手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark相关的知识,希望对你有一定的参考价值。
文章目录
引言
大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,一个平凡而不平庸的人。
1.第一章 综合实战概述
数据管理平台(Data Management
Platform,简称DMP),能够为广告投放提供人群标签进行受众精准定向,并通过投放数据建立用户画像,进行人群标签的管理以及再投放。
各大互联网公司都有自己的DMP平台,用户广告精准投放营销,比如字节跳动产品今日头条、抖音短视频等主要是通过广告推广盈利,BAT公司DMP平台:
1、百度DMP智选:http://dmp.baidu.com/static/index.html
2、淘宝达摩盘(DMP营销平台):https://dmp.taobao.com/
3、腾讯DMP:https://dmp.qq.com/
4、品友互动DMP:http://www.ipinyou.com.cn/dmp
5、微博广告DMP平台:https://tui.weibo.com/platform/dmp

业务需求
对广告数据进行初步ETL处理和业务报表统计分析,整体业务需求如下图所示:
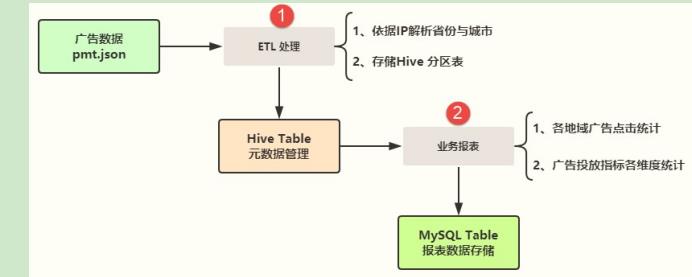
两个主要方面的业务:
⚫ 第一个、数据【ETL 处理】
◼依据IP地址,调用第三方库解析为省份province和城市city;
◼将ETL后数据保存至PARQUET文件(分区)或Hive 分区表中;
⚫ 第二个、数据【业务报表】
◼读取Hive Table中广告数据,按照业务报表需求统计分析,使用DSL编程或SQL编程;
◼将业务报表数据最终存储mysql Table表中,便于前端展示;
上述两个业务功能的实现,使用SparkSQL进行完成,最终使用Oozie和Hue进行可视化操作调用程序ETL和Report自动执行。
环境搭建
整个综合实战主要结合广告业务数据及简单报表需求,熟悉SparkCore和SparkSQL如何进行离线数据处理分析,整合其他大数据框架综合应用,需要准备大数据环境及应用开发环境。
大数据环境
通过上述业务需求分析可知,涉及到如下软件安装,全部安装在一台虚拟机中,部署伪分布式环境,建议虚拟机内存大小至少为4GB。
1)、基础软件:jdk1.8.0_241、scala-2.11.12、MySQL-8.0.19 2) 、 大 数 据 软 件 :
hadoop-2.6.0-cdh5.16.2 、 hive-1.1.0-cdh5.16.2 、
spark-2.4.5-bin-cdh5.16.2-2.11 、
oozie-4.1.0-cdh5.16.2、hue-3.9.0-cdh5.16.2
针对此离线综合实战来说,大数据环境已经部署完成,打开虚拟机【spark-node01】,进入快照管理,选择恢复至【7、Spark 离线综合实战】即可。
启动各个框架服务命令如下,开发程序代码时为本地模式LocalMode运行,测试生产部署为
YARN集群模式运行,集成Hive用于进行表的元数据管理,使用Oozie和Hue调度执行程序:
# Start HDFS
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode
# Start YARN
yarn-daemon.sh start resourcemanager yarn-daemon.sh start nodemanager
# Start MRHistoryServer
mr-jobhistory-daemon.sh start historyserver
# Start Spark HistoryServer
/export/server/spark/sbin/start-history-server.sh
# Start Oozie和Hue
oozied.sh start hue-daemon.sh start
# Start HiveMetaStore 和 HiveServer2
hive-daemon.sh metastore
# Start Spark JDBC/ODBC ThriftServer
/export/server/spark/sbin/start-thriftserver.sh \\
--hiveconf hive.server2.thrift.port=10000 \\
--hiveconf hive.server2.thrift.bind.host=node1.itcast.cn \\
--master local[2]
# Start Beeline
/export/server/spark/bin/beeline -u jdbc:hive2://node1.itcast.cn:10000 -n root -p 123456
启动SparkSQL JDBC/ODBC ThriftServer 分布式SQL引擎,使用beeline命令行客户端连接(也可以使用其他可视化工具连接),方便对Hive表数据管理及开发测试。
2.第二章 广告数据 ETL
实际企业项目中,往往收集到数据,需要进一步进行ETL处理操作,保存至数据仓库中,此【综合实战】对广告数据中IP地址解析为省份和城市,最终存储至Hive分区表中,业务逻辑如下:
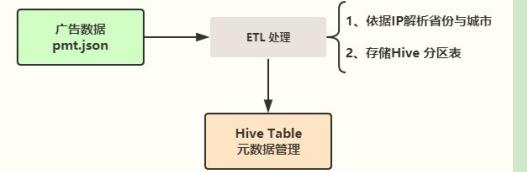
其中涉及两个核心步骤:
⚫ 第一个、IP地址解析,使用第三方库完成;
⚫ 第二个、存储ETL数据至Hive分区表,采用列式Parquet存储;
2.1IP 地址解析
解析IP地址为【省份、城市】,推荐使用【ip2region】第三方工具库, 准确率99.9%的离线IP 地址定位库,0.0x毫秒级查询,ip2region.db数据库只有数MB,提供了java、php、c、python、nodejs、golang、c#等查询绑定和Binary、B树、内存三种查询算法。
官网网址:https://gitee.com/lionsoul/ip2region/,引入使用IP2Region第三方库:
⚫ 第一步、复制IP数据集【ip2region.db】到工程下的【dataset】目录
⚫ 第二步、在Maven中添加依赖
<!-- 根据ip转换为省市区 -->
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
⚫ 第三步、ip2region的使用

2.2Hive 表创建
将广告数据ETL后保存到Hive 分区表中,启动Hive交互式命令行【$HIVE_HOME/bin/hive】
(必须在Hive中创建,否则有问题),创建数据库【itcast_ads】和表【pmt_ads_info】。
2.3数据ETL
编写Spark Application类:PmtEtlRunner,完成数据ETL操作,主要任务三点:
/**
*广告数据进行ETL处理,具体步骤如下:
*第一步、加载json数据
*第二步、解析IP地址为省份和城市
*第三步、数据保存至Hive表
*/
全部基于SparkSQL中DataFrame数据结构,使用DSL编程方式完成,其中涉及到DataFrame 转换为RDD方便操作,对各个部分业务逻辑实现,封装到不同方法中:
⚫第一点、解析IP地址为省份和城市,封装到:processData方法,接收DataFrame,返回DataFrame

⚫第二点、保存数据DataFrame至Hive表或Parquet文件,封装到:saveAsHiveTable或
saveAsParquet方法,接收DataFrame,无返回值Unit

运行完成以后,启动Spark JDBC/ODBC ThriftServer服务,beeline客户端连接,查看表分区和数据条目数:

实现代码:
ETL.scala
package src.main.scala.cn.itcast.spark.etl
import java.sql.PreparedStatement
import java.text.SimpleDateFormat
import java.util.{Date, Properties}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
import org.lionsoul.ip2region.{DbConfig, DbSearcher}
import org.spark_project.jetty.client.api.Connection
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.storage.StorageLevel
//import cn.itcast.spark.config.ApplicationConfig
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
/**
* @author ChinaManor
* #Description SparkJson
* #Date: 28/4/2021 12:43
*/
object ETL {
def SaveToMysql(count_Region: DataFrame) = {
count_Region.persist(StorageLevel.MEMORY_AND_DISK)
// 保存结果数据至MySQL表中
val props = new Properties()
props.put("user", "root")
props.put("password", "123456")
props.put("driver", "com.mysql.cj.jdbc.Driver")
count_Region
.coalesce(1) // 对结果数据考虑降低分区数
.write
.mode(SaveMode.Overwrite)
.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&userUnicode=true",
"itcast_ads_report.region_stat_analysis",
props)
}
def printToHive(resultFrame: DataFrame): Unit ={
resultFrame
.write
.format("hive")
.mode(SaveMode.Overwrite)
.partitionBy("date_str")
.saveAsTable("itcast_ads.pmt_ads_info")
}
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.appName("isDemo")
.master("local[2]")
.enableHiveSupport()
.config("hive.metastore.uris", "thrift://node1.itcast.cn:9083")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
.getOrCreate()
import sparkSession.implicits._
/**
* 广告数据进行ETL处理,具体步骤如下:
* 第一步、加载json数据
* 第二步、解析IP地址为省份和城市
* 第三步、数据保存至Hive表
**/
//TODO 2.解析IP地址为省份和城市
val df: DataFrame = sparkSession.read.json("src/main/dataset/pmt.json")
val etlRDD: RDD[(String, String)] = df.rdd.mapPartitions(partition => {
val dbSearcher = new DbSearcher(new DbConfig(), "src/main/dataset/ip2region.db")
partition.map(item => {
val ip: String = item.getAs[String]("ip")
(ip, dbSearcher.binarySearch(ip).getRegion)
})
})
df.printSchema()
df.show(10,truncate = false)
// 获取前一天数据
val ipDateStr: RDD[(String, String, String, String)] = etlRDD.map(item => {
val strings: Array[String] = item._2.split("\\\\|")
val format = new SimpleDateFormat("yyyy-MM-dd")
val date_str: String = format.format(new Date(new Date().getTime - 1000 * 60*60 * 24))
(item._1, strings(2), strings(3), date_str)
})
val dataFrame: DataFrame = ipDateStr.toDF("sip","province","city","date_str")
//TODO 3. RDD转换DF
dataFrame.createOrReplaceTempView("dFView")
df.createOrReplaceTempView("df_view")
val dFrame: DataFrame = sparkSession.sql(
"""
SELECT * FROM dfview,df_view WHERE dFView.sip=df_view.ip
""".stripMargin)
val resultframe: DataFrame = dataFrame.drop($"sip")
resultframe.printSchema()
resultframe.show(10,truncate = false)
// printToHive(resultframe)
// TODO: step1. 从Hive表中加载广告ETL数据,日期过滤,从本地文件系统读取,封装数据至RDD中
val empDF: DataFrame = sparkSession.read
.table("itcast_ads.pmt_ads_info")
// TODO: step3. 基于SQL方式分析
/*
a. 注册为临时视图
b. 编写SQL,执行分析
*/
// a. 将DataFrame注册为临时视图
empDF.createOrReplaceTempView("TMP")
// b. 编写SQL,执行分析
val count_Region: DataFrame = sparkSession.sql(
"""
SELECT
CAST(DATE_SUB(NOW(),1) AS STRING)AS report_date,
province,
city,
COUNT(1) AS count
FROM itcast_ads.pmt_ads_info
WHERE date_str =2021-05-13
GROUP BY province,city
ORDER BY count
DESC LIMIT 10
""".stripMargin)
// TODO: step 4. 将分析结果数据保存到外部存储系统中
count_Region.printSchema()
count_Region.show(10,truncate = false)
// SaveToMysql(count_Region)
sparkSession.stop()
}
}
3.第三章 业务报表分析
一般的系统需要使用报表来展示公司的运营情况、 数据情况等,本章节对数据进行一些常见报表的开发,广告数据业务报表数据流向图如下所示:
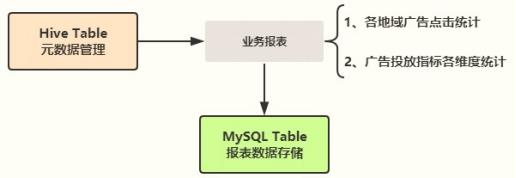
具体报表的需求如下:

相关报表开发说明如下:
⚫ 第一、数据源:每天的日志数据,即ETL的结果数据,存储在Hive分区表,依据分区查询数据;
⚫ 第二、报表分为两大类:基础报表统计(上图中①)和广告投放业务报表统计(上图中②);
⚫ 第三、不同类型的报表的结果存储在MySQL不同表中,上述7个报表需求存储7个表中:
各地域分布统计:region_stat_analysis 广告区域统计:ads_region_analysis 广告APP统计:ads_app_analysis
广告设备统计:ads_device_analysis
广告网络类型统计:ads_network_analysis 广告运营商统计:ads_isp_analysis
广告渠道统计:ads_channel_analysis
⚫ 第四、由于每天统计为定时统计,各个报表中加上统计日期字段:report_date;
3.1报表运行主类
所有业务报表统计放在一个应用程序中,在实际运行时,要么都运行,要么都不运行,创建报表运行主类:PmtReportRunner.scala,将不同业务报表需求封装到不同类中进行单独处理,其中编程逻辑思路如下:
// 1. 创建SparkSession实例对象
// 2. 从Hive表中加载广告ETL数据,日期过滤
// 3. 依据不同业务需求开发报表
// 4. 应用结束,关闭资源
3.2各地域数量分布
按照地域(省份province和城市city)统计广告数据分布情况,看到不同地区有多少数据,从而能够地区优化公司运营策略,最终结果如下图所示:
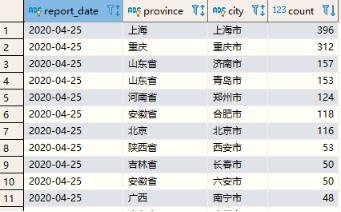
在MySQL数据库中创建数据库【itcast_ads_report】和表【region_stat_analysis】。
3.3广告投放的地域分布
按照产品需求,需要完成如下统计的报表:
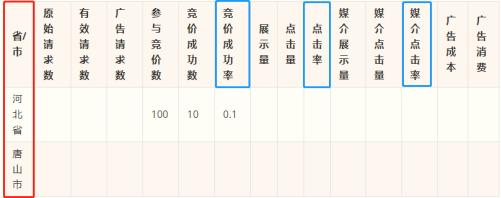
从上面的统计报表可以看出,其中包含三个“率”计算,说明如下:

3.3.1报表字段信息
3.3.2数据库创建表
3.3.3广告数据表相关字段
3.3.4指标逻辑
实现代码:
package src.main.scala.cn.itcast.spark.etl.report
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.storage.StorageLevel
/**
* @author ChinaManor
* #Description AdsRegionAnalysisReport
* #Date: 14/5/2021 10:31
*/
object AdsRegionAnalysisReport {
def main(args: Array[String]): Unit = {
//SQL
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 显示指定集成Hive
.enableHiveSupport()
// 设置Hive MetaStore服务地址
.config("hive.metastore.uris", "thrift://node1.itcast.cn:9083")
.getOrCreate()
// 导入隐式转换
// TODO: step1. 从Hive表中加载广告ETL数据,日期过滤,从本地文件系统读取,封装数据至RDD中
val empDF = spark.read
.table("itcast_ads.pmt_ads_info")
empDF.printSchema()
empDF.show(10, truncate = false)
// TODO: step3. 基于SQL方式分析
/*
a. 注册为临时视图
b. 编写SQL,执行分析
*/
// a. 将DataFrame注册为临时视图
// b. 编写SQL,执行分析
empDF.createOrReplaceTempView("TMP")
val count_Region: DataFrame = empDF.sparkSession.sql(
"""
SELECT
date_str,province,city,
SUM(
CASE
WHEN requestmode=1 AND processnode>=1 THEN 1 ELSE 0
END
) as orginal_req_cnt,
SUM(
CASE
WHEN requestmode=1 AND processnode>=2 THEN 1 ELSE 0
END
) as valid_req_cnt,
SUM(
CASE
WHEN requestmode=1 AND processnode=3 THEN 1 ELSE 0
END
) as ad_req_cnt,
SUM(
CASE
WHEN adplatformproviderid>=100000 AND iseffective=1 AND isbilling=1 AND isbid=1 AND adorderid!=0 THEN 1 ELSE 0
END
) as join_rtx_cnt
FROM TMP
GROUP BY date_str,province,city
""".stripMargin)
count_Region.printSchema()
count_Region.show(10, truncate = false)
// TODO: step 4. 将分析结果数据保存到外部存储系统中
// SaveToMysql(count_Region)
def SaveToMysql(count_Region: DataFrame) = {
count_Region.persist(StorageLevel.MEMORY_AND_DISK)
// 保存结果数据至MySQL表中
val props = new Properties()
props.put("user", "root")
props.put("password", "123456")
props.put("driver", "com.mysql.cj.jdbc.Driver")
count_Region
.coalesce(1) // 对结果数据考虑降低分区数
.write
.mode(SaveMode.Append)
.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&userUnicode=true",
"itcast_ads_report.ads_region_analysis",
props)
}
}
}
4.第四章 应用执行调度
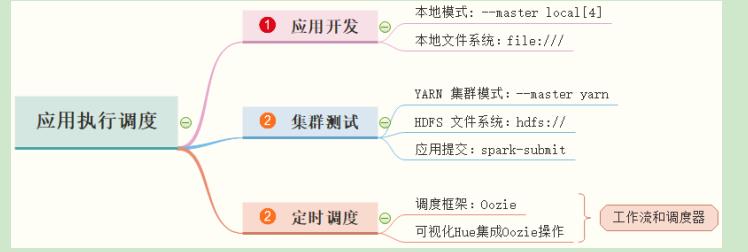
前面已经完成【广告数据ETL】和【业务报表分析】,在IDEA中使用本地模式LocalMode开发, 从本地文件系统LocalFS加载数据,接下来打包发到测试集群环境测试。
4.1集群提交运行
使用spark-submit提交应用执行,如下案例所示:
$SPARK_HOME/bin/spark-submit
–class
–master
–deploy-mode
–conf =
… # other options
\\ [application-arguments]
具体说明,查看官方文档:http://spark.apache.org/docs/2.4.5/submitting-applications.html#
对上述开发的两个Spark 应用分别提交运行:
⚫第一个:广告数据ETL处理应用(ads_etl)
◼应用运行主类:cn.itcast.spark.etl.PmtEtlRunner
⚫第二个:广告数据报表Report统计应用(ads_report)
◼应用运行主类:cn.itcast.spark.report.PmtReportRunner
4.1.1本地模式提交
先使用spark-submit提交【ETL应用】和【Report应用】,以本地模式LocalMode运行,查看
Hive Table和MySQL Table数据是否OK。
4.1.2集群模式提交
当本地模式LocalMode应用提交运行没有问题时,启动YARN集群,使用spark-submit提交
【ETL应用】和【Report应用】,以YARN Client和Cluaster不同部署模式运行,查看Hive Table和MySQL Table数据是否OK。
项目结构

pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.czxy</groupId>
<artifactId>SparkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0</hadoop.version>
<hbase.version>1.2.0</hbase.version>
<kafka.version>2.0.0</kafka.version>
<mysql.version>8.0.19</mysql.version>
<jedis.version>3.2.0</jedis.version>
</properties>
<dependencies>
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!--spark-streaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
以上是关于手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark的主要内容,如果未能解决你的问题,请参考以下文章
Redis 技术探索「数据迁移实战」手把手教你如何实现在线 + 离线模式进行迁移 Redis 数据实战指南(数据检查对比)
Redis技术探索「数据迁移实战」手把手教你如何实现在线 + 离线模式进行迁移Redis数据实战指南(离线同步数据)
Redis 技术探索「数据迁移实战」手把手教你如何实现在线+离线模式进行迁移Redis数据实战指南(离线同步数据)
Redis 技术探索「数据迁移实战」手把手教你如何实现在线 + 离线模式进行迁移 Redis 数据实战指南(数据检查对比)