Hive实战
Posted 北京小辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive实战相关的知识,希望对你有一定的参考价值。
目录:
一、Hive是什么
二、Hive与关系数据库的区别
三、Hive架构介绍
四、Hive的实战操作
1) HIVE的启动
2) Hive创建数据库
3) Hive删除数据库
4) 创建HIVE表添加数据
5) HIVE的分区
6) HIVE条件查询
7) UDF函数
8) 删除HIVE表
9) 查询结果保存到本地
10) Hive的常用命令
“无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。”。
一、Hive是什么
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
二、Hive与关系数据库的区别
1) hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
2) hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
3) 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大的不同;
4) Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比hive差很多。
三、Hive架构介绍
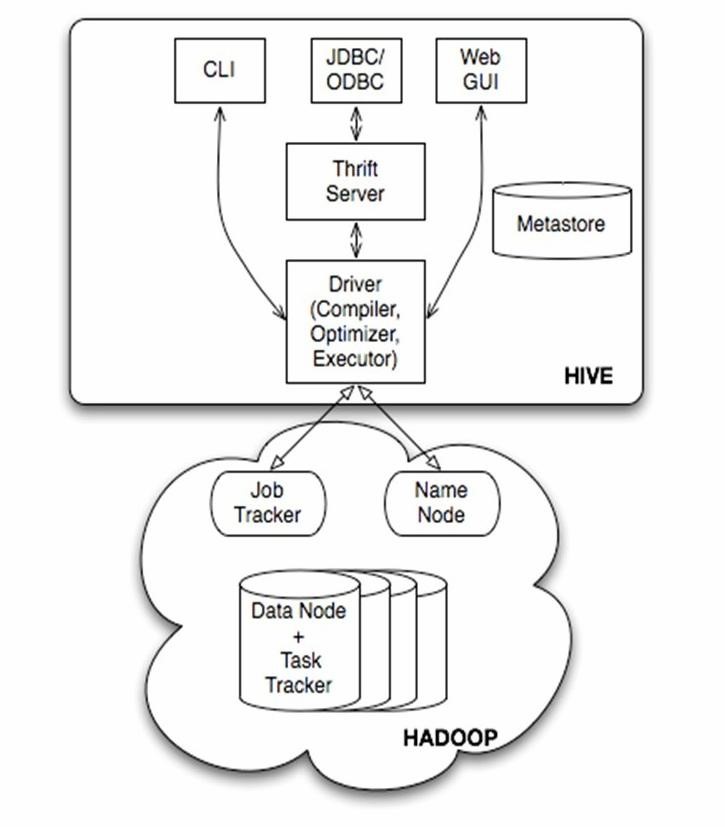
Hive的体系结构可以分为以下几部分:
(1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive将元数据存储在RDBMS中,
四、Hive的实战操作
1) HIVE的启动
[root@hadoop11 bin]# ls
beeline ext hive hive-config.sh hiveserver2 metatool schematool
[root@hadoop11 bin]# pwd
/usr/app/hive-0.12.0/bin
[root@hadoop11 bin]# sh /usr/app/hive-0.12.0/bin/hive
2) Hive创建数据库
Hive是一种数据库技术,可以定义数据库和表来分析结构化数据。主题结构化数据分析是以表方式存储数据,并通过查询来分析。本章介绍如何创建Hive 数据库。配置单元包含一个名为 default 默认的数据库。
CREATE DATABASE语句
创建数据库是用来创建数据库在Hive中语句。在Hive数据库是一个命名空间或表的集合。此语法声明如下:
CREATE DATABASE|SCHEMA [IF NOT EXISTS]<database name>
在这里,IF NOT EXISTS是一个可选子句,通知用户已经存在相同名称的数据库。可以使用SCHEMA 在DATABASE的这个命令。下面的查询执行创建一个名为userdb数据库:
hive> CREATE DATABASE [IF NOT EXISTS] userdb;
hive> CREATE DATABASE userdb;
下面的查询用于验证数据库列表:
hive>SHOW DATABASES;
default
userdb
hive> use default;
OK
Time taken: 0.114 seconds
hive> show tables;
OK
people
test
Time taken: 0.404 seconds, Fetched: 2 row(s)
hive>
3) Hive删除数据库
DROP DATABASE语句
DROP DATABASE是删除所有的表并删除数据库的语句。它的语法如下:
DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name
[RESTRICT|CASCADE];
下面的查询用于删除数据库。假设要删除的数据库名称为userdb。
hive> DROP DATABASE IF EXISTS userdb;
以下是使用CASCADE查询删除数据库。这意味着要全部删除相应的表在删除数据库之前。
hive> DROP DATABASE IF EXISTS userdb CASCADE;
以下使用SCHEMA查询删除数据库。
hive> DROP SCHEMA userdb;
4) 创建HIVE表添加数据
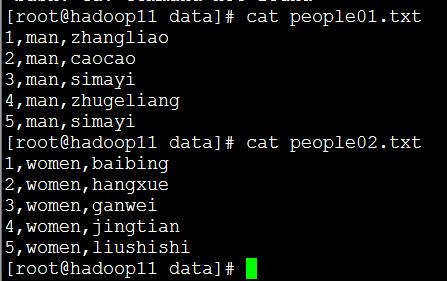
| people01.txt | people02.txt |
|---|---|
| 1,man,zhangliao | 1,women,baibing |
| 2,man,caocao | 2,women,hangxue |
| 3,man,simayi | 3,women,ganwei |
| 4,man,zhugeliang | 4,women,jingtian |
| 5,man,simayi | 5,women,liushishi |
hadoop fs -mkdir /usr/yuhui/hive
hadoop fs -mkdir /usr/yuhui/hive/20170309
hadoop fs -mkdir /usr/yuhui/hive/20170309/00
hadoop fs -mkdir /usr/yuhui/hive/20170310
hadoop fs -mkdir /usr/yuhui/hive/20170310/00



5) HIVE的分区
//添加数据到HDFS
[root@hadoop11 data]# hadoop fs -put people01.txt /usr/yuhui/hive/20170309/00/
[root@hadoop11 data]# hadoop fs -put people02.txt /usr/yuhui/hive/20170310/00/
//建立hive和Hdfs的外部关联表
hive> CREATE EXTERNAL TABLE people(id int,sex string,name string) partitioned by (logdate string,hour string) row format delimited fields terminated by ',';
hive> show tables;
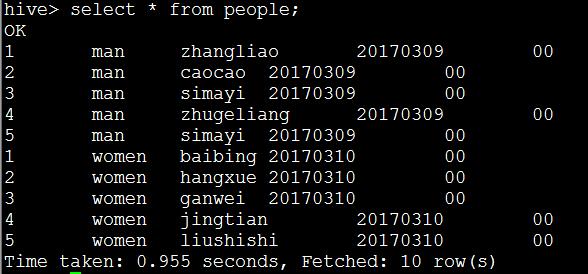
hive> select * from people;
//追加数据
hive> ALTER TABLE people ADD IF NOT EXISTS PARTITION(logdate=20170309,hour=00)LOCATION
'/usr/yuhui/hive/20170309/00';
hive> ALTER TABLE people ADD IF NOT EXISTS PARTITION(logdate=20170310,hour=00)LOCATION
'/usr/yuhui/hive/20170310/00';
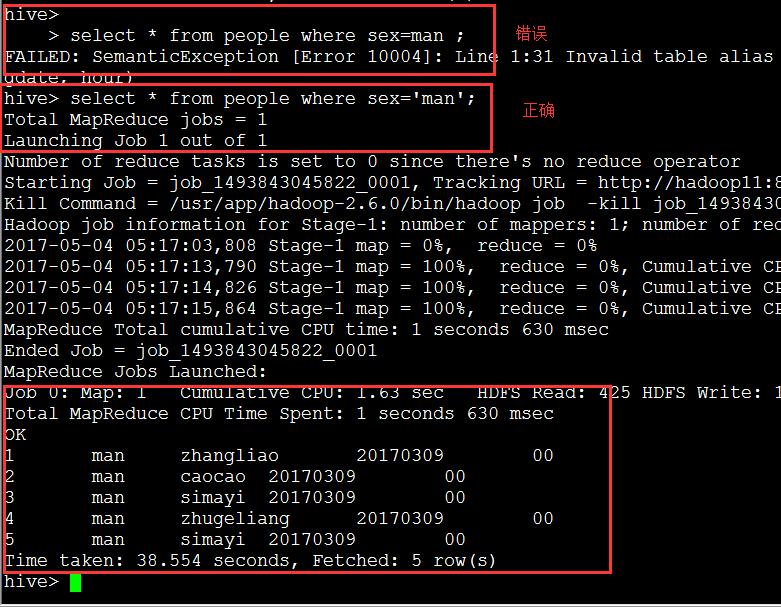
6) HIVE条件查询
查分区不用【引号】
hive> select * from people where logdate=20170310;
OK
1 women baibing 20170310 00
2 women hangxue 20170310 00
3 women ganwei 20170310 00
4 women jingtian 20170310 00
5 women liushishi 20170310 00
Time taken: 0.64 seconds, Fetched: 5 row(s)
查条件用【引号】
7) UDF函数
package cn.orcale.com.bigdata.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class helloUDF extends UDF {
public String evaluate(String sex , String name) {
try {
if(sex.equals("man")){
return sex +" ===> "+ name;
}
return sex +" ===> "+ name;
}
catch (Exception e) {
return null;
}
}
}
//ADD JAR helloUDF.jar;
//create temporary function helloworld as 'cn.orcale.com.bigdata.hive.helloUDF';
//select helloworld(people.sex, people.name) from people ;
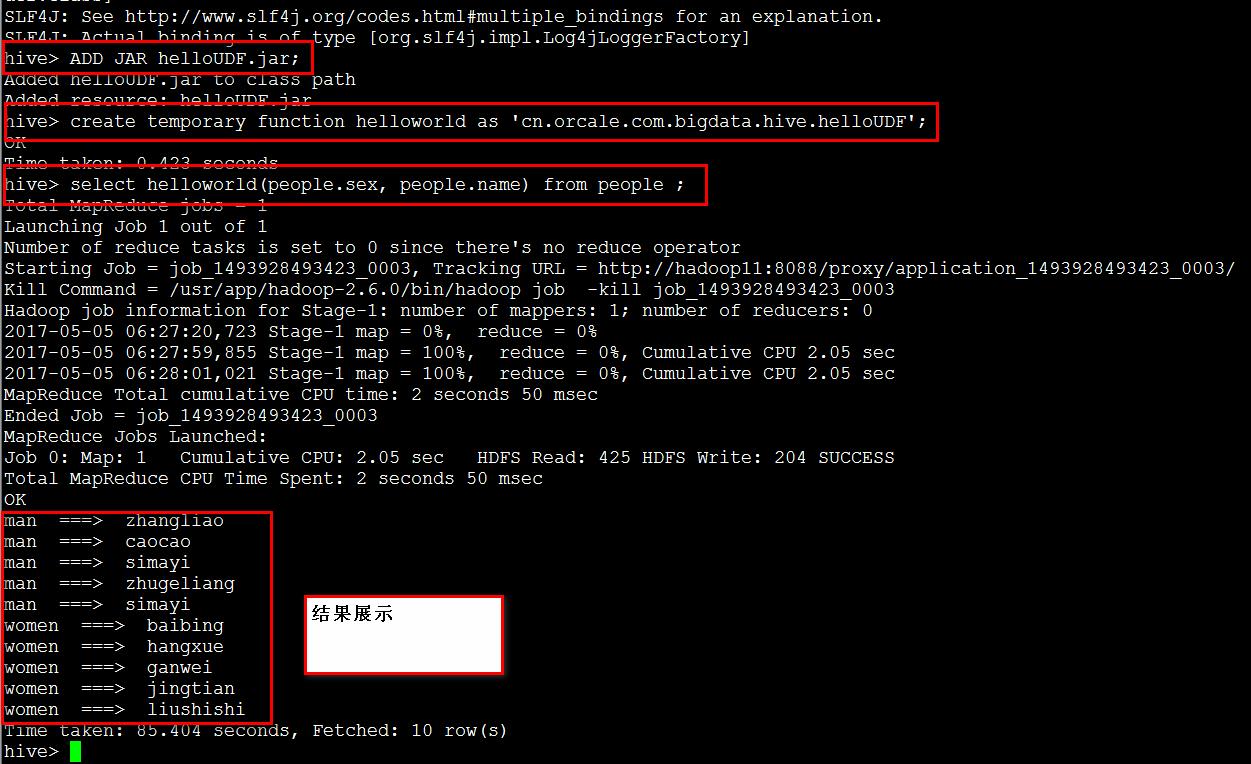
8) 删除HIVE表
hive> drop table people;
OK
Time taken: 1.593 seconds
hive> SHOW TABLES;
OK
test
9) 查询结果保存到本地
hive> INSERT OVERWRITE LOCAL DIRECTORY '/root/data/hivedata' SELECT * FROM people;
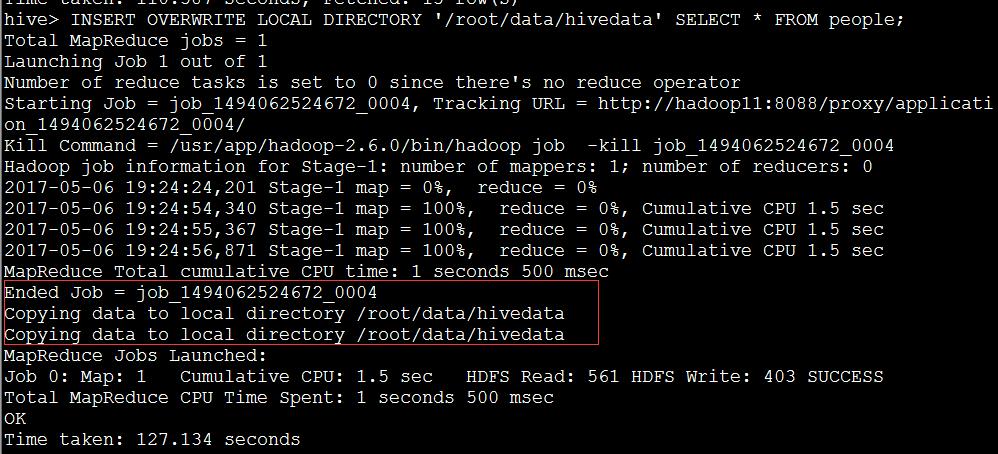
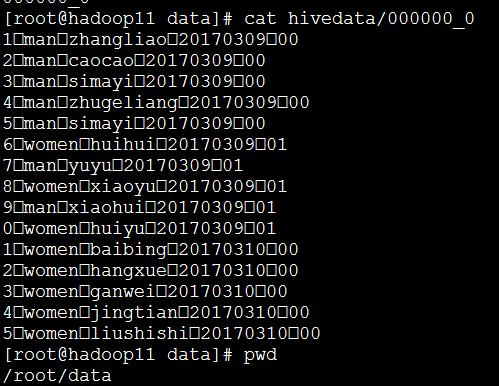
10) Hive的常用命令
创建新表
hive> CREATE TABLE t_hive (a int, b int, c int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\\t’;
导入数据t_hive.txt到t_hive表
hive> LOAD DATA LOCAL INPATH ‘/home/cos/demo/t_hive.txt’ OVERWRITE INTO TABLE t_hive ;
正则匹配表名
hive>show tables ‘t‘;
增加一个字段
hive> ALTER TABLE t_hive ADD COLUMNS (new_col String);
重命令表名
hive> ALTER TABLE t_hive RENAME TO t_hadoop;
从HDFS加载数据
hive> LOAD DATA INPATH ‘/user/hive/warehouse/t_hive/t_hive.txt’ OVERWRITE INTO TABLE t_hive2;
从其他表导入数据
hive> INSERT OVERWRITE TABLE t_hive2 SELECT * FROM t_hive ;
创建表并从其他表导入数据
hive> CREATE TABLE t_hive AS SELECT * FROM t_hive2 ;
仅复制表结构不导数据
hive> CREATE TABLE t_hive3 LIKE t_hive;
通过Hive导出到本地文件系统
hive> INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/t_hive’ SELECT * FROM t_hive;
Hive查询HiveQL
from ( select b,c as c2 from t_hive) t select t.b, t.c2 limit 2;
select b,c from t_hive limit 2;

以上是关于Hive实战的主要内容,如果未能解决你的问题,请参考以下文章
项目实战——参数配置化Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本)
项目实战——参数配置化Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本)