Hadoop源码分析之NameNode的目录构成与类继承结构
Posted 超人学院-CRXY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop源码分析之NameNode的目录构成与类继承结构相关的知识,希望对你有一定的参考价值。
与DataNode节点类似,NameNode节点也有自己的目录和类继承结构,但是NameNode节点的目录结构比DataNode节点就简单多了,下面就来简单分析NameNode节点的目录构成与类继承结构。
NameNode的目录构成在NameNode节点运行时,维护着整个HDFS中的文件及目录信息,如果NameNode出现故障,如掉电或进程崩溃,那么内存中的信息将全部丢失,因此必须将内存中的信息实时的保存在磁盘中,如果NameNode节点崩溃,那么在下次启动NameNode节点时可以重新从磁盘中加载文件及目录信息。在HDFS中使用命名空间镜像来保存内存中的某一个时刻的目录及文件信息,使用编辑日志来保存每次对内存中目录树的修改,之所以使用编辑日志,是因为如果每次目录树更改之后就将整个内存中的文件及目录信息导出到磁盘会增加NameNode的负担,内存中的数据过多时,可能这就称为NameNode的瓶颈了,但是NameNode的主要任务并不是导出内存中的数据,而是为其他节点提供服务,所以引入编辑日志来保存对目录树的修改,再定期合并镜像与编辑日志生成新的命名空间镜像,在HDFS中,这个过程由SecondaryNameNode节点完成。
NameNode节点在磁盘上维护着一个目录来保存命名空间镜像和编辑日志。名字节点允许将命名空间命名空间镜像和编辑日志保存在不同的目录项中,即名字节点管理的目录可以分为只保存命名空间镜像(由配置项${dfs.name.dir}指定)、只保存编辑日志(由配置项${dfs.name.edits.dir}指定)和同时保存命名空间镜像和编辑日志(在两个配置项中同时指定)三种情况。笔者环境没有配置${dfs.name.dir}属性和${dfs.name.edits.dir}属性,所以会默认保存在$hadoop/tmp/dfs/name目录下,该文件夹如下图所示:
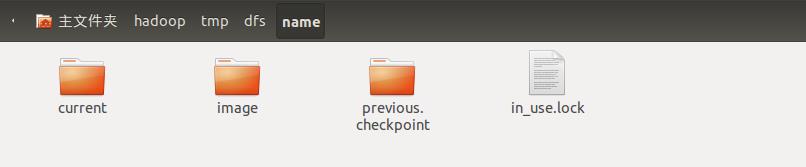
in_use.lock与DataNode节点上的in_use.lock文件类似,是在NameNode节点启动后产生的,保证该目录被独占方式打开,关闭NameNode节点之后,这个文件会被删除,previous.checkpoint保存NameNode节点的上一次检查点,目录结构与current目录一致,这个目录会在运行一段时间后产生。在第一次启动NameNode节点之前,需要使用命令hadoop namenode -format对NameNode节点进行格式化,这个格式化的过程只会产生current目录和image目录,其中current目录用与保存命名空间镜像和编辑日志,image目录是0.13版本及以前版本保存fsimage文件的目录,为防止不兼容问题而产生的目录。current目录结构如下图所示:
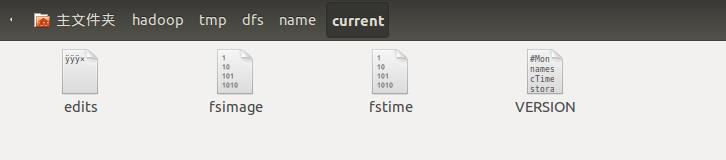
可以看到,这个目录有四个文件,其作用分别是:
- fsimage:元数据镜像文件,用于将内存中的文件目录树信息持久化到磁盘上面;
- edits:保存上文提到的编辑日志;
- fstime:保存了最近一次检查点的时间,检查点一般有SecondaryNameNode产生,是一次fsimage和edits的合并结果;
- VERSION:与DataNode节点中的VERSION文件类似,保存了NameNode节点的一些属性
上文的内容是关于名字节点存储内存中的文件目录树数据的,但是这些元数据信息如何在内存中组织呢?下面来分析HDFS在内存中组织这些元数据信息的类继承结构。
NameNode节点组织内存中数据的根类是INode,INode使用了类似与Linux操作系统中i-node索引节点的类似的命名方式,但是HDFS中的INode保存的信息比i-node少。INode类的继承结构如下图所示:
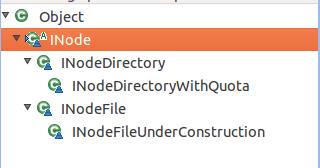
从上图中可以看到,INode的子类有INodeDirectory和INodeFile,其中INodeDirectory抽象了NameNode节点内存元数据信息的目录,INodeFile抽象了NameNode几点内存元数据信息的文件,与其他文件系统类似,文件目录中会保存文件,所以INodeDirectory的成员变量中有一个List<INode>类型的变量children,它保存文件和目录,即INodeDirectory下面会存在INodeDirectory对象和INodeFile对象。INodeDirectory有一个子类INodeDirectoryWithQuota,这个类代表一个带有配额的目录,即可以规定当前目录中包含多少文和目录,或者规定当前目录所能保存的文件占用多大的磁盘空间,如果超出配额,则会抛出异常信息。INodeFile也有一个子类INodeFileUnderConstruction,这个类表示正在处于构建中的文件,客户端为写或追加数据方式打开HDFS文件时,该文件就处于构建状态,在目录树中,相应的节点就是一个INodeFileUnderConstruction对象。下面分别对这几个类做简要分析。
INode类这是一个抽象类,类的定义和成员变量的代码如下:
- abstract class INode implements Comparable<byte[]>, FSInodeInfo {
- /**文件/目录名,如果name.length为0,则是根节点**/
- protected byte[] name;
- /**父目录**/
- protected INodeDirectory parent;
- /**最后修改时间**/
- protected long modificationTime;
- /**最后访问时间**/
- protected long accessTime;
- /**保存访问权限、文件主标识符、文件所在用户组标识符**/
- private long permission;
- }
这个类实现了两个接口Comparable和FSInodeInfo,有五个成员变量,其中name代表这个目录或者文件的名,如果name.leng为0,那么就是整个文件目录类树的根,它也就是一个目录即INodeDirectory对象,这里name属性是一个字节数组,为什么使用字节数组而不是字符串呢?个人觉得是因为字节数组更省空间。parent是一个INodeDirectory对象,代表这个目录或者文件的父目录,在整个文件目录树中之后根目录没有父目录。modificationTime表示这个文件或目录的最后修改时间,permission标识了文件或目录的访问权限,文件主标识符和文件所在用户组标识符,十一个long类型的变量,如何使用一个long类型的变量来保存三种信息呢?一个long变量是64位,那么就可以将这64位划分成3个部分,用这三个部分来表示三种信息,在INode类中有一个枚举类型PermissionStatusFormat,这个类定义了HDFS中的文件或目录的[访问权限、文件主标识符、文件所在用户组标识符]这三类信息,代码如下:
- private static enum PermissionStatusFormat {
- /**访问权限,从第0位开始,长度为16位,即0~15位**/
- MODE(0, 16),
- /**用户组标识,从第16位开始,长度位25位,即16~40位**/
- GROUP(MODE.OFFSET + MODE.LENGTH, 25),
- /**文件主标识,从第41位开始,长度位23,即41~63**/
- USER(GROUP.OFFSET + GROUP.LENGTH, 23);
- final int OFFSET;
- final int LENGTH; //bit length
- final long MASK;
- PermissionStatusFormat(int offset, int length) {
- OFFSET = offset;
- LENGTH = length;
- MASK = ((-1L) >>> (64 - LENGTH)) << OFFSET;
- }
- long retrieve(long record) {
- return (record & MASK) >>> OFFSET;
- }
- long combine(long bits, long record) {
- return (record & ~MASK) | (bits << OFFSET);
- }
- }
在PermissionStatusFormat类中定义了三个枚举值,其意义分别是:
- MODE:代表访问权限,为64为long类型数据的第0~15位,长度是16位,即这16位的值代表了访问权限;
- GROUP:代表用户组标识从第16位开始,长度为25位即比特位的16~40位;
- USER:文件主标识,即文件创建者的标识,从长度为23位,即比特位的41~63位;
在PermissionStatusFormat类中有三个final类型的值,其中OFFSET表示PermissionStatusFormat对象的值从哪个位开始,MODE类型就是从第0位开始,length表示比特位的长度,MASK表示掩码,这里掩码的作用与计算机网络中掩码的作用类似,即对于PermissionStatusFormat.MODE值,掩码的第0~15位都是1,其他位都是0,对于PermissionStatusFormat.GROUP值,掩码的第16~40位都是1,其他位都是0,对于PermissionStatusFormat.USER值,掩码的第41~63位都是1,其他位都是0,所以在PermissionStatusFormat的构造方法中,掩码的运算表达式是MASK = ((-1L) >>> (64 - LENGTH)) << OFFSET;,-1的所有比特位都是1,所以先无符号右移64-LENGTH位,再左移OFFSET位,这样就得到了掩码。
HDFS中用户组标识对应者用户组名,用户标识对应这用户名,而PermissionStatusFormat枚举的三个值都是使用比特位来表示,那么如何使用比特位表示呢?HDFS做法是使用SerialNumberManager类来保存用户名和用户组名,这样使用SerialNumberManager类来进行标识和名的对应转换。
INodeDirectory类INodeDirectory类抽象了HDFS中的目录,目录中还会保存子目录和文件,所以INodeDirectory就是一中虚拟容器,其部分代码如下所示:
- class INodeDirectory extends INode {
- protected static final int DEFAULT_FILES_PER_DIRECTORY = 5;
- final static String ROOT_NAME = "";
- /**该目录中的文件/目录**/
- private List<INode> children;
- }
常量ROOT_NAME表示根目录的目录名,会赋值给INode类中的name变量(创建根目录是在FSDirectory类的构造方法中),children变量表示该目录下的子目录和文件的集合,常量DEFAULT_FILES_PER_DIRECTORY表示默认每个目录中有5个我而建或目录,在初始化children时,这个集合的默认大小就是DEFAULT_FILES_PER_DIRECTORY。
INodeDirectory类还有一个子类INodeDirectoryWithQuota,表示带有配额的目录。HDFS允许管理员位每个目录设置配额,配额分两种:
- 节点配额:用于限制目录下名字数量,如果创建文件或目录时超过了该配额,操作会失败。这个配额用于控制用户对名字节点资源占用,保存在成员变量nsQuota中;
- 空间配额:限制存储在该目录树中所有文件的总规模,空间配额保证用户不会占用数据节点的资源,该配额由dsQuota保存;
其定义代码如下:
- class INodeDirectoryWithQuota extends INodeDirectory {
- private long nsQuota; /// NameSpace quota
- private long nsCount;
- private long dsQuota; /// disk space quota
- private long diskspace;
- }
ndCount和diskspace分别记录当前目录中子文件名字的使用量和磁盘空间的使用量。正常运行中,这两个值必须分别小于nsQuota和dsQuota。
INodeFile类
INodeFIle类抽象类HDFS中的文件,其部分定义代码如下:
- class INodeFile extends INode {
- static final FsPermission UMASK = FsPermission.createImmutable((short)0111);
- //Number of bits for Block size
- static final short BLOCKBITS = 48;
- //Header mask 64-bit representation
- //Format: [16 bits for replication][48 bits for PreferredBlockSize]
- static final long HEADERMASK = 0xffffL << BLOCKBITS;
- /**使用了和INode.permission一样的方法,在一个长整型变量里保存了文件的副本系数和文件数据块的大小,它的高16位存放这副本系数,低48位存放了数据块大小。**/
- protected long header;
- /**文件拥有的数据块**/
- protected BlockInfo blocks[] = null;
- }
由于HDFS中的文件是分块存储的,并且一个文件的多个数据块可能保存在不同的机器上,所以每个文件必须记录它的所有数据块信息。INodeFile包含两个成员变量header和blocks。header是一个long型变量,它也是在一个长整型变量中保存类文件副本系统和文件数据块的大小,64个比特位中,高16位保存的是副本系数,低48位保存的是数据块大小信息。blocks是一个数组类型,每个元素代表一个数据块,数据块是BlockInfo类型。INodeFile类有三个常量,其中BLOCKBITS表示块大小占用长整型变量的48个比特位,HEADERMASK是header变量的掩码,定义位值0xffffL向左移48位,用于求header的高16位值。
INodeFileUnderConstruction类是INodeFile的子类,用于表示处于构建状态的文件。其定义的部分代码如下:
- /**
- * 代表了一个为写而打开的文件,用于向HDFS写文件的过程中
- *
- */
- class INodeFileUnderConstruction extends INodeFile {
- /**写文件的客户端,也是这个文件租约文件的所有者**/
- String clientName; // lease holder
- /**客户端所在的主机**/
- private final String clientMachine;
- /**如果客户端运行在集群内的某个数据节点上,数据节点的信息**/
- private final DatanodeDescriptor clientNode; // if client is a cluster node too.
- /**租约恢复时的主数据节点**/
- private int primaryNodeIndex = -1; //the node working on lease recovery
- /**最后一个数据块的数据流管道成员**/
- private DatanodeDescriptor[] targets = null; //locations for last block
- /**租约恢复的开始时间**/
- private long lastRecoveryTime = 0;
- }
这个类具体的分析在以后分析客户端向HDFS中写入文件的时候再来分析。
总结
上面分析类NameNode的目录结构和使用到的部分类的继承结构,目录结构与DataNode目录结构类似,主要用于持久化NameNode节点中的内存信息到磁盘中,以防NameNode节点故障发生。以INode为根的类结构形象化的抽象了HDFS中的文件与目录,NameNode节点内存中的目录树正式由这些类构成,NameNode节点内存数据的持久化,也是针对这些数据的持久化。
以上是关于Hadoop源码分析之NameNode的目录构成与类继承结构的主要内容,如果未能解决你的问题,请参考以下文章