- 有 Shuffle 的情况下,上面的 Task 数量 就变成了spark.sql.shuffle.partitions(默认值200)。那么最差情况就会有 spark.sql.shuffle.partitions * 表分区数,但是当spark.sql.shuffle.partitions 设 置 过 大 时 , 小 文 件 问 题 就 产 生 了 ; 当spark.sql.shuffle.partitions 设置过小时,任务的并行度就下降了,性能随之受到影响。(有shuffle的情况容易产生数据倾斜)
解决方法:
将倾斜键单独加入动态分区
//1.非倾斜键部分
INSERT overwrite table A partition ( aa )
SELECT *
FROM B where aa != 大 key
distribute by aa;
//2.倾斜键部分
INSERT overwrite table A partition ( aa )
SELECT *
FROM B where aa = 大 key
distribute by cast(rand() * 5 as int);
2.3 增大 reduce 缓冲区,减少拉取次数
map端端缓冲区大小不可设置,只能是5m,但reduce端端buffer大小可以设置,shuffle reduce task 的 buffer 缓冲区大小决定了 reduce task 每次能够缓冲的数据量,也就是每次能够拉取的数据量,如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
设置方式:
spark.reducer.maxSizeInFlight=48
2.4 调节 reduce 端拉取数据重试次数
reduce task 拉取属于自己的数据时,如果因为网络异常等原因导
致失败会自动进行重试。对于那些包含了特别耗时的 shuffle 操作的作业,建议增加重试最大次数(比如 60 次),以避免由于 JVM 的 full gc 或者网络不稳定等因素导致的数据拉取失败。reduce 端拉取数据重试次数可以通过
spark.shuffle.io.maxRetries
参数进行设置,该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败,默认为 3
2.5 调节 reduce 端拉取数据等待间隔
Spark Shuffle 过程中,reduce task 拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试,在一次失败后,会等待一定的时间间隔再进行重试,可以通过加大间隔时长(比如 60s),以增加 shuffle 操作的稳定性。reduce 端拉取数据等待间隔可以通过
spark.shuffle.io.retryWait
参数进行设置,默认值为 5s。
2.6 合理利用 bypass
当 ShuffleManager 为 SortShuffleManager 时,如果 shuffle read task 的数量小于这个阈值(默认是 200)且不需要 map 端进行合并操作,则 shuffle write 过程中不会进行排序操作,使用 BypassMergeSortShuffleWriter 去写数据,但是最后会将每个 task 产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
当你使用 SortShuffleManager 时,如果确实不需要排序操作,那么建议将这个参数调大一些,大于 shuffle read task 的数量。那么此时就会自动启用 bypass 机制,map-side 就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此 shuffle write 性能有待提高。
3. 参考资料
- 《尚硅谷大数据技术之 Spark 调优》
- 《spark权威指南》
以上是关于spark学习之作业优化的主要内容,如果未能解决你的问题,请参考以下文章