如何用mapreduce分布式实现kmeans算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用mapreduce分布式实现kmeans算法相关的知识,希望对你有一定的参考价值。
参考技术A 可以自己尝试写一个分布式的kmeans,也可以部署spark,使用spark-mllib里面的kmeans如果对python比较熟悉,可以使用pyspark的mllib如果只是hadoop,找找mahout算法包算法技术专题如何用Java实现一致性 hash 算法( consistent hashing )(上)
一致性hash的历史
【Consistent Hashing算法】早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛;
一致性hash的目的
一致性哈希算法是分布式系统中常用的算法,一致性哈希算法解决了普通余数Hash算法伸缩性差的问题,可以保证在上线、下线服务器的情况下尽量有多的请求命中原来路由到的服务器。
问题背景
业务开发中,我们常把数据持久化到数据库中,如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,更多地引入缓存来对数据进行存取。
分布式缓存
分布式缓存,不同机器上存储不同对象的数据。为了实现这些缓存机器的负载均衡,一般就会存在两种Hash算法进行均匀分配数据节点存储:普通Hash算法
普通的Hash算法的
Hash取模做法的缺陷
一个Redis集群中,如果我们把一条数据经过Hash,然后再根据集群节点数取模得出应该放在哪个节点,这种做法的缺陷在于:扩容(增加一个节点)之后,有大量缓存失效。
普通Hash的案例分析
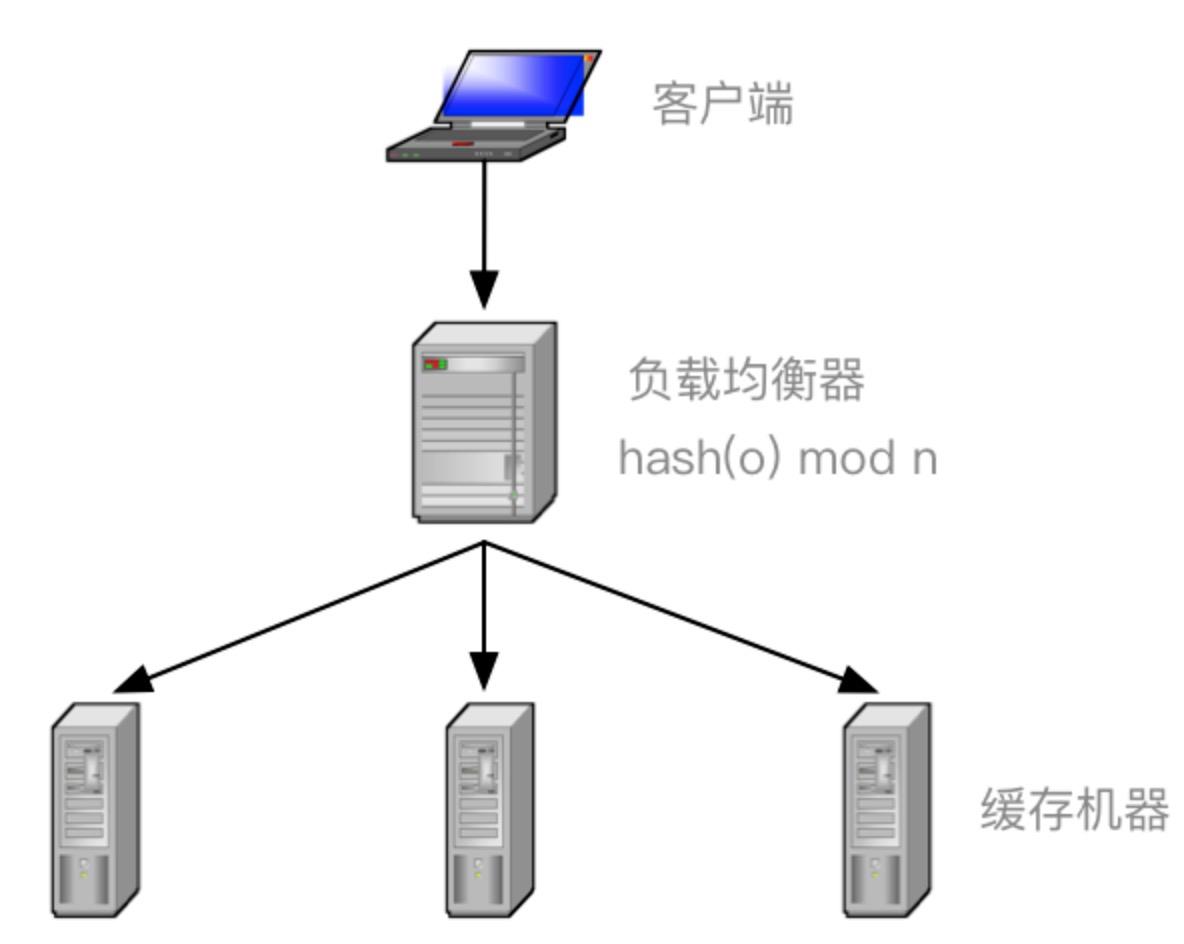
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
-
一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
-
由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
-
这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;(造成缓存雪崩机制)
一致性Hash算法
一致性hash算法正是为了解决此类问题的方法,它可以保证当机器增加或者减少时,对缓存访问命中的概率影响减至很小。下面我们来详细说一下一致性hash算法的具体过程。
-
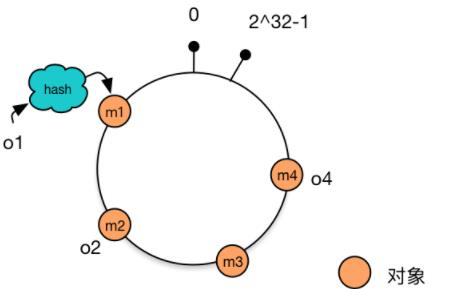
一致性hash算法通过一个叫作一致性hash环的数据结构实现。这个环的起点是0,终点是2^32 - 1,并且起点与终点连接,环的中间的整数按逆时针分布,故这个环的整数分布范围是[0, 2^32-1]
-
整个哈希值空间组织成一个虚拟的圆环,将节点的IP地址或主机名作为关键字进行哈希计算,得出的结果作为节点在环上的位置。数据经过hash后按顺时针方向找到最近一个节点存放,如图data的hash位置,应该存放在node2。
-
相比Hash取模,一致性Hash算法的优点就是扩容后影响的缓存数据较少,如果是n个节点扩容到n+1个的话,影响的缓存数是0~1/n,即最多让一个节点的缓存失效。
-
他的缺点是,缓存在每个节点上分布不均,毕竟hash值随机,那节点在环上的位置也随机。
改良版一致性Hash算法
一致性Hash算法 + 虚拟节点
为了解决数据分布不均的问题,我们引入虚拟节点的概念。我们对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。定位到虚拟节点的数据就存到该虚拟节点对应的真实节点上,这样数据分布就相对均匀了,虚拟节点数越多,分布越均匀。
引入“虚拟节点”后,映射关系就从 对象 -> 节点 转换到了 对象 -> 虚拟节点 。查询物体所在 cache 时的映射关系
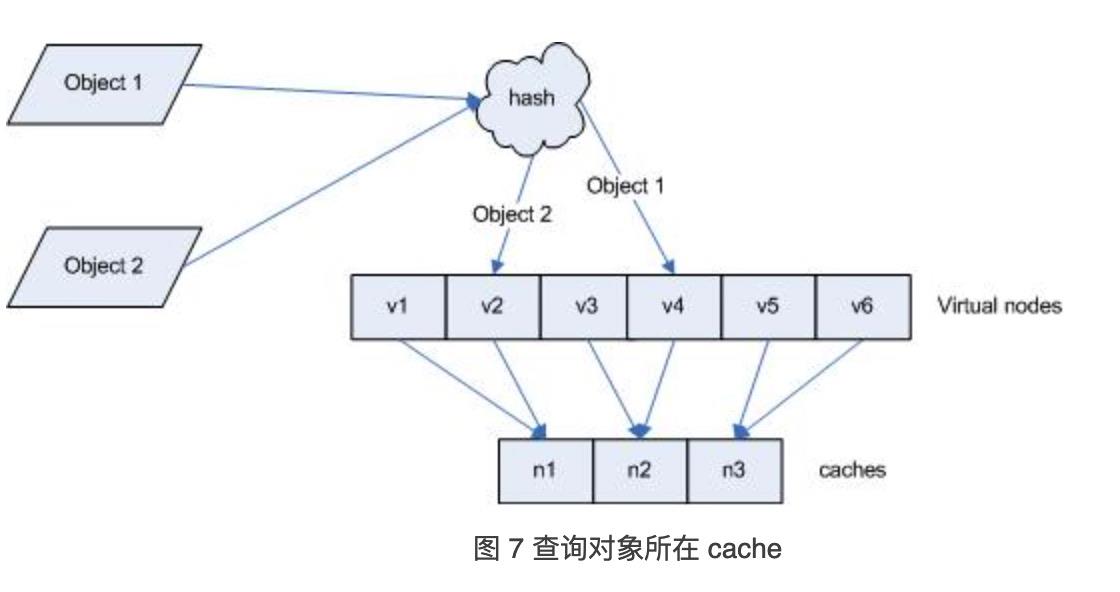
一般虚拟节点数32个以上,dubbo是160个。

处理机器增减的情况
对于线上的业务,增加或者减少一台机器的部署是常有的事情。
例如,增加机器c4的部署并将机器c4加入到hash环的机器c3与c2之间。这时,只有机器c3与c4之间的对象需要重新分配新的机器。对于我们的例子,只有对象o4被重新分配到了c4,其他对象仍在原有机器上。
一致性Hash算法的实现原理
在业务开发中,我们常把数据持久化到数据库中。如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取。读取数据的过程一般为:
Java代码实现Hash算法的实现
用一个TreeMap来作为环,key为虚拟节点下标,value为真实节点的hash。个人感觉可以加一个Map<T, Set>来维护真实节点-虚拟节点的关系。
/**
* 一致性Hash算法
* 算法详解:http://blog.csdn.net/sparkliang/article/details/5279393
* 算法实现:https://weblogs.java.net/blog/2007/11/27/consistent-hashing
* @author xiaoleilu
*
* @param <T> 节点类型
*/
public class ConsistentHash<T> implements Serializable
private static final long serialVersionUID = 1L;
/** Hash计算对象,用于自定义hash算法 */
Hash32<Object> hashFunc;
/** 复制的节点个数 */
private final int numberOfReplicas;
/** 一致性Hash环 */
private final SortedMap<Integer, T> circle = new TreeMap<>();
/**
* 构造,使用Java默认的Hash算法
* @param numberOfReplicas 复制的节点个数,增加每个节点的复制节点有利于负载均衡
* @param nodes 节点对象
*/
public ConsistentHash(int numberOfReplicas, Collection<T> nodes)
this.numberOfReplicas = numberOfReplicas;
this.hashFunc = key ->
//默认使用FNV1hash算法
return HashUtil.fnvHash(key.toString());
;
//初始化节点
for (T node : nodes)
add(node);
/**
* 构造
* @param hashFunc hash算法对象
* @param numberOfReplicas 复制的节点个数,增加每个节点的复制节点有利于负载均衡
* @param nodes 节点对象
*/
public ConsistentHash(Hash32<Object> hashFunc, int numberOfReplicas, Collection<T> nodes)
this.numberOfReplicas = numberOfReplicas;
this.hashFunc = hashFunc;
//初始化节点
for (T node : nodes)
add(node);
/**
* 增加节点<br>
* 每增加一个节点,就会在闭环上增加给定复制节点数<br>
* 例如复制节点数是2,则每调用此方法一次,增加两个虚拟节点,这两个节点指向同一Node
* 由于hash算法会调用node的toString方法,故按照toString去重
* @param node 节点对象
*/
public void add(T node)
for (int i = 0; i < numberOfReplicas; i++)
circle.put(hashFunc.hash32(node.toString() + i), node);
/**
* 移除节点的同时移除相应的虚拟节点
* @param node 节点对象
*/
public void remove(T node)
for (int i = 0; i < numberOfReplicas; i++)
circle.remove(hashFunc.hash32(node.toString() + i));
/**
* 获得一个最近的顺时针节点
* @param key 为给定键取Hash,取得顺时针方向上最近的一个虚拟节点对应的实际节点
* @return 节点对象
*/
public T get(Object key)
if (circle.isEmpty())
return null;
int hash = hashFunc.hash32(key);
if (false == circle.containsKey(hash))
SortedMap<Integer, T> tailMap = circle.tailMap(hash); //返回此映射的部分视图,其键大于等于 hash
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
//正好命中
return circle.get(hash);
以上是关于如何用mapreduce分布式实现kmeans算法的主要内容,如果未能解决你的问题,请参考以下文章
殊途同归:如何用Spark来实现已有的MapReduce程序
算法技术专题如何用Java实现一致性 hash 算法( consistent hashing )(上)