主题模型——隐含狄利克雷分布总结
Posted 混沌战神阿瑞斯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主题模型——隐含狄利克雷分布总结相关的知识,希望对你有一定的参考价值。
摘要:
1.算法概述
2.算法推导
3.算法特性及优缺点
4.注意事项
5.实现和具体例子
6.适用场合
7.与NB,pLSA比较
内容:
1.算法概述:
先贴一段维基百科中关于主题模型的描述,便于大家理解我们接下来要做什么:
主题模型(Topic Model)在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。
直观来讲,如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。比方说,如果一篇文章是在讲狗的,那“狗”和“骨头”等词出现的频率会高些。如果一篇文章是在讲猫的,那“猫”和“鱼”等词出现的频率会高些。而有些词例如“这个”、“和”大概在两篇文章中出现的频率会大致相等。但真实的情况是,一篇文章通常包含多种主题,而且每个主题所占比例各不相同。因此,如果一篇文章10%和猫有关,90%和狗有关,那么和狗相关的关键字出现的次数大概会是和猫相关的关键字出现次数的9倍。
一个主题模型试图用数学框架来体现文档的这种特点。
主题模型自动分析每个文档,统计文档内的词语,根据统计的信息来断定当前文档含有哪些主题,以及每个主题所占的比例各为多少。
接下来细化LDA的主题模型表示:
共有m篇文章,一种设计了k(超参数)个主题;
每篇文章都有自己的主题分布(先验的认为是多项分布),该主题分布的参数服从参数为阿勒法的Dirchlet分布;
每个主题都有自己的词分布(先验的认为是多项分布),该词分布的参数服从参数为贝塔的Dirchlet分布。
其对应的概率(图)模型如下:
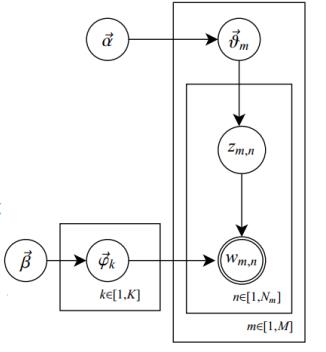

单圆圈表示隐变量;双圆圈表示观察到的变量;把节点用方框(plate)圈起来,表示其中的节点有多种选择。所以这种表示方法也叫做plate notation,参考PRML 8.0 Graphical Models。
2.算法推导
LDA的算法推导主要设计共轭先验分布,Dirchlet分布,Gibbs采样学习参数;其中前两个推导可以查阅常见概率分布图表总结
下面主要推导Gibbs采样进行参数学习:
1.在给定主题的情况下,采样词的概率: 2.主题出现的概率:


3.Gibbs更新规则: 一个理解主题-词分布的可视化图:

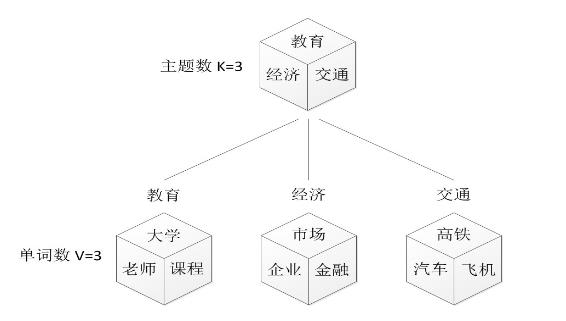

得到主题分布和词分布:
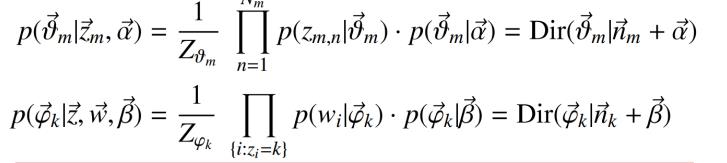
注:为了工程方便,上面的介绍都没给出可用性证明;更加具体的关于gibbs采样是有效的证明可以看这篇文章:LDA-math-MCMC 和 Gibbs Sampling
在这里简单提一下设计到的点:马氏链定理可以证明一系列的状态转移是可以达到稳态的
3.算法特性及优缺点
1.无监督学习算法,在训练时不需要手工标注的训练集,只需先验给定主题的数量k
2.对于每一个主题均可找出一些词语来描述它
4.注意事项
1.关于K值的确定:
以下摘自知乎问答:LDA自己评价标准叫Perplexity。Perplexity可以粗略的理解为“对于一篇文章,我们的LDA模型有多不确定它是属于某个topic的”。topic越多,Perplexity越小,但是越容易overfitting。
2.关于Dirichlet分布的参数阿勒法,贝塔的确定:

5.实现和具体例子
主题提取:python实现网易主题提取
文本分类:Spark MLlib实现的中文文本分类–Naive Bayes
情感分析:使用Spark MLlib进行情感分析
6.适用场合
信息提取与搜索——语义分析
文本分类/聚类,文章摘要,社区挖掘
基于内容的图像聚类,目标识别
生物信息数据的应用
7.与NB,pLSA比较
1.NB文本分类与LDA文本分类的比较:
如果使用词向量作为文档的特征,一词多义和多词一义会造成文档间相似度的不准确性。LDA通过增加“主题”的方式,将一个词映射到多个主题,解决一词多义问题;将多个词映射到一个主题解决多词一义问题。
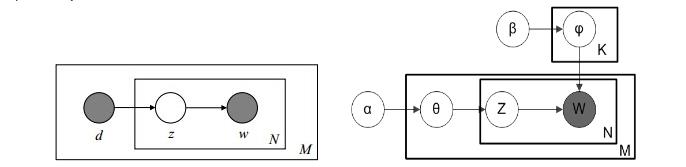
2.pLSA主题模型与LDA主题模型的比较:
pLSA:样本随机,参数虽未知但固定,属于频率派思想。使用EM算法进行参数学习;适合短文本。
LDA:样本固定,参数未知但不固定,是个随机变量,服从一定的分布,属于贝叶斯派思想;使用Gibbs采样方法进行参数学习,适合长文本。
pLSA LDA
以上是关于主题模型——隐含狄利克雷分布总结的主要内容,如果未能解决你的问题,请参考以下文章