Scrapy框架学习笔记
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy框架学习笔记相关的知识,希望对你有一定的参考价值。
文章目录
一、Scrapy框架概述
(一)网络爬虫
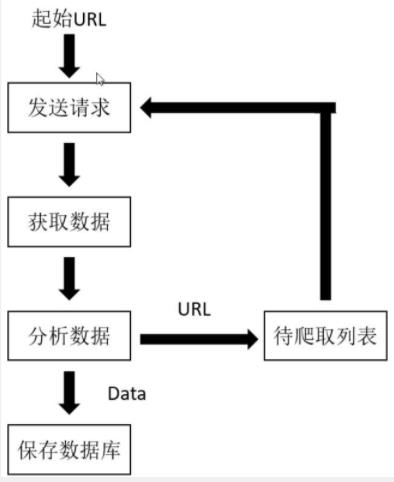
- 网络爬虫:在本质上就是模拟用户在浏览器上操作,发送请求,接收响应,然后分析并保存数据,只不过这个过程通过代码实现了大量的自动化操作。

- 爬虫基本流程
爬虫学习笔记:爬取单张图片
(二)Scrapy框架
- Scrapy是一个使用Python实现的,为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。只需要定制开发几个模块就可以轻松地实现一个爬虫,用来抓取网页内容以及各种图片,非常方便。Scrapy使用了Twisted异步网络框架来处理网络通信,可以加快下载速度,并且包含各种中间件接口,可以灵活地完成各种需求。

(三)安装Scrapy框架
- 在控制台执行
pip install scrapy
(四)Scrapy核心组件
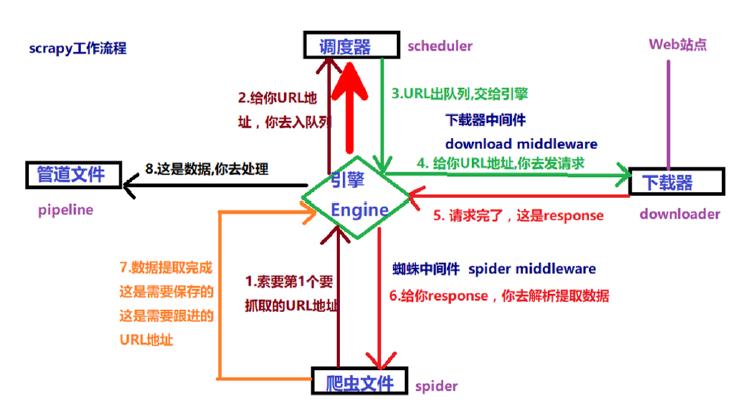
- Scrapy框架包括五大核心组件,分别是
引擎、调度器、下载器、爬虫文件、管道。此外下载器中间件(Downloader Middlewares) 位于引擎和下载器,用于包装请求(随机代理等),蜘蛛中间件(SpiderMiddlewares) 位于引擎和爬虫文件,可修改响应对象属性。

(五)Scrapy工作流程
二、 Scrapy案例演示
(一)爬取目标 - 腾讯招聘网

(二)创建PyCharm项目
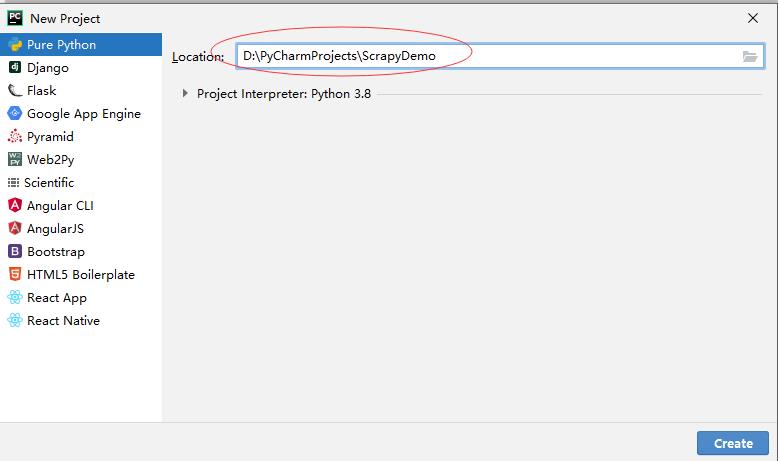
- 创建PyCharm项目 - ScrapyDemo
(三)创建Scrapy项目
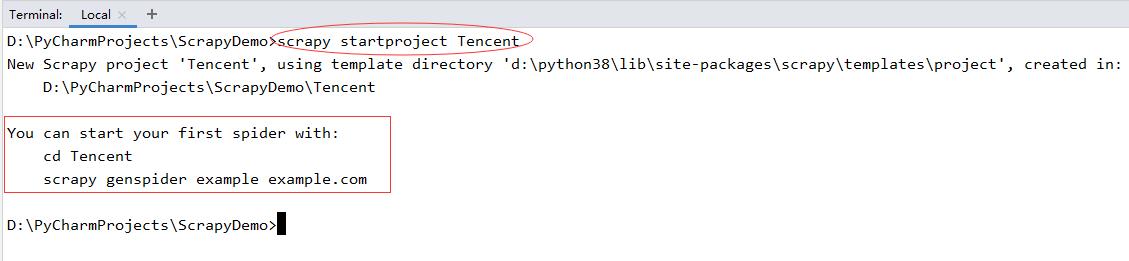
1 、创建Scrapy项目
- scrapy startproject Tecent

2、生成爬虫程序
D:\\PyCharmProjects\\ScrapyDemo>cd Tencent>
D:\\PyCharmProjects\\ScrapyDemo\\Tencent>scrapy genspider tencent careers.tencent.com
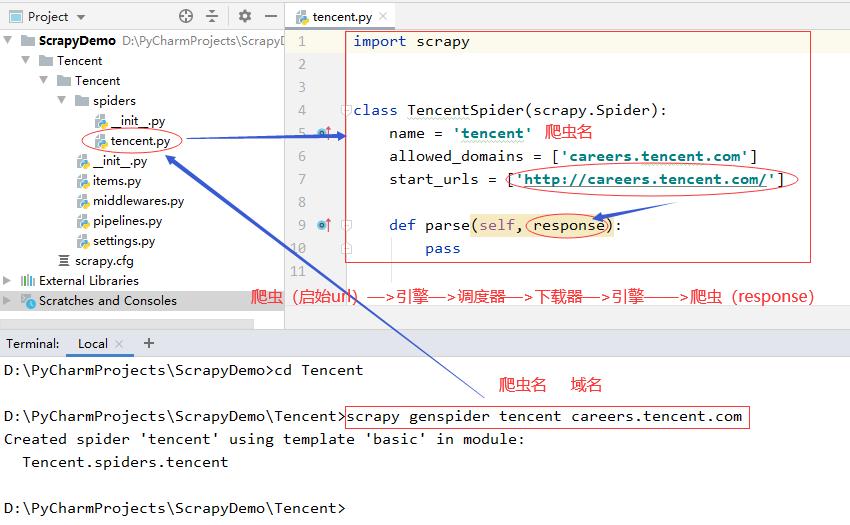
- 执行了生成爬虫命令之后,在项目spiders目录里会自动生成指定的爬虫程序
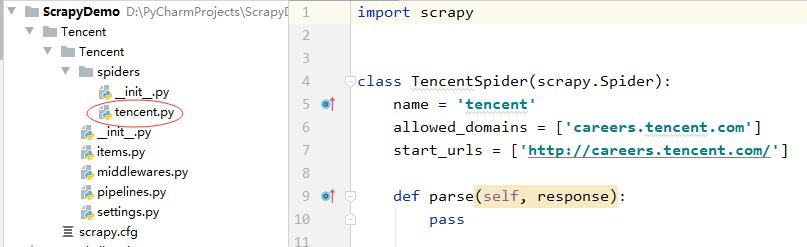
3、爬虫程序说明
(1)爬虫类
创建爬虫生成的class XXXSpider(scrapy.Spider)类中几个重要的属性:
name:是字符串,用于设置spider的名字,实际中一般为每个独立网站创建一个spider。allowed_domains:是一个字符串列表。规定了允许爬取的网站域名,非域名下的网页将被自动过滤。strart_urls:是一个必须定义包含初始请求页面URL的列表。start_requests()方法会引用该属性,发出初始的Request。parse(self, response):引擎默认的响应处理函数。如果没有在Request中指定响应处理函数,那么引擎会调用这个函数。
(2)response对象
parse(self,response)中的response对象常用属性如下表所示:
| 属性 | 作用 |
|---|---|
| body | HTTP响应正文,bytes类型 |
| text | 文本形式的HTTP响应正文,str类型,由response.body解码得到 |
| xpath(query) | 通过xpath表达式从下载的页面中提取数据 |
- 常见xpath表达式含义如下表所示
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取 |
| // | 从所有节点中查找(包括子节点和后代节点) |
| . | 当前节点位置 |
| ./ename | 选择当前节点下所有名为ename 的子元素 |
| … | 当前节点的父节点 |
| @ | 获取属性 如:@href @src |
| [] | 中括号内放筛选的条件 |
| text() | 获取节点文本内容 |
4、修改项目配置文件

- 设置
User-Agent - 设置
ROBOTSTXT_OBEY = False - 设置
CONCURRENT_REQUESTS = 1 - 设置
DOWNLOAD_DELAY = 2 - 设置
DEFAULT_REQUEST_HEADERS,添加了User-Agent键值对 - 其余的暂时没有进行设置
# Scrapy settings for Tencent project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'Tencent'
SPIDER_MODULES = ['Tencent.spiders']
NEWSPIDER_MODULE = 'Tencent.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.35 Safari/537.36'
# Obey robots.txt rules
# 是否遵守robots协议,默认为True,表示遵守,通常要改为False
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 最大并发请求数量,默认是16,没有代理服务器,设置大了,就容易被封掉,因此设置为1
CONCURRENT_REQUESTS = 1 # 单线程下载
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 2 # 下载延迟为2秒
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
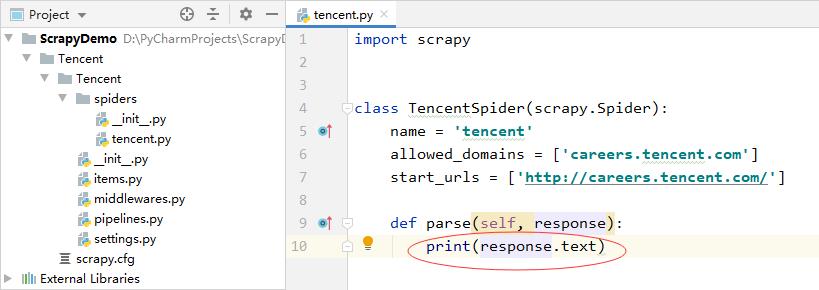
5、修改爬虫程序 tencent.py
- 在parse方法里添加一条语句,打印响应对象的文本属性
6、运行爬虫程序
- 语法格式:scrapy crawl 爬虫名
D:\\PyCharmProjects\\ScrapyDemo\\Tencent>scrapy crawl tencent
以上是关于Scrapy框架学习笔记的主要内容,如果未能解决你的问题,请参考以下文章