Spark:聚类算法之LDA主题模型算法
Posted 猿助猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark:聚类算法之LDA主题模型算法相关的知识,希望对你有一定的参考价值。
Spark实现LDA的GraphX基础
在Spark 1.3中,MLlib现在支持最成功的主题模型之一,隐含狄利克雷分布(LDA)。LDA也是基于GraphX上构建的第一个MLlib算法,GraphX是实现它最自然的方式。
有许多算法可以训练一个LDA模型。我们选择EM算法,因为它简单并且快速收敛。因为用EM训练LDA有一个潜在的图结构,在GraphX之上构建LDA是一个很自然的选择。
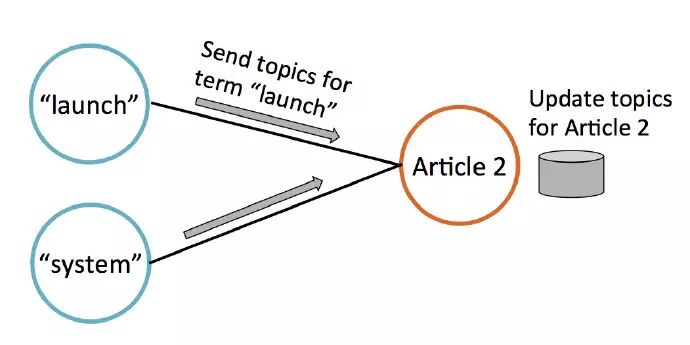
LDA主要有两类数据:词和文档。我们把这些数据存成一个偶图(如下所示),左边是词节点,右边是文档节点。每个词节点存储一些权重值,表示这个词语和哪个主题相关;类似的,每篇文章节点存储当前文章讨论主题的估计。
每当一个词出现在一篇文章中,图中就有一个边连接对应的词节点和文章节点。例如,在上图中,文章1包含词语“hockey” 和“system”
这些边也展示了这个算法的流通性。每轮迭代中,每个节点通过收集邻居数据来更新主题权重数据。下图中,文章2通过从连接的词节点收集数据来更新它的主题估计。
GraphX因此是LDA自然的选择。随着MLlib的成长,我们期望未来可以有更多图结构的学习算法!
可扩展性
LDA的并行化并不直观,已经有许多研究论文提出不同的策略来实现。关键问题是所有的方法都需要很大量的通讯。这在上图中很明显:词和文档需要在每轮迭代中用新数据更新相邻节点,而相邻节点太多了。
我们选择了EM算法的部分原因就是它通过很少轮的迭代就能收敛。更少的迭代,更少的通讯。
Note: Spark的贡献者正在开发更多LDA算法:在线变分贝叶斯(一个快速近似算法)和吉布斯采样(一个更慢但是有时更准确的算法)。
[用 LDA 做主题模型:当 MLlib 邂逅 GraphX]
[Spark官网上关于LDA的解释:Latent Dirichlet allocation (LDA)]
PySpark.ml库中Clustering LDA简介
LDA通过 setOptimizer 函数支持不同的推断算法。EMLDAOptimizer 对于似然函数用 expectation-maximization 算法学习聚类,然后获得一个合理的结果。OnlineLDAOptimizer使用迭代的mini-batch抽样来进行 online variational inference,它通常对内存更友好。
LDA接收文档集合表示的词频向量,和下列参数(使用builder模式进行设置):
k: 主题数(也就是聚类中心数)
optimizer: 优化计算方法,目前支持"em", "online"。学习LDA模型使用的优化器,EMLDAOptimizer 或者 OnlineLDAOptimizer。
docConcentration: 文档-主题分布的先验Dirichlet参数。值越大,推断的分布越平滑。文章分布的超参数(Dirichlet分布的参数)。只支持对称的先验,因此在提供的k维向量中所有值都相等。所有值也必须大于1.0。
topicConcentration: 主题-词语分布的先验Dirichlet参数。值越大,推断的分布越平滑。主题分布的超参数(Dirichlet分布的参数),必需>1.0。
maxIterations: 迭代次数的限制
checkpointInterval: 迭代计算时检查点的间隔。如果你使用checkpointing(在Spark配置中设置),该参数设置checkpoints创建的次数,如果maxIterations过大,使用checkpointing可以帮助减少磁盘上shuffle文件的大小,然后帮助失败恢复。
setSeed:随机种子
参数设置
Expectation Maximization
docConcentration: 提供Vector(-1)会导致默认值 (uniform k dimensional vector with value (50/k))+1。
topicConcentration: 提供-1会导致默认值0.1 加1。
Online Variational Bayes
docConcentration:Providing Vector(-1) results indefault behavior (uniform k dimensional vector with value
topicConcentration: Providing -1 results in defaulting to a value of
[Latent Dirichlet allocation (LDA)]
[Asuncion, Welling, Smyth, and Teh. “On Smoothing and Inference for Topic Models.” UAI, 2009.]
所有spark.mllib的 LDA 模型都支持:
describeTopics: 返回主题,它是最重要的term组成的数组和term对应的权重组成的数组。
topicsMatrix: 返回一个 vocabSize*k 维的矩阵,每一个列是一个topic。
注意:LDA仍然是一个正在开发的实验特性。某些特性只在两种优化器/由优化器生成的模型中的一个提供。目前,分布式模型可以转化为本地模型,反过来不可以。
LDA求解的优化器/模型
Expectation Maximization
Implemented in EMLDAOptimizer and DistributedLDAModel.
提供给LDA的参数有:
docConcentration: 只支持对称的先验,因此在提供的k维向量中所有值都相等。所有值也必须大于1.0。提供Vector(-1)会导致默认值 (uniform k dimensional vector with value (50/k))+1。
topicConcentration: 只支持对称的先验,所有值也必须大于1.0。提供-1会导致默认值0.1 加1。
maxIterations: EM迭代的最大次数。
注意:做足够多次迭代是重要的。在早期的迭代中,EM经常会有一些无用的topics,但是这些topics经过更多次的迭代会有改善。依赖你的数据集,如果使用至少20个topic,可能需要50-100次的迭代。
EMLDAOptimizer 会产生 DistributedLDAModel, 它不只存储推断的主题,还有所有的训练语料,以及训练语料库中每个文档的主题分布:
topTopicsPerDocument: 训练语料库中每个文档的前若干个主题和对应的权重
topDocumentsPerTopic: 每个主题下的前若干个文档和文档中对应的主题的权重
logPrior: 基于超参doc Concentration 和 topic Concentration,估计的主题和文档-主题分布的对数概率。
logLikelihood: 基于推断的主题和文档-主题分布,训练语料的对数似然。
Online Variational Bayes
Implemented in OnlineLDAOptimizer and LocalLDAModel.
提供给LDA的参数有:
docConcentration: 通过传递每个维度值都等于Dirichlet参数的向量使用不对称的先验,值应该大于等于0 。提供 Vector(-1) 会使用默认值(uniform k dimensional vector with value
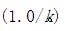 )
)topicConcentration: 只支持对称的先验,值必须大于等于0。提供值-1会使用默认值
maxIterations: 提交的minibatches的最大次数。
miniBatchFraction: 每次迭代使用的语料库抽样比例。
optimizeDocConcentration: 如果设置为true,每次 minibatch 之后计算参数 docConcentration (aka alpha) 的最大似然估计,然后在返回的 LocalLDAModel 使用优化了的docConcentration。
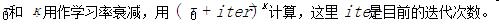
logLikelihood(documents): 给定推断的主题,计算提供的文档的下界。
logPerplexity(documents): 给定推断的主题,计算提供的文档的复杂度的上界。
此外,OnlineLDAOptimizer 接收下列参数:
OnlineLDAOptimizer 生成 LocalLDAModel,它只存储了推断的主题。LocalLDAModel支持:
[PySpark.ml库中的Clustering]
Spark实现LDA实例
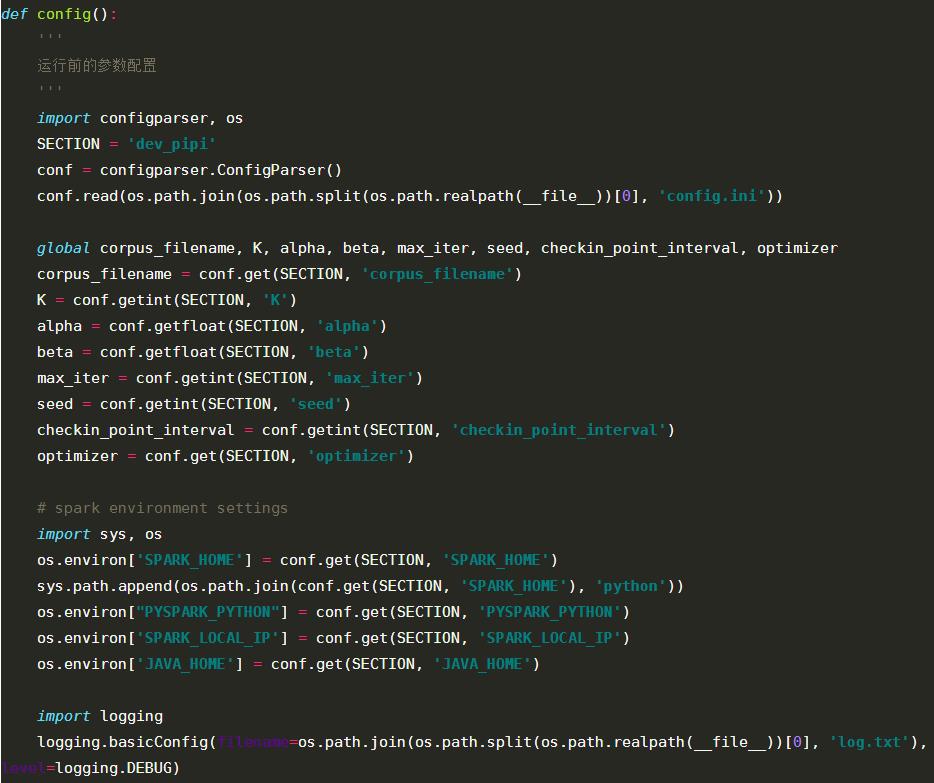
1)加载数据
返回的数据格式为:documents: RDD[(Long, Vector)],其中:Long为文章ID,Vector为文章分词后的词向量;用户可以读取指定目录下的数据,通过分词以及数据格式的转换,转换成RDD[(Long, Vector)]即可。
2)建立模型
模型参数设置说明见上面的简介
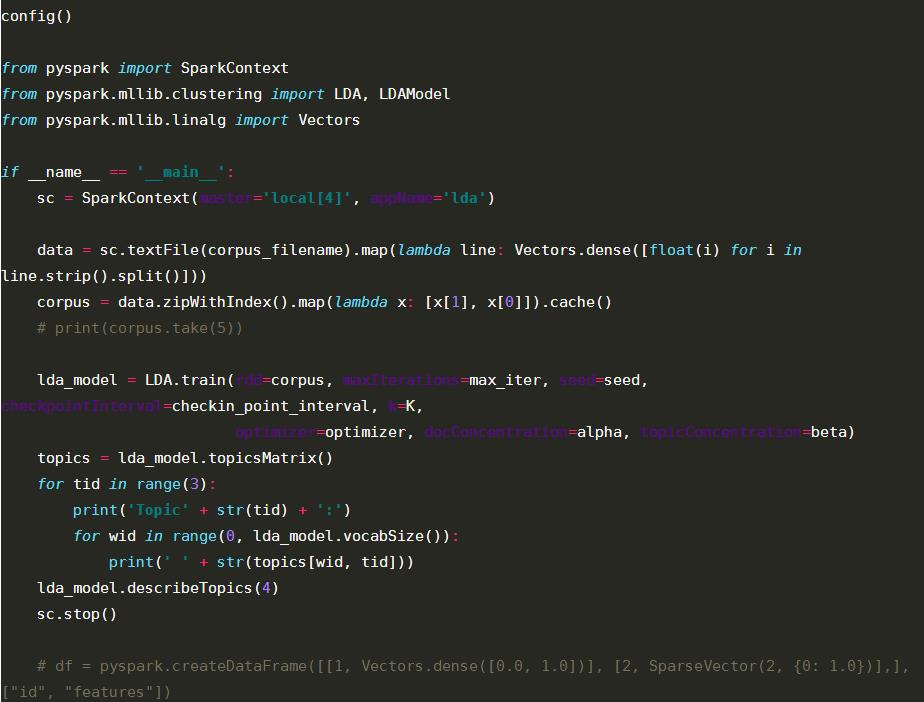
3)结果输出
topicsMatrix以及topics(word,topic))输出。
注意事项
从Pyspark LDA model中获取document-topic matrix
mllib上的lda不是分布式的,目前好像只存储topic的信息,而不存储doc的信息,所以是没法获取doc-topic矩阵的。
要获取的话,只能使用ml中的lda,
或者使用Scala版本的lda:
val ldaModel = lda.run(documents)
val distLDAModel = ldaModel.asInstanceOf[DistributedLDAModel]
distLDAModel.topicDistributions
[Extract document-topic matrix from Pyspark LDA Model]
使用pyspark实现LDA
数据及结果:
1 2 6 0 2 3 1 1 0 0 3
1 3 0 1 3 0 0 2 0 0 1
1 4 1 0 0 4 9 0 1 2 0
2 1 0 3 0 0 5 0 2 3 9
3 1 1 9 3 0 2 0 0 1 3
4 2 0 3 4 5 1 1 1 4 0
2 1 0 3 0 0 5 0 2 2 9
1 1 1 9 2 1 2 0 0 1 3
4 4 0 3 4 2 1 3 0 0 0
2 8 2 0 3 0 2 0 2 7 2
1 1 1 9 0 2 2 0 0 3 3
4 1 0 0 4 5 1 3 0 1 0
觉得本文有帮助?请分享给更多人
关注「猿助猿」成就顶级开发
以上是关于Spark:聚类算法之LDA主题模型算法的主要内容,如果未能解决你的问题,请参考以下文章