Hadoop之HDFS原理及文件上传下载源码分析(上)
Posted Devil丶俊锅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之HDFS原理及文件上传下载源码分析(上)相关的知识,希望对你有一定的参考价值。
HDFS原理
首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来。
楼主的环境:
- 操作系统:Ubuntu 15.10
- hadoop版本:2.7.3
- HA:否(随便搭了个伪分布式)
文件上传
下图描述了Client向HDFS上传一个200M大小的日志文件的大致过程:
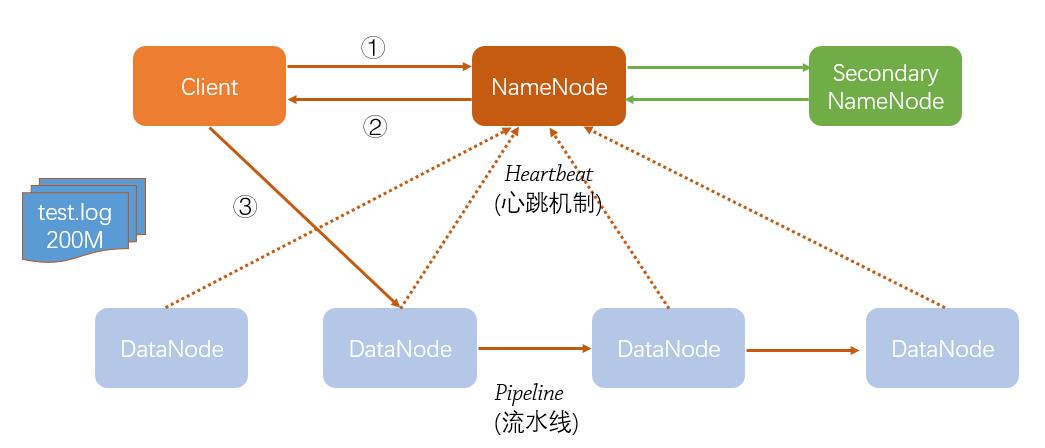
首先,Client发起文件上传请求,即通过RPC与NameNode建立通讯。
NameNode与各DataNode使用心跳机制来获取DataNode信息。NameNode收到Client请求后,获取DataNode信息,并将可存储文件的节点信息返回给Client。
Client收到NameNode返回的信息,与对应的DataNode节点取得联系,并向该节点写文件。
文件写入到DataNode后,以流水线的方式复制到其他DataNode(当然,这里面也有DataNode向NameNode申请block,这里不详细介绍),至于复制多少份,与所配置的hdfs-default.xml中的dfs.replication相关。
元数据存储
先明确几个概念:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
checkpoint可在hdfs-default.xml中具体配置,默认为3600秒:
1 <property> 2 <name>dfs.namenode.checkpoint.period</name> 3 <value>3600</value> 4 <description>The number of seconds between two periodic checkpoints. 5 </description> 6 </property>
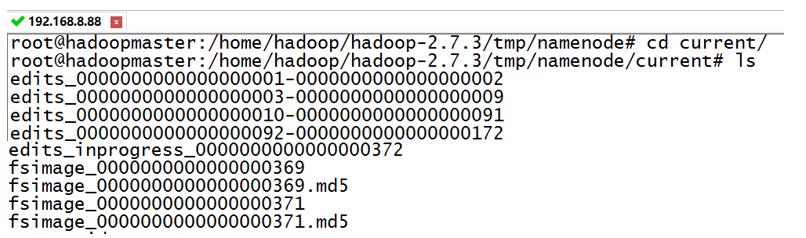
fsimage和edits文件在namenode目录可以看到:
NameNode中的元数据信息:
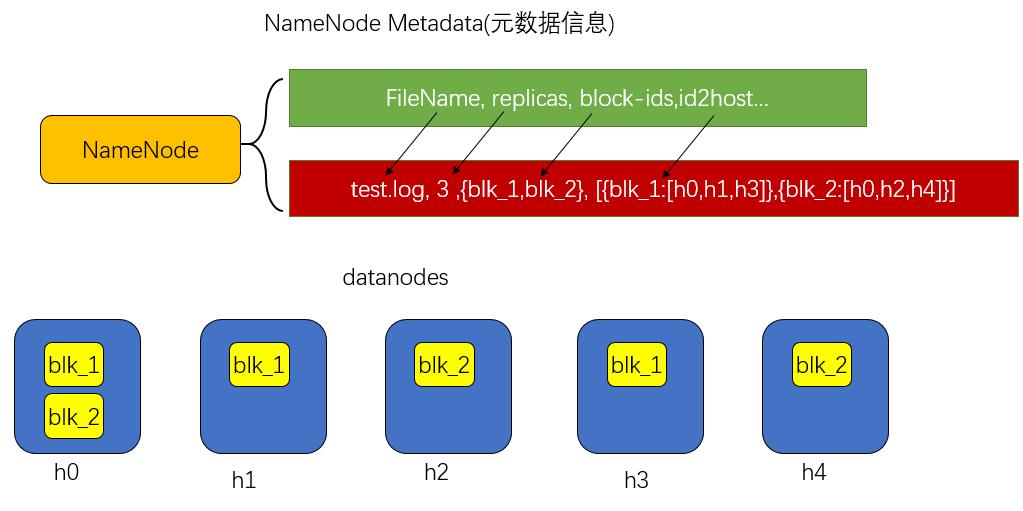
test.log文件上传后,Namenode始终在内存中保存metedata,用于处理“读请求”。metedata主要存储了文件名称(FileName),副本数量(replicas),分多少block存储(block-ids),分别存储在哪个节点上(id2host)等。
到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
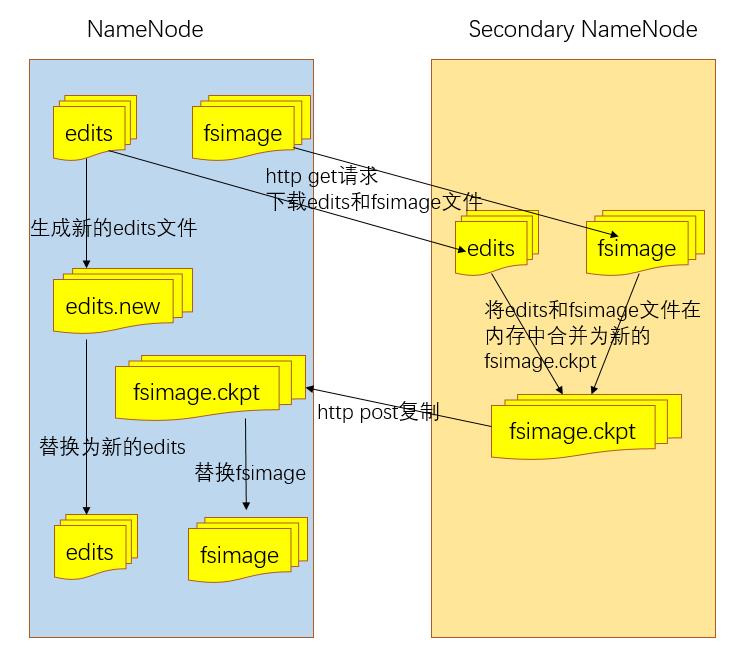
hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。此时Secondary namenode就派上用场了,合并fsimage和edits文件并更新NameNode的metedata。
Secondary namenode工作流程:
- secondary通知namenode切换edits文件
- secondary通过http请求从namenode获得fsimage和edits文件
- secondary将fsimage载入内存,然后开始合并edits
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage
通过一张图可以表示为:
文件下载
文件下载相对来说就简单一些了,如图所示,Client要从DataNode上,读取test.log文件。而test.log由block1和block2组成。

文件下载的主要流程为:
- client向namenode发送请求。
- namenode查看Metadata信息,返回test.log的block的位置。
Block1: h0,h1,h3
Block2: h0,h2,h4
- 开始从h0节点下载block1,block2。
源码分析
我们先简单使用hadoop提供的API来实现文件的上传下载(文件删除、改名等操作比较简单,这里不演示):
1 package cn.jon.hadoop.hdfs; 2 3 import java.io.FileInputStream; 4 import java.io.FileOutputStream; 5 import java.io.IOException; 6 import java.io.InputStream; 7 import java.io.OutputStream; 8 import java.net.URI; 9 import java.net.URISyntaxException; 10 11 import org.apache.hadoop.conf.Configuration; 12 import org.apache.hadoop.fs.FileSystem; 13 import org.apache.hadoop.fs.Path; 14 import org.apache.hadoop.io.IOUtils; 15 import org.junit.Before; 16 import org.junit.Test; 17 18 public class HDFSDemo { 19 FileSystem fs = null; 20 @Before 21 public void init(){ 22 try { 23 //初始化文件系统 24 fs = FileSystem.get(new URI("hdfs://hadoopmaster:9000"), new Configuration(), "root"); 25 } catch (IOException e) { 26 e.printStackTrace(); 27 } catch (InterruptedException e) { 28 e.printStackTrace(); 29 } catch (URISyntaxException e) { 30 e.printStackTrace(); 31 } 32 } 33 public static void main(String[] args) { 34 35 } 36 @Test 37 /** 38 * 文件上传 39 */ 40 public void testFileUpload(){ 41 try { 42 OutputStream os = fs.create(new Path("/test.log")); 43 FileInputStream fis = new FileInputStream("I://test.log"); 44 IOUtils.copyBytes(fis, os, 2048,true); 45 //可以使用hadoop提供的简单方式 46 fs.copyFromLocalFile(new Path("I://test.log"), new Path("/test.log")); 47 } catch (IllegalArgumentException | IOException e) { 48 e.printStackTrace(); 49 } 50 } 51 @Test 52 /** 53 * 文件下载 54 */ 55 public void testFileDownload(){ 56 try { 57 InputStream is = fs.open(new Path("/test.log")); 58 FileOutputStream fos = new FileOutputStream("E://test.log"); 59 IOUtils.copyBytes(is, fos, 2048); 60 //可以使用hadoop提供的简单方式 61 fs.copyToLocalFile(new Path("/test.log"), new Path("E://test.log")); 62 } catch (IllegalArgumentException | IOException e) { 63 e.printStackTrace(); 64 } 65 } 66 67 }
显而易见,只要是对hdfs上的文件进行操作,必须对FileSystem进行初始化,我们先来分析FileSystem的初始化:
1 public static FileSystem get(URI uri, Configuration conf) throws IOException { 2 return CACHE.get(uri, conf);//部分方法我只截取了部分代码,这里进入get()方法 3 }
1 FileSystem get(URI uri, Configuration conf) throws IOException{ 2 Key key = new Key(uri, conf); 3 return getInternal(uri, conf, key);//调用getInternal() 4 }
1 private FileSystem getInternal(URI uri, Configuration conf, Key key) throws IOException{ 2 //使用单例模式创建FileSystem,这是由于FS的初始化需要大量的时间,使用单例保证只是第一次加载慢一些,返回FileSystem的子类实现DistributedFileSystem 3 FileSystem fs; 4 synchronized (this) { 5 fs = map.get(key); 6 } 7 if (fs != null) { 8 return fs; 9 } 10 11 fs = createFileSystem(uri, conf); 12 synchronized (this) { // refetch the lock again 13 FileSystem oldfs = map.get(key); 14 if (oldfs != null) { // a file system is created while lock is releasing 15 fs.close(); // close the new file system 16 return oldfs; // return the old file system 17 } 18 19 // now insert the new file system into the map 20 if (map.isEmpty() 21 && !ShutdownHookManager.get().isShutdownInProgress()) { 22 ShutdownHookManager.get().addShutdownHook(clientFinalizer, SHUTDOWN_HOOK_PRIORITY); 23 } 24 fs.key = key; 25 map.put(key, fs); 26 if (conf.getBoolean("fs.automatic.close", true)) { 27 toAutoClose.add(key); 28 } 29 return fs; 30 } 31 }
1 public void initialize(URI uri, Configuration conf) throws IOException { 2 super.initialize(uri, conf); 3 setConf(conf); 4 5 String host = uri.getHost(); 6 if (host == null) { 7 throw new IOException("Incomplete HDFS URI, no host: "+ uri); 8 } 9 homeDirPrefix = conf.get( 10 DFSConfigKeys.DFS_USER_HOME_DIR_PREFIX_KEY, 11 DFSConfigKeys.DFS_USER_HOME_DIR_PREFIX_DEFAULT); 12 13 this.dfs = new DFSClient(uri, conf, statistics);//实例化DFSClient,并将它作为DistributedFileSystem的引用,下面我们跟进去 14 this.uri = URI.create(uri.getScheme()+"://"+uri.getAuthority()); 15 this.workingDir = getHomeDirectory(); 16 }
1 public DFSClient(URI nameNodeUri, ClientProtocol rpcNamenode, 2 Configuration conf, FileSystem.Statistics stats) 3 throws IOException { 4 //该构造太长,楼主只截取了重要部分给大家展示,有感兴趣的同学可以亲手进源码瞧瞧 5 NameNodeProxies.ProxyAndInfo<ClientProtocol> proxyInfo = null; 6 //这里声明了NameNode的代理对象,跟我们前面讨论的rpc就息息相关了 7 if (proxyInfo != null) { 8 this.dtService = proxyInfo.getDelegationTokenService(); 9 this.namenode = proxyInfo.getProxy(); 10 } else if (rpcNamenode != null) { 11 Preconditions.checkArgument(nameNodeUri == null); 12 this.namenode = rpcNamenode; 13 dtService = null; 14 } else { 15 Preconditions.checkArgument(nameNodeUri != null, 16 "null URI"); 17 proxyInfo = NameNodeProxies.createProxy(conf, nameNodeUri, 18 ClientProtocol.class, nnFallbackToSimpleAuth); 19 this.dtService = proxyInfo.getDelegationTokenService(); 20 this.namenode = proxyInfo.getProxy();//获取NameNode代理对象引用并自己持有,this.namenode类型为ClientProtocol,它是一个接口,我们看下这个接口 21 } 22 }
1 public interface ClientProtocol{ 2 public static final long versionID = 69L; 3 //还有很多对NameNode操作的方法申明,包括对文件上传,下载,删除等 4 //楼主特意把versionID贴出来了,这就跟我们写的RPCDemo中的MyBizable接口完全类似,所以说Client一旦拿到该接口实现类的代理对象(NameNodeRpcServer),Client就可以实现与NameNode的RPC通信,我们继续跟进 5 }
1 public static <T> ProxyAndInfo<T> createProxy(Configuration conf, 2 URI nameNodeUri, Class<T> xface, AtomicBoolean fallbackToSimpleAuth) 3 throws IOException { 4 AbstractNNFailoverProxyProvider<T> failoverProxyProvider = 5 createFailoverProxyProvider(conf, nameNodeUri, xface, true, 6 fallbackToSimpleAuth); 7 if (failoverProxyProvider == null) { 8 // 如果不是HA的创建方式,楼主环境是伪分布式,所以走这里,我们跟进去 9 return createNonHAProxy(conf, NameNode.getAddress(nameNodeUri), xface, 10 UserGroupInformation.getCurrentUser(), true, fallbackToSimpleAuth); 11 } else { 12 // 如果有HA的创建方式 13 Conf config = new Conf(conf); 14 T proxy = (T) RetryProxy.create(xface, failoverProxyProvider, 15 RetryPolicies.failoverOnNetworkException( 16 RetryPolicies.TRY_ONCE_THEN_FAIL, config.maxFailoverAttempts, 17 config.maxRetryAttempts, config.failoverSleepBaseMillis, 18 config.failoverSleepMaxMillis)); 19 return new ProxyAndInfo<T>(proxy, dtService, 20 NameNode.getAddress(nameNodeUri)); 21 } 22 }
最终返回的为ClientProtocol接口的子类代理对象,而NameNodeRpcServer类实现了ClientProtocol接口,因此返回的为NameNode的代理对象,当客户端拿到了NameNode的代理对象后,即与NameNode建立了RPC通信:
1 private static ClientProtocol createNNProxyWithClientProtocol( 2 InetSocketAddress address, Configuration conf, UserGroupInformation ugi, 3 boolean withRetries, AtomicBoolean fallbackToSimpleAuth) 4 throws IOException { 5 RPC.setProtocolEngine(conf, ClientNamenodeProtocolPB.class, ProtobufRpcEngine.class);//是不是感觉越来越像我们前面说到的RPC 6 7 final RetryPolicy defaultPolicy = 8 RetryUtils.getDefaultRetryPolicy(//加载默认策虐 9 conf, 10 DFSConfigKeys.DFS_CLIENT_RETRY_POLICY_ENABLED_KEY, 11 DFSConfigKeys.DFS_CLIENT_RETRY_POLICY_ENABLED_DEFAULT, 12 DFSConfigKeys.DFS_CLIENT_RETRY_POLICY_SPEC_KEY, 13 DFSConfigKeys.DFS_CLIENT_RETRY_POLICY_SPEC_DEFAULT, 14 SafeModeException.class); 15 16 final long version = RPC.getProtocolVersion(ClientNamenodeProtocolPB.class); 17 //看到versionId了吗?这下明白了rpc的使用中目标接口必须要有这个字段了吧 18 ClientNamenodeProtocolPB proxy = RPC.getProtocolProxy( 19 ClientNamenodeProtocolPB.class, version, address, ugi, conf, 20 NetUtils.getDefaultSocketFactory(conf), 21 org.apache.hadoop.ipc.Client.getTimeout(conf), defaultPolicy, 22 fallbackToSimpleAuth).getProxy(); 23 //看到没?这里使用 RPC.getProtocolProxy()来创建ClientNamenodeProtocolPB对象,调试时可以清楚的看见,该对象引用的是一个代理对象,值为$Proxy12,由JDK的动态代理来实现。 24 //前面我们写RPCDemo程序时,用的是RPC.getProxy(),但是各位大家可以去看RPC源码,RPC.getProtocolProxy()最终还是调用的getProxy() 25 if (withRetries) { 26 Map<String, RetryPolicy> methodNameToPolicyMap 27 = new HashMap<String, RetryPolicy>(); 28 ClientProtocol translatorProxy = 29 new ClientNamenodeProtocolTranslatorPB(proxy); 30 return (ClientProtocol) RetryProxy.create(//这里再次使用代理模式对代理对象进行包装,也可以理解为装饰者模式 31 ClientProtocol.class, 32 new DefaultFailoverProxyProvider<ClientProtocol>( 33 ClientProtocol.class, translatorProxy), 34 methodNameToPolicyMap, 35 defaultPolicy); 36 } else { 37 return new ClientNamenodeProtocolTranslatorPB(proxy); 38 } 39 }
整个FileSystem的初始化用时序图表示为:
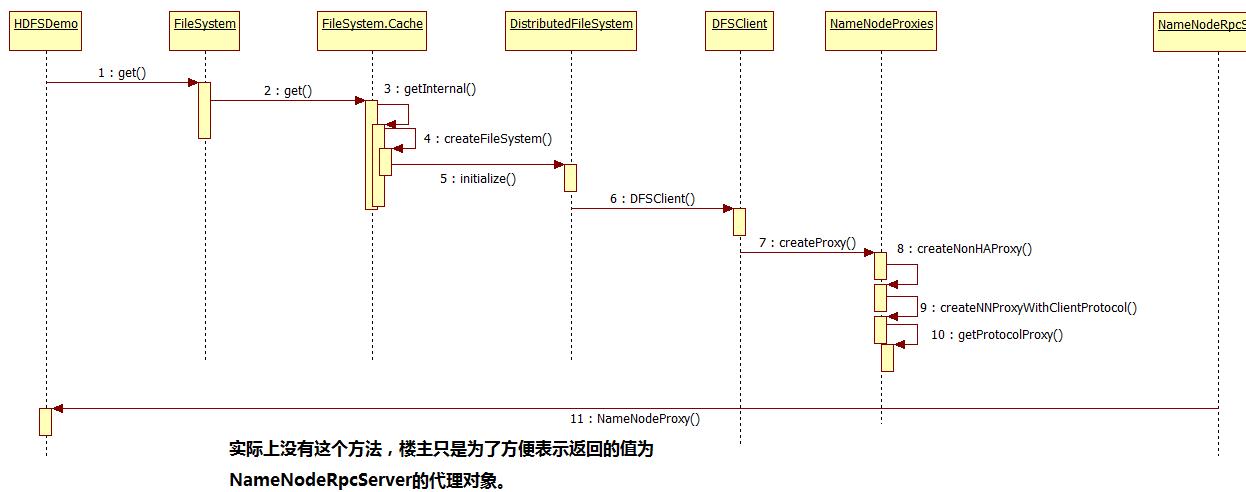
到此,FileSystem的初始化就基本完成。由于文章篇幅过大的问题,所以楼主把HDFS原理及源码分析拆分成了两部分,上半部分主要是HDFS原理与FileSystem的初始化介绍,那在下半部分将会具体介绍HDFS文件上传、下载的源码解析。
另外,文章用到的一些示例代码,将会在下半部分发布后,楼主一起上传到GitHub。
以上是关于Hadoop之HDFS原理及文件上传下载源码分析(上)的主要内容,如果未能解决你的问题,请参考以下文章