项目实战——参数配置化Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本)
Posted ╭⌒若隐_RowYet——大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目实战——参数配置化Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本)相关的知识,希望对你有一定的参考价值。
目 录
-
项目实战——将Hive表的数据直接导入ElasticSearch
此篇文章不用写代码,简单粗暴,但是相对没有那么灵活;底层采用MapReduce计算框架,导入速度相对较慢! -
项目实战——Spark将Hive表的数据写入ElasticSearch(Java版本)
此篇文章需要Java代码,实现功能和篇幅类似,直接Java一站式解决Hive内用Spark取数,新建ES索引,灌入数据,并且采用ES别名机制,实现ES数据更新的无缝更新,底层采用Spark计算框架,导入速度相对文章1的做法较快的多!; -
项目实战——钉钉报警验证ElasticSearch和Hive数据仓库内的数据质量(Java版本)
此篇文章主要选取关键性指标,数据校验数据源Hive和目标ES内的数据是否一致; -
项目实战——Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本)
此篇文章主要讲述如何通过spark将hive数据写入带账号密码权限认证的ElasticSearch 内; -
项目实战(生产环境部署上线)——参数配置化Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本))
此篇文章主要讲述如何通过spark将hive数据写入带账号密码权限认证的ElasticSearch 内,同时而是,spark,es建索引参数配置化,每次新增一张表同步到es只需要新增一个xml配置文件即可,也是博主生产环境运用的java代码,弥补下很多老铁吐槽方法4的不足。
综述:
1.如果感觉编码能力有限,又想用到Hive数据导入ElasticSearch,可以考虑文章1;
2.如果有编码能力,个人建议采用文章2和文章3的组合情况(博主推荐),作为离线或者近线数据从数据仓库Hive导入ElasticSearch的架构方案,并且此次分享的Java代码为博主最早实现的版本1,主要在于易懂,实现功能,学者们可以二次加工,请不要抱怨代码写的烂;
3.如果是elasticsearch是自带账号密码权限认证的,如云产品或者自己设置了账号密码认证的,那么办法,只能用文章4了;
4.如果部署上线,还是要看文章5。
-
本人Hive版本:2.3.5
-
本人ES版本:7.7.1
-
本人Spark版本:2.3.3
背 景
将要创建的ES索引信息和ES的连接信息参数化,这样每次新增一张表时,只需要新增一个xml配置文件即可,es服务器迁移,只需要变更一个ES文件即可,因为是大数据环境嘛,博主选择把这两类配置文件放在hdfs上,当然如果没有hdfs,也可以把配置文件放到ftp,或者某共享文件夹下,只是不同文件系统在读取配置文件的IO流略有不同,读者根据自己的文件系统来选择相应的文件IO流即可。
如图1,主要数据链路架构就是通过调用编译好的jar包读取hdfs上的配置文件信息,再通过spark将hive的表同步到Elasticsearch内。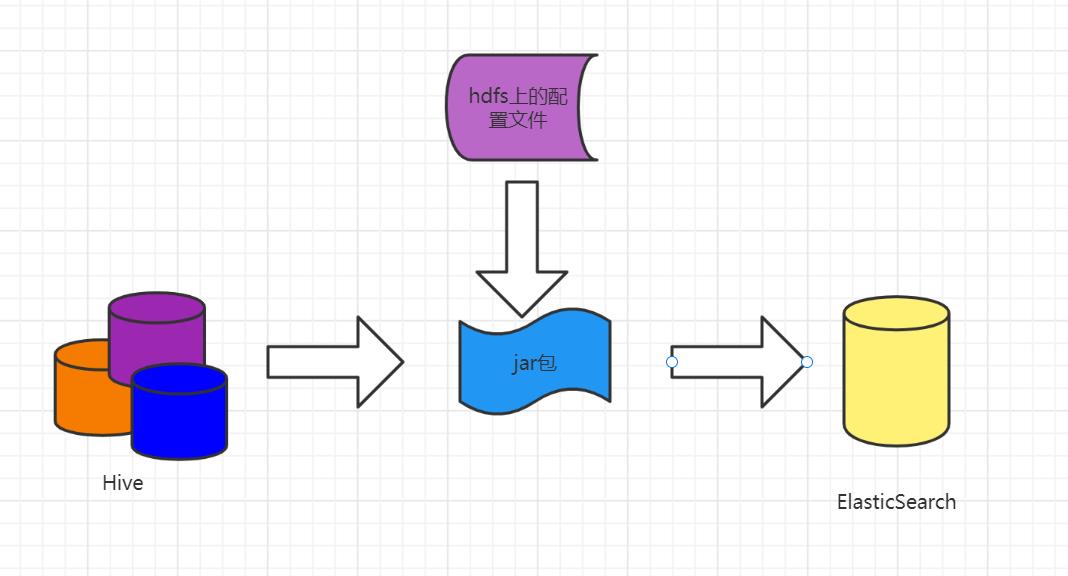
图1 参数化数据链路图 ElasticSearch是可以配置用户名,密码认证的,特别是云产品,公司如果买的ElasticSearch的云服务,那必然是带用户名密码认证的,即当你访问你的ES时,默认一般是9200端口时会弹出如图2的提示,需要你填写用户名密码;
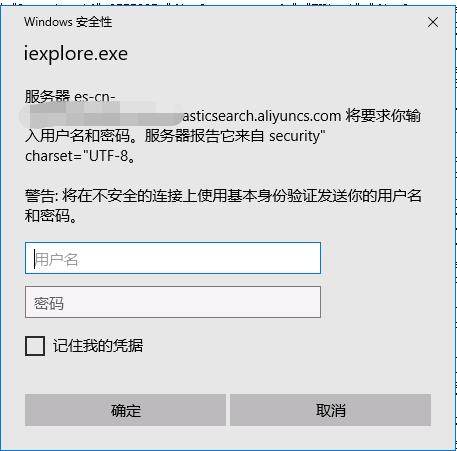
解决方案
ping通ES的机器
在你要访问的源机器ping通需要目标端的es机器ip,ping不通,找网管;
telnet通ES的机器的端口
在你要访问的源机器telnet通需要目标端的es机器ip和端口,telnet不通,找网管;
拿到用户名和密码
既然是用户名和密码认证,当然需要向管理员拿到账号和密码,拿到用户名和密码后,先去测试下该用户名能否登陆es,并且能否读写权限,读写,创建index(非必要),可以在kibana上验证,认证访问,最好在你跑程序的地方,跑一下RESTFul风格的代码,如下(linux环境shell命令行内直接跑);
# 用户名密码有转移字符,记得前面加\\转移,如abc!123,写成abc\\!123
# 用户名密码有转移字符,记得前面加\\转移,如abc!123,写成abc\\!123
# 用户名密码有转移字符,记得前面加\\转移,如abc!123,写成abc\\!123
curl -k -u user:password -XGET http://es-ip:9200/your_index/_search
windows cmd下:
# 注意用户名密码后面是@符号,用户名密码有转译字符可不转译,别乱搞
# 注意用户名密码后面是@符号,用户名密码有转译字符可不转译,别乱搞
# 注意用户名密码后面是@符号,用户名密码有转译字符可不转译,别乱搞
curl "http://user:password@es-ip:9200/your_index/_search"
如果能获取到数据,说明网络,账号一切都Ok,加上kibana能读写index,说明权限Ok,否则,哪一环出了问题去找到相关的人员解决,准备工作都Ok了,再去写代码,不然代码一直报错,让你怀疑人生;
项目树
总体项目树图谱如图1所示,编程软件:IntelliJ IDEA 2019.3 x64,采用Maven架构;
/LXWalaz1s1s/13037253)
feign:连接ES和Spark客户端相关的Java类;utils:操作ES和Spark相关的Java类;resources:日志log的配置类;pom.xml:Maven配置文件;

Maven配置文件pox.xml
该项目使用到的Maven依赖包存在pom.xml上,具体如下所示;.
<?xml version="1.0" encoding="UTF-8"?>
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkOnHiveToEs_buildinginfo_v1</artifactId>
<version>1.0-SNAPSHOT</version>
<name>SparkOnHiveToEs_buildinginfo_v1</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch -->
<!--ES本身的依赖-->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client -->
<!--ES高级API,用来连接ES的Client等操作-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<!--junit,Test测试使用-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<!--lombok ,用来自动生成对象类的构造函数,get,set属性等-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<!--jackson,用来封装json-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch-spark-20 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_2.11</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.3</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/dom4j/dom4j -->
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven 打jar包需要插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.bjsxt.scalaspark.core.examples.ExecuteLinuxShell</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
日志配置文件
最终这个Job是需要给spark-submit调用的,所以希望有一些有用关键的信息可以通过日志输出,而不是采用System,out.println的形式输出到console端,所以要用到log.info("关键内容信息")方法,所以设置两个log的配置信息,如,只输出bug,不输出warn等,可以根据自己需求来配置,具体两个log配置文件内容如下;
log4j.properties配置如下;
log4j.rootLogger=INFO, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=firestorm.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=INFO
log4j2.xml配置如下;
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="warn">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%m%n" />
</Console>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>
读取hdfs配置文件
注意配置是存在hdfs上的,当然读者也可以根据自己需求存在不同的文件系统内,因为存在hdfs文件系统,所以要遵循hdfs文件系统的IO流,具体参看一下PropertiesUtils.java
package cn.focusmedia.esapp.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.*;
import java.util.Iterator;
import java.util.Properties;
public class PropertiesUtils
public static String getProperties(String filePath,String key)
// //本地文件系统
// Properties prop =new Properties();
// try
// InputStream inputStream=new BufferedInputStream(new FileInputStream(new File(filePath)));
// prop.load(inputStream);
//
// catch (Exception e)
// e.printStackTrace();
//
// return prop.getProperty(key);
//hdfs文件系统
Configuration conf = new Configuration();
FileSystem fs=null;
Properties prop =new Properties();
try
fs= FileSystem.get(conf);
catch (IOException e)
e.printStackTrace();
Path path = new Path(filePath);
FSDataInputStream inputStream=null;
try
inputStream = fs.open(path);
prop.load(inputStream);
catch (IOException e)
e.printStackTrace以上是关于项目实战——参数配置化Spark将Hive表的数据写入需要用户名密码认证的ElasticSearch(Java版本)的主要内容,如果未能解决你的问题,请参考以下文章