蛋白质对中可能相互作用域的数目计算
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了蛋白质对中可能相互作用域的数目计算相关的知识,希望对你有一定的参考价值。
预备知识
关于蛋白质对中可能相互作用域的数目的计算这篇论文
Ensemble learning prediction of protein–protein interactions using proteins functional annotations只提到下面这句话

46参考的是下面这篇文章
DOMINE a comprehensive collection of known and predicted domain-domain interactions
这是一个在线的web数据库,主要是已知的和预测的蛋白质结构域的相互作用数据。
DOMINE 总共包含26219对域间的相互作用(包含5410个域),6634对是从PDB推断的,21620对是通过最新的计算方法预测得来的。
在这21620对域之中,2989对是高信度的预测,2537对是中信度的预测,剩下的16094是低信度的预测。
蛋白质域相互作用数据的准备
它这网站也提供数据下载了。目前最新的是2010年版本的。(感觉似乎不会更新了。 )
)
下载下来后我们得到domine-tables-2.0.zip这个文件,解压后我们可以得到6个文件
里面竟然没有readme
PGMAP.txt:存放的是Pfam ID和GO ID的映射关系。
PFAM.txt:存放的是Pfam数据的基本信息,也就是域的一些描述。
INTERACTION.txt:存放的是相互作用域的信息。
GO.txt:存放的GO的基本信息。
create.sql:存放的是sql语句,具体就是上面4个表的结构
command.sh:linux下的一个脚本。
1.首先我们先把数据导入到mysql
他提供的create.sql文件代码有问题。具体代码如下
这里我使用的mysql可视化界面是Navicat
CREATE TABLE PFAM(DomainAccchar(7) PRIMARY KEY,DomainId varchar(256),DomainDesc varchar(256),InterproIdchar(10));CREATE TABLE GO(GoTermchar(10) PRIMARY KEY,Ontology varchar(256),GoDesc varchar(256));CREATE TABLE PGMAP(DomainAccchar(7),GoTermchar(10),PRIMARY KEY (DomainAcc,GoTerm),);CREATE TABLE INTERACTION(Domain1char(7),Domain2char(7),iPfam boolean,3didboolean,ME boolean,RCDP boolean,Pvalueboolean,Fusionboolean,DPEA boolean,PE boolean,GPE boolean,DIPD boolean,RDFF boolean,KGIDDI boolean,INSITE boolean,DomainGAboolean,PP boolean,PredictionConfidencechar(2),SameGOboolean,PRIMARY KEY (Domain1,Domain2),);
我们用上面语句先把数据的表创建好。
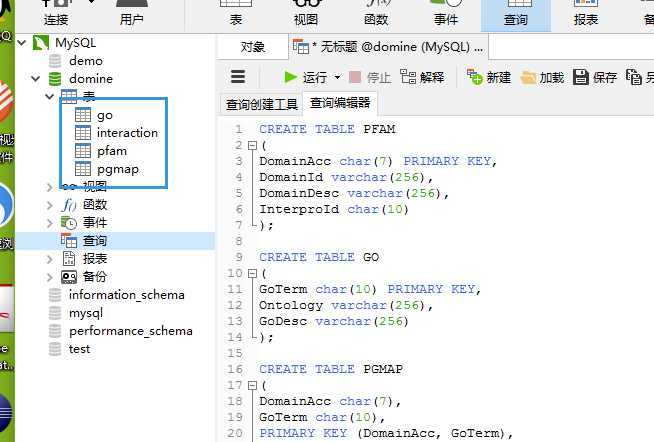
然后我们把PGMAP.txt、PFAM.txt、INTERACTION.txt、GO.txt四个文件分别导入到对应的表中。
2.获得Gene ontology IDs和论文的uniport id 数据
然后我们从uniport上下载所有酵母蛋白的Gene ontology IDs

yeast.csv
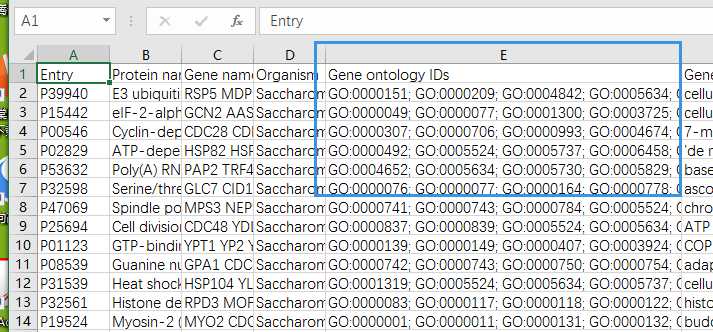
Ensemble learning prediction of protein–protein interactions using proteins functional annotations
获取论文的uniprot codes列(idA,idB)
yeast_gold_protein_pair.csv
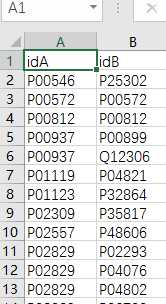
到这里我们的数据已经准备完成了。下面开始写代码!
代码的设计
关于蛋白质对中可能相互作用域的数目的计算,一开始是无从下手的。
但是domine这个网站提供了Pfam id 和GO id的映射。这样我们就可以间接获得蛋白质域间的相互作用
1.首先我们可以从uniport上获得蛋白质的GO id,一个蛋白对应对多GO id
2.根据Pfam id 和GO id的映射关系,我们可以得到一个GO id对应多个Pfam id,也就是说,一个基因本体对应多个域
总的来说就是,一个蛋白质有多个GO,一个GO又有多个域。这样我们就可以间接获得一个蛋白有多少个域。
最后再通过interaction表统计两个蛋白中有多少个域是相互作用的。
代码如下:
# -*- coding: utf-8 -*-"""Created on Fri Nov 04 15:40:03 2016@author: sun"""importMySQLdbimport pandas as pdimport reyeast_gold_protein_pair=pd.read_csv(‘yeast_gold_protein_pair.csv‘,usecols=[‘idA‘,‘idB‘])yeast=pd.read_csv(‘yeast.csv‘,usecols=[‘Entry‘,‘Gene ontology IDs‘],index_col=0)idA=yeast.loc[yeast_gold_protein_pair.idA,:]idB=yeast.loc[yeast_gold_protein_pair.idB,:]idA.index=range(len(idA))idB.index=range(len(idB))db =MySQLdb.connect("127.0.0.1","root","123","domine")cursor = db.cursor()results=[]for i in range(len(idA)):go_a=tuple(re.findall(r"GO:\\d{7}",str(idA.loc[i])))go_a=‘\\‘,\\‘‘.join(go_a)go_b=tuple(re.findall(r"GO:\\d{7}",str(idB.loc[i])))go_b=‘\\‘,\\‘‘.join(go_b)sql_a ="select * from pgmap where goterm in (‘%s‘)"% go_asql_b ="select * from pgmap where goterm in (‘%s‘)"% go_b# 执行SQL语句a=cursor.execute(sql_a)results_a = cursor.fetchall()b=cursor.execute(sql_b)results_b = cursor.fetchall()if(len(results_a)!=0and len(results_b)!=0):results_a=tuple(re.findall(r"PF\\d{5}",str(results_a)))results_a=‘\\‘,\\‘‘.join(results_a)results_b=tuple(re.findall(r"PF\\d{5}",str(results_b)))results_b=‘\\‘,\\‘‘.join(results_b)sql="select * from interaction where domain1 in (‘%s‘) and domain2 in (‘%s‘)"%(results_a,results_b)result=cursor.execute(sql)results.append(result)else:results.append(0)yeast_gold_protein_pair[‘domain‘]=resultsyeast_gold_protein_pair.to_csv(‘domain.csv‘,index=False)# 关闭数据库连接db.close()
最后结果
domain.csv
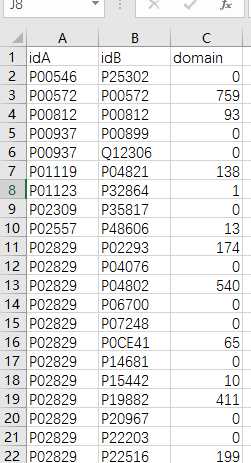
但是和原论文提供的数据相差太大了。
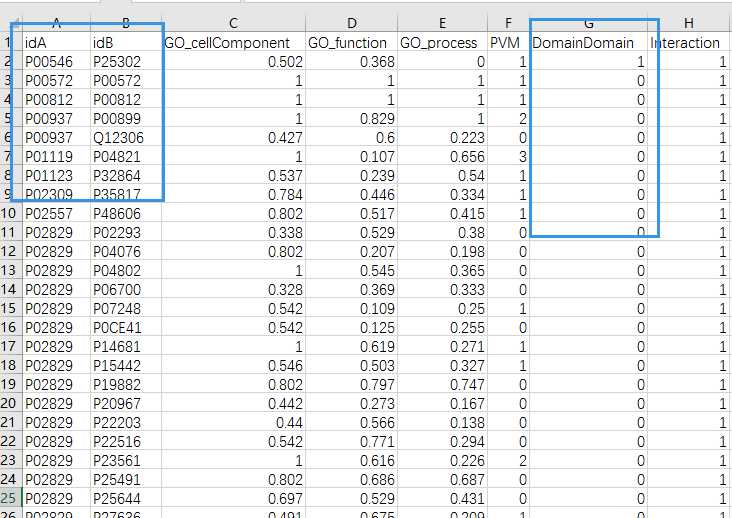
结论
1.结果相差那么大我也不知道什么原因。关于原论文数据的说明文章里也就那一句话。
2.整个过程我想我应该没理解错。
3.从上面那个图我们可以看到P00572和P00812这两个蛋白是自相互作用的。但是他们的可能相互作用域的数目竟然为0 。
这应该怎么理解呢?同一条蛋白,序列应该是相同的,其他数据应该也是一样的才对啊。为什么会有自己跟自己相互作用呢。这又是怎么判断的?
附件列表
以上是关于蛋白质对中可能相互作用域的数目计算的主要内容,如果未能解决你的问题,请参考以下文章
SGPPI: 使用GCN在严格条件下对蛋白质相互作用的结构感知预测Briefings in Bioinformatics, 2023
有一段长度约为1000bp的DNA序列,如何证明其中的PRD区(大约第60-100bp)表达的蛋白与特定蛋白有作用?