spark学习之sparksql语法优化
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark学习之sparksql语法优化相关的知识,希望对你有一定的参考价值。
🐹上一章的学习中,我们学习了spark的资源调度进行了学习,今天我们要学习的内容是sparksql语法优化部分,对往期内容感兴趣的同学可以参考👇:
- 上一篇: spark学习之资源调度.
- 上一篇: spark学习之执行计划explain.
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🌱sparksql在大数据开发中使用较多,也是优化较好的处理数据的方式,在对spark的优化过程中,百分之50的优化都是对sql的优化,由此可见sparksql的重要性。
目录
1. 基于 RBO 的SQL优化(逻辑优化)
SparkSQL 在整个执行计划处理的过程中,使用了 Catalyst 优化器。Catalyst 总共有 81 条优化规则(Rules),分成 27 组(Batches),其中有些规则会被归类到多个分组里。因此,如果不考虑规则的重复性,27 组算下来总共会有 129 个优化规则。但主要分为以下三类:
1.1 谓词下推(Predicate Pushdown)
谓词:一般是指where或者on后面的判断条件的词语,例如:LKIE、BETWEEN、IS NULL、IS NOT NULL、IN、EXISTS、<、>、=等。
谓词下推:是指在sql执行过程中,将过滤条件的谓词逻辑都尽可能提前执行,减少下游处理的数据量 。 对 应PushDownPredicte 优化规则,对于 Parquet、ORC 这类存储格式,结合文件注脚(Footer)中的统计信息,下推的谓词能够大幅减少数据扫描量,降低磁盘 I/O 开销。
1.1.1 inner join中的on条件
#学生表和分数表做内链接,求出课程01分数大于60的学生
sqlway=spark.sql("""
select s.s_id,s2.c_id,s2.s_score
from student s join score s2
on s.s_id=s2.s_id and s2.s_score>60 and s2.c_id='01'
""")
sqlway.explain(mode="extended")#展示物理执行计划和逻辑执行计划。
初始执行计划如下:
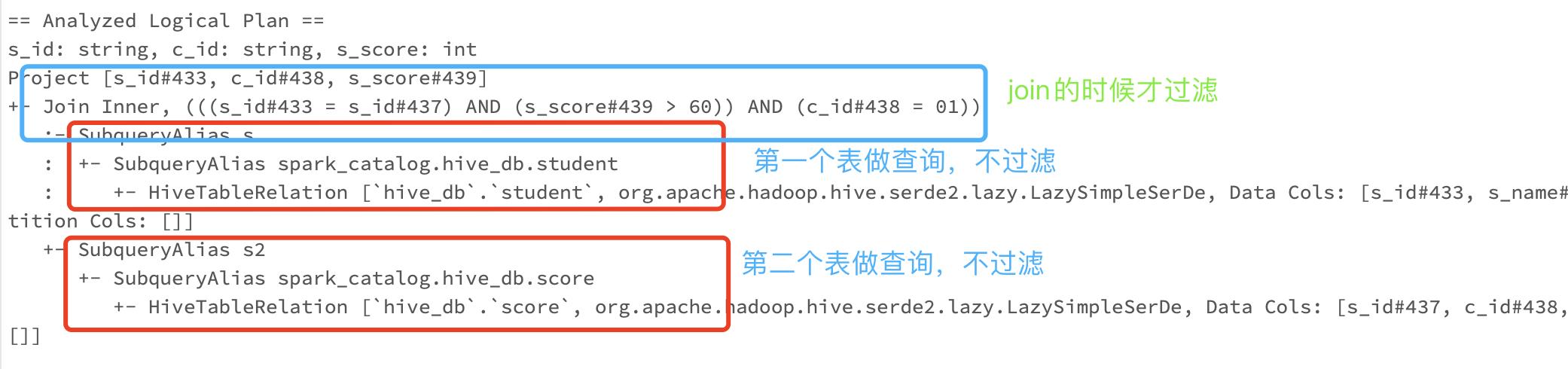
优化后的执行计划:

从上述来看,inner join优化后会将on中的条件在关联之前都会进行谓词下推.
1.1.2 inner join中的where 条件
#学生表和分数表做内链接,求出课程01分数大于60的男生,条件写在了where里
sqlway=spark.sql("""
select s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s join score s2
on s.s_id=s2.s_id and s2.s_score>60
where s.s_sex='男' and s2.c_id='01'
""")
sqlway.explain(mode="extended")#展示物理执行计划和逻辑执行计划。
初始执行计划如下:

优化后的执行计划:

以上实验可知:在inner join中,将条件写在where和on中的差别不大,优化后的执行计划都是分别在左右表中过滤,最后再连接
1.1.3 outer join 中的 on 条件
# 学生表和分数表做外链接,求出课程01分数大于60的男生,条件写在了on里
sqlway=spark.sql("""
select s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id and s2.s_score>60 and s.s_sex='男' and s2.c_id='01'
""")
sqlway.explain(mode="extended")#展示物理执行计划和逻辑执行计划。
初始执行计划如下:

优化后的执行计划:

1.1.4 outer join 中的 where 条件
# 学生表和分数表做外链接,求出课程01分数大于60的男生,条件写在了where里
sqlway=spark.sql("""
select s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id and s2.s_score>60
where s.s_sex='男' and s2.c_id='01'
""")
sqlway.explain(mode="extended")#展示物理执行计划和逻辑执行计划。
初始执行计划如下:
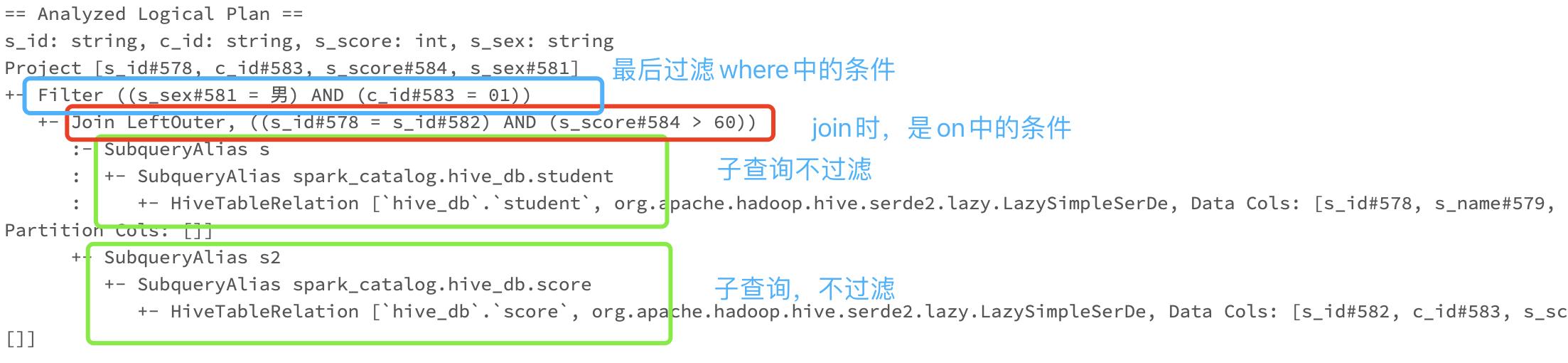
优化后的执行计划:

由以上实验可知,在外连接(以left join为例)中,条件写在on中时,谓词下推只对右表有效,而写在where中时,谓词下推对左右表都有效,这是因为where和on的最终展示效果不一样,根据自己的需求选择合适的方式即可。
1.2 列剪裁(Column Pruning)
列剪裁:就是扫描数据源的时候,只读取那些与查询相关的字段。
-- sql
select s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id and s2.s_score>60
where s.s_sex='男' and s2.c_id='01'
这一段sql的列裁剪在执行计划中就有所体现:

1.3 常量替换(Constant Folding)
常量替换:过滤条件是 “score>60+10 ”,Catalyst 会使用ConstantFolding 规则,自动帮我们把条件变成 “age>70”。再比如,我们在 select 语句中,掺杂了一些常量表达式,Catalyst 也会自动地用表达式的结果进行替换。
-- 选择出分数大于70的列
select s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id
where s2.s_score>60+10
执行计划中直接将60+10替换成70

2. 基于 CBO 的优化(物理优化)
CBO 优化主要在物理计划层面,原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划。
每个执行节点的代价,分为两个部分:
- 该执行节点对数据集的影响,即该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
- 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到。
- 中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
2.1 CBO 的使用
通过 “spark.sql.cbo.enabled” 来开启,默认是 false。配置开启 CBO 后,CBO 优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build 侧选择、优化 Join 类型、优化多表 Join 顺序等。
| 参数 | 描述 | 默认值 |
|---|---|---|
| spark.sql.cbo.enabled | CBO 总开关。true 表示打开,false 表示关闭。要使用该功能,需确保相关表和列的统计信息已经生成。 | false |
| spark.sql.cbo.joinReorder.enabled | 使用 CBO 来自动调整连续的 inner join 的顺序。true:表示打开,false:表示关闭,要使用该功能,需确保相关表和列的统计信息已经生成,且CBO 总开关打开。 | false |
| spark.sql.cbo.joinReorder.dp.threshold | 使用 CBO 来自动调整连续 inner join 的表的个数阈值。如果超出该阈值,则不会调整 join 顺序。 | 12 |
3. 广播join
广播join:Spark join 策略中,如果当一张小表足够小并且可以先缓存到内存中,那么可以使用Broadcast Hash Join,其原理就是先将小表聚合到 driver 端,再广播到各个大表分区中,那么再次进行 join 的时候,就相当于大表的各自分区的数据与小表进行本地 join,从而规避了shuffle。(和mr的mapjoin简直一摸一样),广播 join 默认值为 10MB
3.1 广播join的使用
student表是大表,score表是小表。
-- 写法1
select /*+ MAPJOIN(s2)*/
s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id
where s2.s_score>70
-- 写法2
select /*+ BROADCAST(s2)*/
s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id
where s2.s_score>70
-- 写法3
select /*+ BROADCASTJOIN(s2)*/
s.s_id,s2.c_id,s2.s_score,s.s_sex
from student s left join score s2
on s.s_id=s2.s_id
where s2.s_score>70
4. SMB Join
SMB JOIN :是 sort merge bucket 操作的三个首字母大写,主要解决的是大表join大表的情况,首先需要进行分桶,首先会进行排序,然后根据 key值合并,把相同 key 的数据放到同一个 bucket 中(按照 key 进行 hash)。分桶的目的其实就是把大表化成小表。相同 key 的数据都在同一个桶中之后,再进行 join 操作,那么在联合的时候就会大幅度的减小无关项的扫描。
SMB Join有着严格的要求:
- 两表进行分桶,桶的个数必须相等
- 两边进行 join 时,join列=排序列=分桶列
4.1 SMB Join的原理
如果两张大表进行join,那么会非常的耗时,如果我们根据key值进行hash分桶和排序,那么在两个文件中,相同的桶中一定会有着相同的key值,直接对应的桶join,最后再合并即可。

5. 总结
这一部分我们主要学习了spark中有哪些机制可以对我们的sql进行优化,我们从逻辑执行、物理执行和其他原理等方向对sparksql的优化进行了讲解,主要需要记住逻辑优化和几种join的使用场景,后面的文章将讲解sparksql在实践中如何优化。
6. 参考文献
- 《尚硅谷大数据技术之 Spark 调优》
- 《spark权威指南》
以上是关于spark学习之sparksql语法优化的主要内容,如果未能解决你的问题,请参考以下文章