MapReduce 应用:TF-IDF 分布式实现
Posted Q-WHai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce 应用:TF-IDF 分布式实现相关的知识,希望对你有一定的参考价值。
概述
本文要说的 TF-IDF 分布式实现,运用了很多之前 MapReduce 的核心知识点。算是 MapReduce 的一个小应用吧。
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Q-WHai
发表日期: 2016年6月24日
本文链接:https://qwhai.blog.csdn.net/article/details/51747801
来源:CSDN
更多内容:分类 >> 大数据之 Hadoop
学前导读
本文并不打算再啰里啰嗦地讲解一大堆 TF-IDF 的概念,以及 TF-IDF 能够做什么。如果你对此还不够了解,可以转到我的另一篇博客《 数据挖掘:基于TF-IDF算法的数据集选取优化 》进行学习。
由于本人的语言表达可能并不十分简单明了,如果你阅读本文的时候遇到一些难以理解的地方,可以点击下面相关的链接进行学习。这些都是本文的基础和前提,当然也可以提交评论与我进行交流。
- 《 数据挖掘:基于TF-IDF算法的数据集选取优化 》
- 《 从 WordCount 到 MapReduce 计算模型 》
- 《 MapReduce 进阶:多 MapReduc e的链式模式 》
- 《 MapReduce 进阶:多路径输入输出 》
- 《 MapReduce 进阶:Partitioner 组件 》
算法框架
首先我们来看一下,分布式的 TF-IDF 的算法框架图:
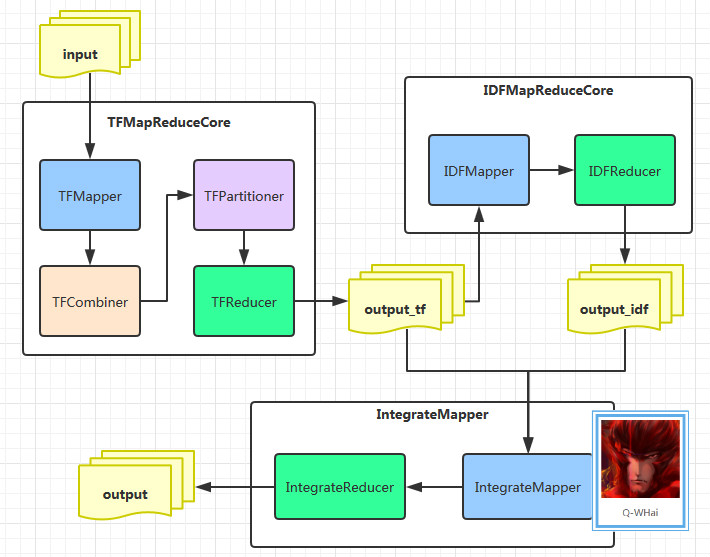
在图中,我们有三个大模块,这三个大模块正是 MapReduce 中的三个 Job。
在学习 TF-IDF 的时候我们就知道了,TF-IDF 的计算可以分成三个部分进行。第一个阶段:计算各个文档中每个单词的 TF 值;第二阶段:计算所有文档中所有单词的 IDF 值;第三个阶段:计算各个文档中各个单词的 TF-IDF 值。在单机的环境下,很容易实现这些计算。可是,分布式环境下要怎么做呢?于是,根据这三个阶段,我设计了上面的架构图。
TFMapReduceCore 类包含的是计算 TF 的核心类,IDFMapReduceCore 中则包含了 IDF 的核心类,IntegrateCore 中包含的是将 TF、IDF 的结果进行整合,从而计算最终的 TF-IDF 结果。且这里还产生了两个中间输出目录,而这两个中间输出目录也正是第三个阶段的输入目录,这一步中,需要用到 MapReduce 的多路径输入。上面也有专门的文章描述了这一块。
代码实现
TFMapReduceCore
这里我将与计算 TF 相关的代码封装在同一个 TFMapReduceCore 类中,其中的 TFMapper, TFReducer 等都是 TFMapReduceCore 类的一个子类。
TFMapper
public static class TFMapper extends Mapper<Object, Text, Text, Text> {
private final Text one = new Text("1");
private Text label = new Text();
private int allWordCount = 0;
private String fileName = "";
@Override
protected void setup(Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
fileName = getInputSplitFileName(context.getInputSplit());
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
while (tokenizer.hasMoreTokens()) {
allWordCount++;
label.set(String.join(":", tokenizer.nextToken(), fileName));
context.write(label, one);
}
}
@Override
protected void cleanup(Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
context.write(new Text("!:" + fileName), new Text(String.valueOf(allWordCount)));
}
private String getInputSplitFileName(InputSplit inputSplit) {
String fileFullName = ((FileSplit)inputSplit).getPath().toString();
String[] nameSegments = fileFullName.split("/");
return nameSegments[nameSegments.length - 1];
}
}
因为我们输入的源文件是用一个文件表示一个分类,如果你是以其他规则划分,那么可以不必遵从本文的逻辑。上面我首先在 setup() 里获取文件名,这样做的目的在于不用在 map() 中重复获取,从而提升程序的效率。并且在 cleanup() 里把文件名(也就是分类)信息写入到 Mapper 的输出路径中。
大家可能注意到了这里我写入文件名的时候,使用了一个技巧,使用“!”充当了一个单词。因为这个字符的 ASCII 码比所有的字符的 ASCII 码都要小,这样做的目的是可以让这条记录在其他所有记录之前被访问( 这里所指的其他所有记录指的是,同一个分类中的所有记录。因为这里我们有对 Mapper 的输出做 Partitioner 分区 )。
TFCombiner & TFReducer
从上面的 Mapper 中可以看到 Mapper 输出的 key 的格式为: : 。如此,只要去解析 key 中的 keyword 就可以了。而在 Mapper 的 cleanup() 方法中还写入文件的信息。这样一来,我们就可以使用这个 “!: allWordCount” 对每个文件进行区分开来。区分的原理之前也说到过了,就是因为 “!” 的 ASCII 码最小的原因。
public static class TFCombiner extends Reducer<Text, Text, Text, Text> {
private int allWordCount = 0;
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
if (values == null) {
return;
}
if(key.toString().startsWith("!")) {
allWordCount = Integer.parseInt(values.iterator().next().toString());
return;
}
int sumCount = 0;
for (Text value : values) {
sumCount += Integer.parseInt(value.toString());
}
double tf = 1.0 * sumCount / allWordCount;
context.write(key, new Text(String.valueOf(tf)));
}
}
通过上面的 Combiner 的 reduce 操作之后,所有单词的 TF 值都已经计算完成。再通过一次 Reducer 操作就 ok 了。Reducer 的代码如下:
public static class TFReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (values == null) {
return;
}
for (Text value : values) {
context.write(key, value);
}
}
}
TFPartitioner
在 Partitioner 分区这一块,就简单地以自定义的 Hash Partitioner 作为分区类。如果你有更加严格的要求,可以参考我之前的博客《MapReduce 进阶:Partitioner 组件》。
public static class TFPartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String fileName = key.toString().split(":")[1];
return Math.abs((fileName.hashCode() * 127) % numPartitions);
}
}
IDFMapReduceCore
这里我将与计算 IDF 相关的代码封装在同一个 IDFMapReduceCore 类中,其中的 IDFMapper, IDFReducer 都是 IDFMapReduceCore 类的一个子类。
IDFMapper
因为 IDF 的计算是针对所有文档的,所以在 IDFMapper 中可以直接按照计算 WordCount 的逻辑来编写就 ok 了。因为在计算 IDF 时,我们不需要关心某一个单词的词频,所以这里统一的使用 1 填充 mapper 的输出 value.
public static class IDFMapper extends Mapper<Object, Text, Text, Text> {
private final Text one = new Text("1");
private Text label = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
label.set(tokenizer.nextToken().split(":")[0]);
context.write(label, one);
}
}
IDFReducer
在前面我们已经统计了某一个单词在某一个文档(分类)出现的标志,也就是单词 W 在文档 D 中出现过了一次。这样一来,我们就可以统计出单词 W 在全部文档中出现过多少次了。而这一思想,正是计算 WordCount 逻辑。所以代码很好编写。等等,我们还需要计算所有的文档数。是的,在计算 IDF 的公式中,我们需要知道一共有多少个文档。可是,在当前的情况下我们无法获得这个值,因为这是在 Reducer 中。虽然在 Reducer 里面无法计算文档总数,但是在 Reducer 外面却可以。这个过程就是纯粹的 Java 逻辑,很简单,不多说了。
当我们知道了训练文档总数,就可以通过 job 将信息传递给 Reducer。只是这里我们并不是调用 job.setNumReduceTasks(N),而是调用了 job.setProfileParams(msg) 方法。
public static class IDFReducer extends Reducer<Text, Text, Text, Text> {
private Text label = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (values == null) {
return;
}
int fileCount = 0;
for (Text value : values) {
fileCount += Integer.parseInt(value.toString());
}
label.set(String.join(":", key.toString(), "!"));
int totalFileCount = Integer.parseInt(context.getProfileParams()) - 1;
double idfValue = Math.log10(1.0 * totalFileCount / (fileCount + 1));
context.write(label, new Text(String.valueOf(idfValue)));
}
}
IntegrateCore
这里我将与计算 TF-IDF 相关的代码封装在同一个 IntegrateCore 类中,其中的 IntegrateMapper, IntegrateReducer 都是 IntegrateCore 类的一个子类。在计算的最后一步中,没有什么需要说明的地方。只是,前面计算 TF、IDF 产生的中间输出文件的格式并不统一,所以这里需要对不同格式的文件内容进行不同的考虑。
IntegrateMapper
public static class IntegrateMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
context.write(new Text(tokenizer.nextToken()), new Text(tokenizer.nextToken()));
}
}
IntegrateReducer
public static class IntegrateReducer extends Reducer<Text, Text, Text, Text> {
private double keywordIDF = 0.0d;
private Text value = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (values == null) {
return;
}
if (key.toString().split(":")[1].startsWith("!")) {
keywordIDF = Double.parseDouble(values.iterator().next().toString());
return;
}
value.set(String.valueOf(Double.parseDouble(values.iterator().next().toString()) * keywordIDF));
context.write(key, value);
}
}
测试运行
数据源
android
java
activity
map
hadoop
map
reduce
ssh
mapreduce
ios
iphone
jobs
java
java
code
eclipse
java
map
python
python
pycharm
执行命令
执行此命令之前,请先将测试数据上传到 HDFS 的 /input 目录下。
$ hadoop jar temp/run.jar /input /output
执行结果
activity:android 0.0994850021680094
android:android 0.0994850021680094
code:java 0.07958800173440753
eclipse:java 0.07958800173440753
ios:ios 0.13264666955734586
iphone:ios 0.13264666955734586
java:android 0.0554621874040891
java:java 0.08873949984654256
jobs:ios 0.13264666955734586
map:android 0.024227503252014105
map:hadoop 0.024227503252014105
map:java 0.019382002601611284
mapreduce:hadoop 0.0994850021680094
pycharm:python 0.1989700043360188
python:python 0.1989700043360188
reduce:hadoop 0.0994850021680094
ssh:hadoop 0.0994850021680094
看到这个结果你可能会认为这个结果不一定可靠。如果你怀疑这些结果,你可以自己编写一个单机版的 Java 程序进行验证。当然,我已经验证过了。
Job
此处是浏览器登录 Cluster Metrics 的信息展示。显示的是程序在执行完成之后的内容,看到有三个 Job 参与了 TF-IDF 的计算。

GitHub download
- https://github.com/Hadoop-league/TF-IDF_MR
征集
如果你也需要使用ProcessOn这款在线绘图工具,可以使用如下邀请链接进行注册:
https://www.processon.com/i/56205c2ee4b0f6ed10838a6d
以上是关于MapReduce 应用:TF-IDF 分布式实现的主要内容,如果未能解决你的问题,请参考以下文章