scrapy学习
Posted pythoncoder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy学习相关的知识,希望对你有一定的参考价值。
使用scrapy开发简单爬虫的步骤:
1、创建项目
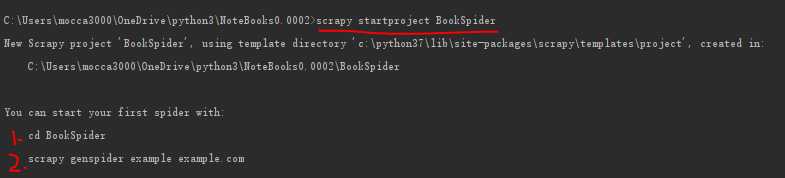
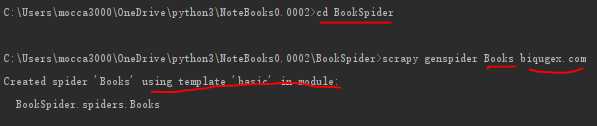
通过以上命令,可以得到下面的目录
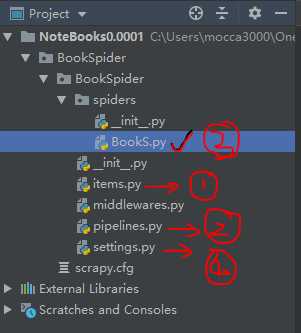
2、开始修改items文件,====这里放置你想要爬取的或者你感兴趣的东西
import scrapy
class BookspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 书名
book_name = scrapy.Field()
# 作者
author = scrapy.Field()
# 分类
book_sort = scrapy.Field()
# 状态
book_status = scrapy.Field()
# 字数
book_size = scrapy.Field()
# 更新时间
book_update = scrapy.Field()
# 最新章节
last_chapter = scrapy.Field()
# 书籍简介
book_intro = scrapy.Field()
# 章节的名称
chapter_name = scrapy.Field()
# 书籍的章节urls
chapter_url = scrapy.Field()
# 章节的内容
chapter_content = scrapy.Field()
# 用于绑定章节顺序,章节编码
chapter_num = scrapy.Field()
3、开始编写各个内容爬取的程序,也就是spider


# -*- coding: utf-8 -*- import scrapy from BookSpider.items import BookspiderItem class BooksSpider(scrapy.Spider): name = ‘Books‘ allowed_domains = [‘biqugex.com‘] # start_urls = [‘http://biqugex.com/‘] def start_requests(self): url = ‘https://www.biqugex.com/book_0‘ for i in range(1, 2): yield scrapy.Request(url.format(i), callback=self.parse) def parse(self, response): books = response.xpath(‘//div[@class="info"]‘) book_name = books.xpath(‘./h2/text()‘).extract()[0] author = books.xpath(‘./div[@class="small"]/span[1]/text()‘).extract()[0].split(‘:‘, 2)[1] book_sort = books.xpath(‘./div[@class="small"]/span[2]/text()‘).extract()[0].split(‘:‘, 2)[1] book_status = books.xpath(‘./div[@class="small"]/span[3]/text()‘).extract()[0].split(‘:‘, 2)[1] book_size = books.xpath(‘./div[@class="small"]/span[4]/text()‘).extract()[0].split(‘:‘, 2)[1] book_update = books.xpath(‘./div[@class="small"]/span[5]/text()‘).extract()[0].split(‘:‘, 2)[1] last_chapter = books.xpath(‘./div[@class="small"]/span[6]/a/text()‘).extract()[0] book_intro = books.xpath(‘./div[@class="intro"]/text()‘).extract_first() chapters = response.xpath(‘//div[@class="listmain"]‘) urls = chapters.xpath(‘./dl/dd/a/@href‘).extract() for url in urls[0:4]: new_link = "https://www.biqugex.com" + url yield scrapy.Request(url=new_link, meta=‘book_name‘: book_name, ‘author‘: author, ‘book_sort‘: book_sort, ‘book_status‘: book_status, ‘book_size‘: book_size, ‘book_update‘: book_update, ‘last_chapter‘: last_chapter, ‘book_intro‘: book_intro, callback=self.detail_parse, dont_filter=False) def detail_parse(self, response): item = BookspiderItem() item[‘book_name‘] = response.meta[‘book_name‘] item[‘author‘] = response.meta[‘author‘] item[‘book_sort‘] = response.meta[‘book_sort‘] item[‘book_status‘] = response.meta[‘book_status‘] item[‘book_size‘] = response.meta[‘book_size‘] item[‘book_update‘] = response.meta[‘book_update‘] item[‘last_chapter‘] = response.meta[‘last_chapter‘] item[‘book_intro‘] = response.meta[‘book_intro‘] chapter_page = response.xpath(‘//div[@class="content"]‘) item[‘chapter_name‘] = chapter_page.xpath(‘./h1/text()‘).extract()[0] item[‘chapter_url‘] = chapter_page.xpath(‘./div[@class="showtxt"]/text()‘).extract()[-2].strip().replace(‘(‘, ‘‘).replace(‘)‘, ‘‘) chapter_content = chapter_page.xpath(‘./div[@class="showtxt"]/text()‘).extract()[0:-3] item[‘chapter_content‘] = ‘\\n‘.join(chapter_content) # item[‘chapter_num‘] = filter(str.isdigit, chapter_page.xpath(‘./h1/text()‘).extract()[0]) yield item
4、开始写pipelines文件,主要是用来把数据写到文件或者数据库中
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import sqlite3 class BookspiderPipeline(object): def __init__(self): self.conn = sqlite3.connect(‘books.db‘) self.cur = self.conn.cursor() self.cur.execute(‘create table if not exists notes(‘ + ‘id integer primary key autoincrement,‘ + ‘book_name,‘ + ‘author,‘ + ‘book_sort,‘ + ‘book_status,‘ + ‘book_size,‘ + ‘book_update,‘ + ‘last_chapter,‘ + ‘book_intro,‘ + ‘chapter_name,‘ + ‘chapter_url,‘ + ‘chapter_content)‘) def close_spider(self, spider): print("=====关闭数据库资源=====") self.cur.close() self.conn.close() def process_item(self, item, spider): self.cur.execute(‘insert into notes values (null, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)‘, (item[‘book_name‘], item[‘author‘], item[‘book_sort‘], item[‘book_status‘], item[‘book_size‘], item[‘book_update‘], item[‘last_chapter‘], item[‘book_intro‘], item[‘chapter_name‘], item[‘chapter_url‘], item[‘chapter_content‘])) self.conn.commit() # def process_item(self, item, spider): # print(item[‘book_name‘]) # print(item[‘author‘]) # print(item[‘book_sort‘]) # print(item[‘book_status‘]) # print(item[‘book_size‘]) # print(item[‘book_update‘]) # print(item[‘last_chapter‘]) # print(item[‘book_intro‘]) # print(item[‘chapter_name‘]) # print(item[‘chapter_url‘]) # print(item[‘chapter_content‘]) # print(item[‘chapter_num‘])
5、配置setting中的一些参数
# -*- coding: utf-8 -*- # Scrapy settings for BookSpider project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘BookSpider‘ SPIDER_MODULES = [‘BookSpider.spiders‘] NEWSPIDER_MODULE = ‘BookSpider.spiders‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘BookSpider (+http://www.yourdomain.com)‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 1 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ‘ ‘(KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0‘, ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8‘, # Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html SPIDER_MIDDLEWARES = ‘BookSpider.middlewares.BookspiderSpiderMiddleware‘: 543, # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = ‘BookSpider.middlewares.BookspiderDownloaderMiddleware‘: 543, # Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = # ‘scrapy.extensions.telnet.TelnetConsole‘: None, # # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = ‘BookSpider.pipelines.BookspiderPipeline‘: 300, # Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 0 HTTPCACHE_DIR = ‘httpcache‘ HTTPCACHE_IGNORE_HTTP_CODES = [] HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘
好了,小说的爬虫做好了
以上是关于scrapy学习的主要内容,如果未能解决你的问题,请参考以下文章