HDFS源码学习纪录之-NameNode篇
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS源码学习纪录之-NameNode篇相关的知识,希望对你有一定的参考价值。
NameNode维护了HDFS命名空间的两层关系:
1) 文件与数据块之间的关系(INodeFile,INodeDirectory)
2) 数据块与DataNode之间的关系(BlockMap.BlockInfo)
首先,贴一张类图:
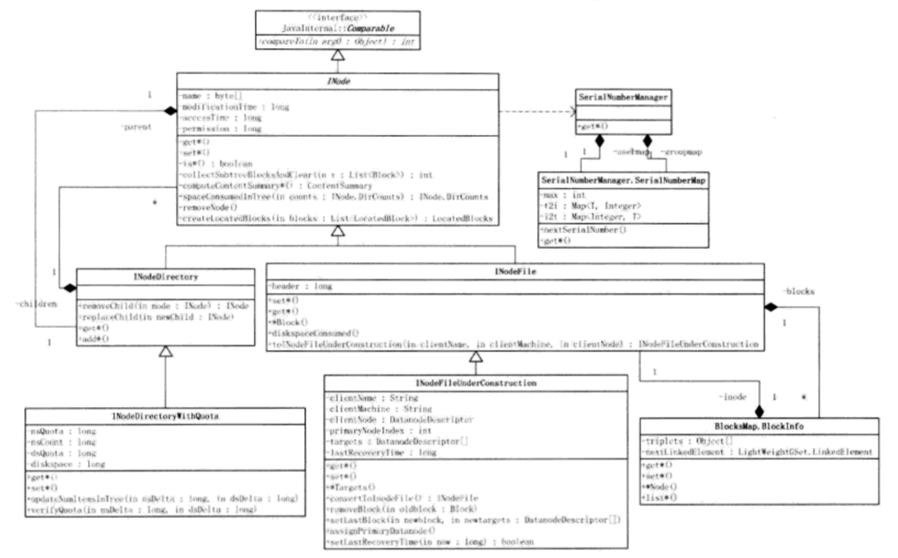
1. INode类:
INode模仿Linux文件系统中的索引节点inode。INode为一个抽象类,INode中保存了文件名,文件所有者,文件的访问权限,文件父目录(INodeDirectory引用,无论是INode的INodeFile子类还是INodeDirectory子类,都拥有父目录),修改时间,访问时间等。而INode中关键方法列举如下:
1) removeNode,将文件自己从父目录中删除。调用INodeDirectory的removeChild方法从父母中删除子文件。
boolean removeNode() { if (parent == null) { return false; } else { parent.removeChild(this); parent = null; return true; } }
2) isUnderConstruction方法判断此INode所代表的文件是否在构建中(被写),默认情况下INode作为父类,返回的值都为false,而下文所讲的INodeUnderConstruction子类继承INode并重写了isUnderConstruction方法,返回true。
/** * Is this inode being constructed? */ boolean isUnderConstruction() { return false; }
2. INodeFile类
INodeFile为INode的子类,表示一个具体文件。INodeFile中保存的blocks表示构成文件的一系列数据块,其中BlockInfo类继承与Block类,其中不仅包含了该block对应的INode,而且包含了该块所处的DataNode(DataNodeDescriptor)。后文会再讲到BlockInfo类。INodeFile类中保存的long型属性header保存了block的副本数和建议的块大小。
//Header mask 64-bit representation //Format: [16 bits for replication][48 bits for PreferredBlockSize] static final long HEADERMASK = 0xffffL << BLOCKBITS; protected long header; protected BlockInfo blocks[] = null;
collectSubtreeBlocksAndClear方法为INode抽象类中的抽象方法,INodeFile类与INodeDirectory类具体实现了该抽象方法。INodeFile类中的collectSubtreeBlocksAndClear方法实现简单,将INodeFile中的block数组设为空,同时将删除的blocks中的每个block加入collectSubtreeBlocksAndClear方法的参数。
int collectSubtreeBlocksAndClear(List<Block> v) { parent = null; for (Block blk : blocks) { v.add(blk); } blocks = null; return 1; }
3. INodeDirectory类
INodeDirectory中保存了Inode的列表,保存了目录下的每个子文件的INode。而INodeDirectory本身并不包含Block。
private List<INode> children;
INodeDirectory中的collectSubtreeBlocksAndClear方法如下:
int collectSubtreeBlocksAndClear(List<Block> v) { int total = 1; if (children == null) { return total; } for (INode child : children) { total += child.collectSubtreeBlocksAndClear(v); } parent = null; children = null; return total; }
实现是通过遍历INodeDirectory的children(子目录/文件),并递归的调用INode.collectSubtreeBlocksAndClear方法,删除子目录,目录下的文件。并统计所有清除的子目录,子文件的数目,total变量返回。
4. INodeDirectoryWithQuota类
INodeDirectoryWithQuota类继承于INodeDirectory类,管理员可以配置目录的配额。既可以配置目录下的名字数量,也可以配置子目录下的所有文件的空间配额。
class INodeDirectoryWithQuota extends INodeDirectory { private long nsQuota; /// NameSpace quota命名空间配额,指代目录文件总数 private long nsCount; private long dsQuota; /// disk space quota磁盘空间配额 private long diskspace;
··· }
5. INodeFileUnderConstruction类
INodeFileUnderConstruction类继承于INodeFile类,表示处于构建状态的INode,当客户端为写或追加打开文件时,该文件就变为构建状态,在HDFS的目录树中,该节点就为一个INodeFileUnderConstruction对象。
class INodeFileUnderConstruction extends INodeFile { String clientName; // lease holder 租约持有者 private final String clientMachine;//客户端所在主机 private final DatanodeDescriptor clientNode; // if client is a cluster node too.如果客户端运行于集群中的机器,表示数据节点的信息 private int primaryNodeIndex = -1; //the node working on lease recovery private DatanodeDescriptor[] targets = null; //locations for last block最后一个块的数据流管道成员 private long lastRecoveryTime = 0;//租约恢复的开始时间
...... }
租约为客户端提供一定时间内的写操作的权限。相当于写锁。clientName表示发起写操作的客户端名称,即持有租约的客户端名称。clientMachine客户端所在主机。clientNode指,若客户端是运行于集群中的节点,则该变量表示该节点。targets表示最后一个数据块的数据流管道成员。primaryNodeIndex与lastRecoveryTime用于数据块恢复(租约恢复)。
INodeFileUnderConstruction调用isUnderConstruction来判断此文件是否正在被构建。
/** * Is this inode being constructed? */ @Override boolean isUnderConstruction() { return true; }
以上是关于HDFS源码学习纪录之-NameNode篇的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop源码分析之NameNode的目录构成与类继承结构
大数据技术之_04_Hadoop学习_01_HDFS_HDFS概述+HDFS的Shell操作(开发重点)+HDFS客户端操作(开发重点)+HDFS的数据流(面试重点)+NameNode和Seconda