机器学习基石(13)--Hazard of Overfitting
Posted cyoutetsu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基石(13)--Hazard of Overfitting相关的知识,希望对你有一定的参考价值。
本节课程主要讲述过拟合。
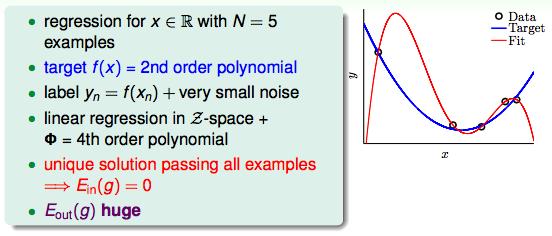
VC Dimension过大的时候会发生Bad Generalization,也就是Ein很低,但是Eout很高的情况。没有办法做举一反三的学习。
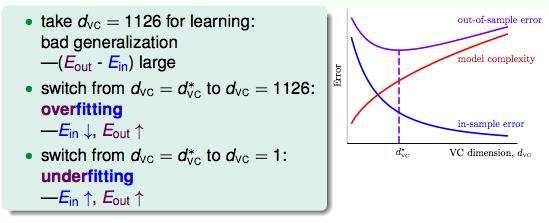
Ein越做越好,但是Eout却上升了。这种情况叫做过拟合。
欠拟合就是做的不好的情况,通过增加VC Dimension可以解决。
假设已知两种10次多项式和50次多项式产生的数据,我们用2次多项式和10次多项式进行拟合,看看Ein和Eout的结果分别是什么样子的。
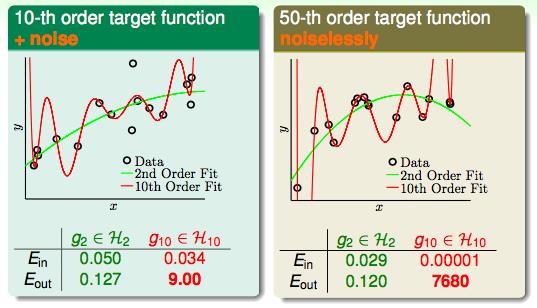
由上图来看,两边都发生了过拟合的情况。
即便我们已知了该数据是由10次多项式产生的,我们再用10次多项式去拟合它的时候也会发生过拟合。并且,2次多项式的Eout也比10次多项式要小。

为什么会这样呢?我们去看一下Learning curve
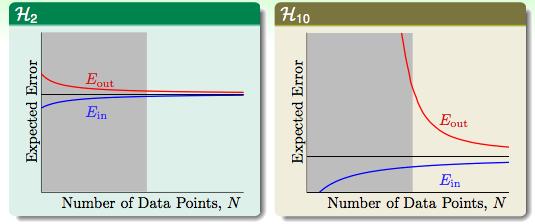
在10次多项式中,当N比较小的时候,generalization的效果不好。所以,当输入数据不够多的时候,还是简单的模型要好一点。
以上都是没有噪声的情况。如果有噪声的时候:
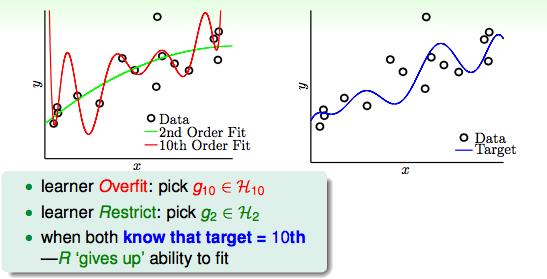
简单的模型依然能够胜出,为什么呢?因为当要学习的事情很复杂的时候,高复杂度本身带来了和有噪声数据一模一样的效果,不管是2次还是10次的多项式都没有办法完美的拟合这些复杂的点,而这些点起到的作用就等同于noise所起到的作用。
什么时候需要小心过拟合的发生呢?
现在假设有一个数据集由正常数据和一部分高斯分布的噪声组成,我们想要看看当噪声的level(记为σ2),模型复杂度(Qf)和f(x)的分布会对整个机器学习的过程有什么影响。

还是以2次多项式和10次多项式为例,两个多项式Eout的差可以用来衡量过拟合的程度:

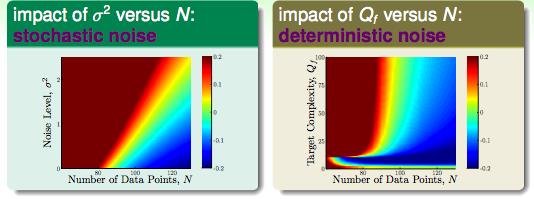
由上图可以得出结论:

stochastic noise:当样本总量很小的时候,会带来实实在在的过拟合。
deterministic noise:如果目标函数太复杂的时候,例如由50次多项式产生的数据集,我们无论怎样拟合都无法完全cover到,复杂数据集中的点就扮演了噪声的角色。
既然过拟合是经常发生的,那我们怎么样才能避免或者解决这个问题呢?

1. 从简单的模型开始着手。
2. 做一些数据的清洗工作。
3. 增加更多的feature进来。
4. 正则化(下一讲)
5. 做验证。
总结:

以上是关于机器学习基石(13)--Hazard of Overfitting的主要内容,如果未能解决你的问题,请参考以下文章
机器学习基石笔记-Lecture 3 Types of learning
机器学习基石--Theory of Generalization
机器学习基石:04 Feasibility of Learning
機器學習基石(Machine Learning Foundations) 机器学习基石 作业四 Q13-20 MATLAB实现