Scrapy学习-
Posted hhwblogs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy学习-相关的知识,希望对你有一定的参考价值。
Scrapy框架介绍
Scrapy是一个非常优秀的爬虫框架,基于python。
只需要在cmd运行pip install scrapy就可以自动安装。用scrapy-h检验是否成功安装
Scrapy部署一个简单的爬虫库,是一个爬虫框架。此外和requests库相比,Scrapy库适合大型爬虫,适合网站爬虫。
爬虫框架
爬虫框架是实现爬虫功能的一个软件结构和功能组件的集合,是一个半成品,能够帮助用户实现专业网络爬虫。
Scrapy框架有几个主要的板块,形成“5+2”结构,板块之间的路径关系如下图。
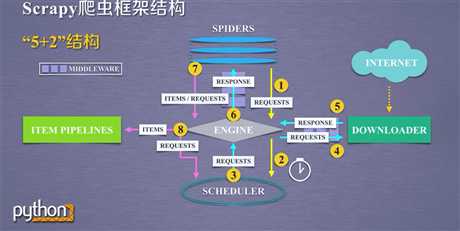
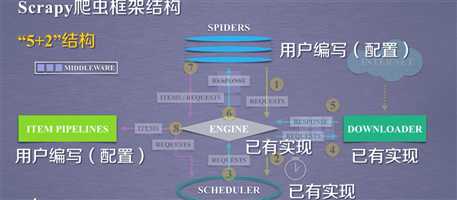
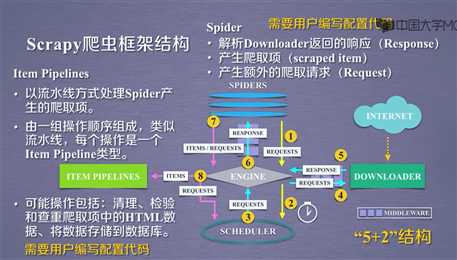
Scrapy框架的入口是SPIDERS,出口是ITEM PIPELINES。只有入口和出口是需要用户编写的。其他都是内部写好的。
Scrapy库的主要命令
用scrapy-h进入命令行
命令行格式 >scrapy
| 代码 | 作用 | 格式 |
|---|---|---|
| startproject | 创建一个新的工程 | scrapy startproject |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| setting | 获得爬虫的配置信息 | scrapy setting [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动url调试命令行 | scrapy shell[url] |
我们需要理解工程和爬虫的爬虫的区别。
注意Scrapy爬虫是用命令行爬虫的,最初设计是给程序员使用的,没有图形界面。
Scrapy爬虫的一个实例
建立一个爬虫工程
打开cmd,用cd命令调整到特定的文件夹,建立一个工程。例如:scrapy startproject python123demo
建立好了后,工程会生成一个目录,这个目的就是这个工程。
这个目录包含一个部署爬虫的配置文件scrapy.cfg ,包含一个初始化脚本__init__.py,一个Items代码模板(继承类)item.py
Middlewares模板(继承类)middlewares.py,Piplines代码模板(继承类)pipelines.py,Scrapy爬虫配置文件 settings.py
下面有一个spiders/目录 里面是Spiders代码模板目录(继承类)存放是建立的爬虫
建立一个爬虫
打开命令行输入scrapy genspider demo来建立一个爬虫,生成一个demo.py文件到你的cmd路径。不要忘记修改cmd的路径到spyder下。

配置产生的爬虫
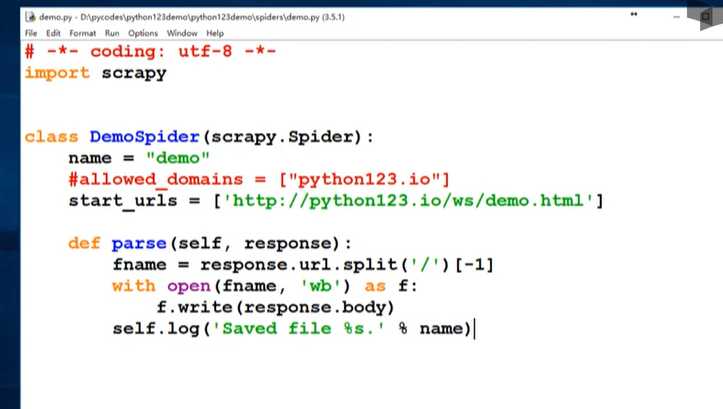
打开demo文件,修改里面的代码。
运行爬虫
打开命令行,输入scrapy crawl demo,执行后会出现一个demo.html文件,这个文件就是网页源码。
下面是demo.py完整代码
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = ‘demo‘
#allowed_domains = [‘python123.io‘]
def start_request(scrapy.Spider):
urls = {‘http://python123.io/ws/demo.html‘}
for url in urls:
yield scrapy.Request(url=url ,callback=self.parse)
def parse(self, response):
fname = response.url.split(‘/‘)[-1]
with open(fname , ‘wb‘) as f:
f.write(response.body)
self.log(‘Saved file %s.‘ % name)
以上是关于Scrapy学习-的主要内容,如果未能解决你的问题,请参考以下文章