HDFS源码分析之NameNode————Format
Posted Mr.Ming2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS源码分析之NameNode————Format相关的知识,希望对你有一定的参考价值。
在Hadoop的HDFS部署好了之后并不能马上使用,而是先要对配置的文件系统进行格式化。在这里要注意两个概念,一个是文件系统,此时的文件系统在物理上还不存在,或许是网络磁盘来描述会更加合适;二就是格式化,此处的格式化并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。本文接下来将主要讨论NameNode节点上的格式化。
我们都知道,NameNode主要被用来管理整个分布式文件系统的命名空间(实际上就是目录和文件)的元数据信息,同时为了保证数据的可靠性,还加入了操作日志,所以,NameNode会持久化这些数据(保存到本地的文件系统中)。对于第一次使用HDFS,在启动NameNode时,需要先执行-format命令,然后才能正常启动NameNode节点的服务。那么,NameNode的fromat命令到底做了什么事情呢?
hadoop namenode -format
在NameNode节点上,有两个最重要的路径,分别被用来存储元数据信息和操作日志,而这两个路径来自于配置文件,它们对应的属性分别是dfs.name.dir和dfs.name.edits.dir,同时,它们默认的路径均是/tmp/hadoop/dfs/name。格式化时,NameNode会清空两个目录下的所有文件,之后,会在目录dfs.name.dir下创建文件:
{dfs.name.dir}/current/fsimage
{dfs.name.dir}/current/fstime
{dfs.name.dir}/current/VERSION
{dfs.name.dir}/image/fsimage
会在目录dfs.name.edits.dir下创建文件:
{dfs.name.edits.dir}/current/edits
{dfs.name.edits.dir}/current/fstime
{dfs.name.edits.dir}/current/VERSION
{dfs.name.edits.dir}/image/fsimage
那么这些文件又是用来干什么的呢?
在介绍这文件的用途之前,我们可以将dfs.name.dir和dfs.name.edits.dir配置成相同的目录,这样的话,NameNode执行格式化之后,会产生如下的文件:{dfs.name.dir}/current/fsimage、{dfs.name.dir}/current/edits、{dfs.name.dir}/current/fstime、{dfs.name.dir}/current/VERSION、{dfs.name.dir}/image/fsimage,由此可以看出上面名字相同的文件实际是一样的,所以在这里,我建议把dfs.name.dir和dfs.name.edits.dir配置成相同的值,以来提高NameNode的效率。ok,现在就来重点的介绍一下这些文件的用途吧。
fsimage:存储命名空间(实际上就是目录和文件)的元数据信息,文件结构如下:

edits:用来存储对命名空间操作的日志信息,实现NameNode节点的恢复;
fstime:用来存储元数据上一次check point 的时间;
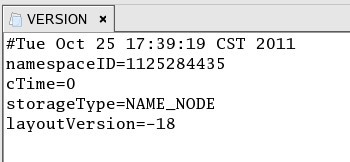
VERSION:用来存储NameNode版本信息,命名空间ID(版本号),内容如下:
/image/fsimage: 上一次提交前的/current/fsimage文件;
ok,关于NameNode执行format命令的情况就介绍到这儿。
执行源码位于NameNode类
case FORMAT: { boolean aborted = format(conf, startOpt.getForceFormat(), startOpt.getInteractiveFormat()); terminate(aborted ? 1 : 0); return null; // avoid javac warning } ..... }
获取配置路径,执行初始化
FSImage fsImage = new FSImage(conf, nameDirsToFormat, editDirsToFormat); try { FSNamesystem fsn = new FSNamesystem(conf, fsImage); fsImage.getEditLog().initJournalsForWrite(); if (!fsImage.confirmFormat(force, isInteractive)) { return true; // aborted } fsImage.format(fsn, clusterId); } catch (IOException ioe) { LOG.warn("Encountered exception during format: ", ioe); fsImage.close(); throw ioe; }
元数据的格式化
storage.format(ns);//执行下面的方法进行格式化
private void format(StorageDirectory sd) throws IOException { sd.clearDirectory(); // create currrent dir writeProperties(sd); writeTransactionIdFile(sd, 0); LOG.info("Storage directory " + sd.getRoot() + " has been successfully formatted."); }
配置项
dfs.namenode.support.allow.format 是否允许进行Namenode format,默认是true
dfs.namenode.name.dir 元数据存储路径,这个参数用于确定将HDFS文件系统的元信息保存在什么目录下。如果这个参数设置为多个目录,那么这些目录下都保存着元信息的多个备份。
dfs.namenode.edits.dir 操作日志存储路径
以上是关于HDFS源码分析之NameNode————Format的主要内容,如果未能解决你的问题,请参考以下文章