文本主题模型之LDA LDA基础
Posted hx868
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本主题模型之LDA LDA基础相关的知识,希望对你有一定的参考价值。
在前面我们讲到了基于矩阵分解的LSI和NMF主题模型,这里我们开始讨论被广泛使用的主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,以下简称LDA)。注意机器学习还有一个LDA,即线性判别分析,主要是用于降维和分类的,如果大家需要了解这个LDA的信息,参看之前写的线性判别分析LDA原理总结。文本关注于隐含狄利克雷分布对应的LDA。
1. LDA贝叶斯模型
LDA是基于贝叶斯模型的,涉及到贝叶斯模型离不开“先验分布”,“数据(似然)”和"后验分布"三块。在朴素贝叶斯算法原理小结中我们也已经讲到了这套贝叶斯理论。在贝叶斯学派这里:
先验分布 + 数据(似然)= 后验分布
这点其实很好理解,因为这符合我们人的思维方式,比如你对好人和坏人的认知,先验分布为:100个好人和100个的坏人,即你认为好人坏人各占一半,现在你被2个好人(数据)帮助了和1个坏人骗了,于是你得到了新的后验分布为:102个好人和101个的坏人。现在你的后验分布里面认为好人比坏人多了。这个后验分布接着又变成你的新的先验分布,当你被1个好人(数据)帮助了和3个坏人(数据)骗了后,你又更新了你的后验分布为:103个好人和104个的坏人。依次继续更新下去。
2. 二项分布与Beta分布
对于上一节的贝叶斯模型和认知过程,假如用数学和概率的方式该如何表达呢?
对于我们的数据(似然),这个好办,用一个二项分布就可以搞定,即对于二项分布:
其中p我们可以理解为好人的概率,k为好人的个数,n为好人坏人的总数。
虽然数据(似然)很好理解,但是对于先验分布,我们就要费一番脑筋了,为什么呢?因为我们希望这个先验分布和数据(似然)对应的二项分布集合后,得到的后验分布在后面还可以作为先验分布!就像上面例子里的“102个好人和101个的坏人”,它是前面一次贝叶斯推荐的后验分布,又是后一次贝叶斯推荐的先验分布。也即是说,我们希望先验分布和后验分布的形式应该是一样的,这样的分布我们一般叫共轭分布。在我们的例子里,我们希望找到和二项分布共轭的分布。
和二项分布共轭的分布其实就是Beta分布。Beta分布的表达式为:
其中ΓΓ是Gamma函数,满足Γ(x)=(x?1)!Γ(x)=(x?1)!
仔细观察Beta分布和二项分布,可以发现两者的密度函数很相似,区别仅仅在前面的归一化的阶乘项。那么它如何做到先验分布和后验分布的形式一样呢?后验分布P(p|n,k,α,β)P(p|n,k,α,β)推导如下:
将上面最后的式子归一化以后,得到我们的后验概率为:
可见我们的后验分布的确是Beta分布,而且我们发现:
这个式子完全符合我们在上一节好人坏人例子里的情况,我们的认知会把数据里的好人坏人数分别加到我们的先验分布上,得到后验分布。
我们在来看看Beta分布Beta(p|α,β)Beta(p|α,β)的期望:
由于上式最右边的乘积对应Beta分布Beta(p|α+1,β)Beta(p|α+1,β),因此有:
这样我们的期望可以表达为:
这个结果也很符合我们的思维方式。
3. 多项分布与Dirichlet 分布
现在我们回到上面好人坏人的问题,假如我们发现有第三类人,不好不坏的人,这时候我们如何用贝叶斯来表达这个模型分布呢?之前我们是二维分布,现在是三维分布。由于二维我们使用了Beta分布和二项分布来表达这个模型,则在三维时,以此类推,我们可以用三维的Beta分布来表达先验后验分布,三项的多项分布来表达数据(似然)。
三项的多项分布好表达,我们假设数据中的第一类有m1m1个好人,第二类有m2m2个坏人,第三类为m3=n?m1?m2m3=n?m1?m2个不好不坏的人,对应的概率分别为p1,p2,p3=1?p1?p2p1,p2,p3=1?p1?p2,则对应的多项分布为:
那三维的Beta分布呢?超过二维的Beta分布我们一般称之为狄利克雷(以下称为Dirichlet )分布。也可以说Beta分布是Dirichlet 分布在二维时的特殊形式。从二维的Beta分布表达式,我们很容易写出三维的Dirichlet分布如下:
同样的方法,我们可以写出4维,5维,。。。以及更高维的Dirichlet 分布的概率密度函数。为了简化表达式,我们用向量来表示概率和计数,这样多项分布可以表示为:Dirichlet(p? |α? )Dirichlet(p→|α→),而多项分布可以表示为:multi(m? |n,p? )multi(m→|n,p→)。
一般意义上的K维Dirichlet 分布表达式为:
而多项分布和Dirichlet 分布也满足共轭关系,这样我们可以得到和上一节类似的结论:
对于Dirichlet 分布的期望,也有和Beta分布类似的性质:
4. LDA主题模型
前面做了这么多的铺垫,我们终于可以开始LDA主题模型了。
我们的问题是这样的,我们有MM篇文档,对应第d个文档中有有NdNd个词。即输入为如下图:
我们的目标是找到每一篇文档的主题分布和每一个主题中词的分布。在LDA模型中,我们需要先假定一个主题数目KK,这样所有的分布就都基于KK个主题展开。那么具体LDA模型是怎么样的呢?具体如下图:
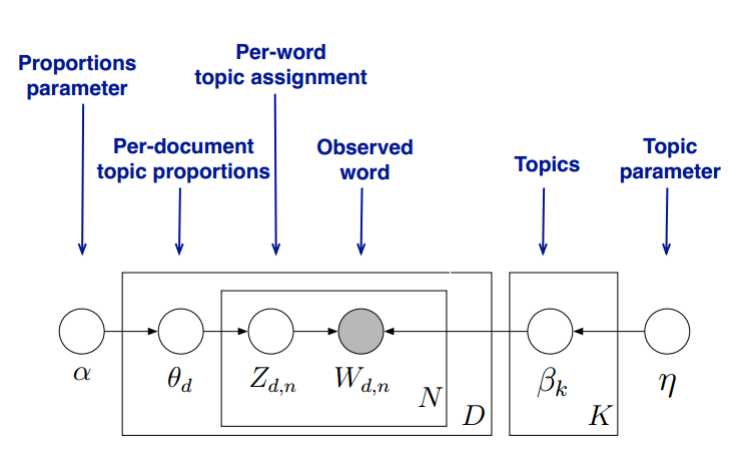
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档dd, 其主题分布θdθd为:
其中,αα为分布的超参数,是一个KK维向量。
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题kk, 其词分布βkβk为:
其中,ηη为分布的超参数,是一个VV维向量。VV代表词汇表里所有词的个数。
对于数据中任一一篇文档dd中的第nn个词,我们可以从主题分布θdθd中得到它的主题编号zdnzdn的分布为:
而对于该主题编号,得到我们看到的词wdnwdn的概率分布为:
理解LDA主题模型的主要任务就是理解上面的这个模型。这个模型里,我们有MM个文档主题的Dirichlet分布,而对应的数据有MM个主题编号的多项分布,这样(α→θd→z? dα→θd→z→d)就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第d个文档中,第k个主题的词的个数为:n(k)dnd(k), 则对应的多项分布的计数可以表示为
利用Dirichlet-multi共轭,得到θdθd的后验分布为:
同样的道理,对于主题与词的分布,我们有KK个主题与词的Dirichlet分布,而对应的数据有KK个主题编号的多项分布,这样(η→βk→w? (k)η→βk→w→(k))就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。
如果在第k个主题中,第v个词的个数为:n(v)knk(v), 则对应的多项分布的计数可以表示为
利用Dirichlet-multi共轭,得到βkβk的后验分布为:
由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。理解了上面这M+KM+K组Dirichlet-multi共轭,就理解了LDA的基本原理了。
现在的问题是,基于这个LDA模型如何求解我们想要的每一篇文档的主题分布和每一个主题中词的分布呢?
一般有两种方法,第一种是基于Gibbs采样算法求解,第二种是基于变分推断EM算法求解。
如果你只是想理解基本的LDA模型,到这里就可以了,如果想理解LDA模型的求解,可以继续关注系列里的另外两篇文章。
转载自 文本主题模型之LDA(一) LDA基础 - 刘建平Pinard - 博客园 https://www.cnblogs.com/pinard/p/6831308.html
以上是关于文本主题模型之LDA LDA基础的主要内容,如果未能解决你的问题,请参考以下文章