如何用Python对人员轨迹聚类
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python对人员轨迹聚类相关的知识,希望对你有一定的参考价值。
目前我的数据(csv格式)只有人员id和他们的坐标轨迹xy,不知道有几类人;我想让这么多人的轨迹聚类,从而能清楚看出各类人的运动规律。应该采用哪种聚类算法呢?用Python怎么实现呢?

KMeans, DBScan, 层次聚类,等等都是可以的追问
请问怎样将我的轨迹数据xy变换成onehot呢?(因为我的xy轨迹数据是很多坐标组成的)有没有具体代码,谢谢了
参考技术A K Means聚类追问请问有具体的代码吗?我也找了很多K-means聚类代码,但是我的数据不好与他的代码兼容
追答你可以在他/她的床上大便;往他/她的鞋里尿尿;把养的各种昆虫放进他/她的柜子和包包里面;在纸上画个圈圈诅咒他/她,再把那张纸寄给他/她;把他/她的电话号码透露给各种广告骗子之类的组织,或者写在外面标注上「办证/通下水/变态」之类的恶心东西。
参考技术B 请问您的问题解决了吗?时间序列中的轨迹聚类
时间序列的聚类在时间序列分析中是非常重要的课题,在很多真实工业场景中非常有用,如潜在客户的发掘,异常检测,用户画像构建等。不同于一般样本聚类方式,时间序列因为其独特的时变特性,很多研究者都在探寻如何对其轨迹进行聚类。
然而轨迹聚类非常有挑战。首先,时间序列一般存在大量的噪声,这会引入较大的误差;其次,时间序列很多时候存在错位匹配的情况,需要采用相似性度量算法来解决,实际中需要根据场景做额外处理;最后,聚类方法和参数选择也有不少的讲究。整体来说,时序的轨迹聚类需要借助大量的领域知识来共同完成。
本期文章针对这些问题,为大家整理轨迹聚类的相关知识,包括时序数据的预处理,表示,压缩,以及相似性度量等,供研究者和开发者们参考。
表示与相似性度量
时间序列的表示其实是一个很广义的问题,此处只讨论和本问题相关的一些方法。首先要明确一点:为什么需要时间序列表示?时间序列表示的意义在于如何去定义后续的相似性度量,两者是相辅相成的。
时间序列的表示其实没有什么限制条件,目的只有一个:尽可能保留完整的信息量。而相似性度量一般都会有一些规范需要遵循,否则定义出来的相似性就失去了物理含义,也无法服务后续的聚类等分析方法。为了定义的方便,我们把相似性视为距离的倒数,这样相似性的定义就转为距离的定义。在距离的定义中其中最常见的、也是最基本的就是以下三个条件:
两个时间序列的距离是非负的,当且仅当两个时间序列是完全相同的时候,距离才为0;
满足对称性,也即 d(a,b)=d(b,a),或者小于某个阈值 ||d(a,b)-d(b,a)||<ε ;
三角不等式,也即 d(a,c)≤ d(a,b)+d(b,c)。
基于以上的假设,我们直接把时间序列的数值作为时间序列的表示,用对应时间点之间的欧式距离之和作为距离,那么我们就得到了最简单的定义。看上去一些似乎都很顺利,我们拿到了一个结果,然后就可以去做后面的聚类了。然而在实际的应用中,会面临很多问题。
采用欧式距离合适吗?
欧式距离最大的问题就是会被噪声或是离群点所影响。比如以下两对时间序列:第一组是十个时间点、均值为0方差为1的时间序列,第二组是十个时间点、均值为0方差为0.6的时间序列,其中一个时间序列包含一个离群点。我们可以调整离群点的值使得两对时间序列的欧式距离接近。如果在物理意义上,我们期望这两组时间序列的距离是不一致的,这就说明我们的定义是不合理的,或者说这不是我们期望的定义。因此我们希望我们的距离定义能够具有普适性,以适应不同时间序列特性的区分,比如闵可夫斯基距离:

闵可夫斯基距离可以视为一组距离的定义,可以通过参数p调整距离对时间序列特性的适应,特别的,当 p=2 的时候就是欧式距离。如果我们希望突出两个时间点之间存在差异,而非差异度,我们可以让p值调小;反之,我们希望突出两个时间点之间的差异度,那我们可以让p值调大。极端的情况,当p趋近于0,结果是有几对时间点直接存在差异;当p趋于无穷大,结果是时间点对之间距离对最大值。因此,我们要剔除离群点的影响,可以把p值调小,要剔除噪声的影响可以把p值调大。
当然,我们也有其他的方法来解决这一问题。比如还是针对离群点和噪声,我们可以采用离散化的思路来解决,把一定范围内的距离差视为一类,把大于一定阈值的距离差视为一类,这样就弱化了它们带来的影响。其实这就是一种符号匹配的思想,将时间序列语义化映射到符号或者字符串上,不仅仅是离散化,也可以直接来表示时间点之间的差值或者变化率等信息。基于这样的表达方式,我们就不能采用数值型的距离度量来进行相似度的计算了,但是我们可以引入文本相似度的计算逻辑,比如说Hamming距离或者Jaccard距离。
在定义距离的时候我们也会遇到机器学习中最常见的问题——维度灾难。也即,当时间序列过长时,会导致距离的差异会逐渐接近,从而无法区分。这个时候需要做的和机器学习中一样,对时间序列进行降维。时间序列的降维思路也比较多,常见的有两大类:
做全局拟合或分段拟合,一般是用线性函数或是多次函数,或者根据物理公式去拟合。
去做频域变换,通过频谱特征来表示时间序列。通常可以去做64、128或256点的FFT,也可以使用小波变换等方法。很明显,这个维度是可控的。
如何解决时间序列不对齐的问题?
上述的定义都是假设在时间序列对齐的情况下,也即我们假设时间序列长度是相等的,而且我们期望不同的时间序列上每个相同时间点的物理含义是一致的,表示的是同一个目标(值)。但是实际上这种情况过于理想,学过自动控制原理的都会知道,所有的信息传递都可以视为一个系统对一个信号的响应,而系统的响应是可能存在时滞的,而且在整个过程中,扭曲和伸缩都是存在的。比如下图就是某污染物注入水体后各水质指标的响应曲线,我们把整个水体和不同的水质指标检测仪器的组合视为不同的系统,最后得到的时间序列视为系统的响应,可以看到在时间轴上存在时间的异位,伸缩和扭曲。

这时候我们需要调整我们的距离度量函数来解决这一问题,最常见的就是DTW算法。DTW算法的实质就是基于动态规划,借助局部最佳化的思想来寻找一条路径,使得两个时间序列之间的累计距离最小。算法通过贪心的方式去寻找一条两条时间序列之间距离最短的匹配路径,由于算法是贪心的,所以肯定不是最优解,同时也不能保证之前提到的距离的对称性,所以在使用的时候如果需要对称性,需要进一步处理。此外,算法有个重要的限制就是允许最大的时间偏移,如下图虚线所示,我们找到的路径不会超出虚线所示范围。
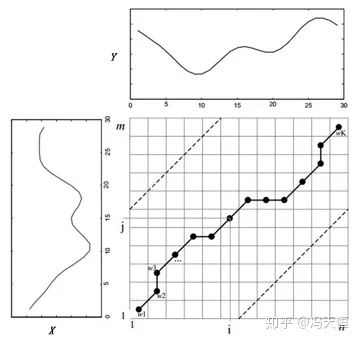
由于我们在实际输入时肯定已经给定了时间序列的起点和终点,所以这只解决了伸缩和扭曲的问题,还存在异位的问题。而我们拿到的时间序列通常是利用滑窗从一个完整的时间序列上截取下来的,在实际应用中,我们可以利用不仅仅去对比两个滑窗下的时间序列的距离,而可以允许滑窗的错位对比,从而解决时间序列的异位问题。
以上,我们其实已经解决了距离(或是相似度)度量上的大部分问题,这样我们可以进入到下一个环节,也就是轨迹聚类的环节。
轨迹聚类
如上所述,假设我们已经定义了一个合理的时间序列表示方式和距离(相似度)的计算方式,那么我们就走到了最后一步,也就是轨迹聚类这里。走到这一步,其实工作量已经不大了,最简单的就是去选择一种聚类方法,直接计算得到结果,比如说kmeans。
有很多工作就采用这种简单的方式,文中通过多项式(三次)去拟合了不同的时间序列,然后直接用FCM(fuzzy c-means)对拟合的多项式系数去做了聚类,然后得到了如下的结果。

看上去结果还行,当然也有些问题,比如说第一行第二列和第四行第一列两个子图,似乎曲线和中心曲线没有那么一致。导致这一现象的原因有很多,比如说聚类选取的中心点的数量,这个是制约聚类效果的一大瓶颈。我们可以先选取稍微较多一些的中心,然后再做合并,千万不要认为我们需要几类就聚成几类。比如说我们需要做异常分类,那就是分两类,但是我们要把时间序列聚成两类,这个难度是很大的,还不如先聚成四五类,只要最后人工找出异常的一类即可。我们也可以选择不同的聚类算法来解决这一问题,比如选取层次聚类或者DBSCAN等算法,最大的差异就是不用指定类别数,其他的优劣对比就在这里就不一一展开了。
当然,我觉得这里影响聚类效果的是对距离的定义,文中直接把拟合的多项式系数的欧式距离作为时间序列间的距离,优点是降维,而缺点是多项式中不同的系数对曲线的拟合作用不一样,也就是对实际距离的影响不一样。文中直接粗暴的定义损失了一定的信息,导致了最后效果的劣势。当然文章也算是证明了一个伟大的思路,也就是降维并不一定是要具备具体物理含义的,只要是表征了时间序列,就能收到一定的效果。
聚类的最大好处在于我们在做异常预测的时候不需要异常样本来训练,我们只需要对比一个时间序列是否属于其中一类或者对任何一类的隶属度都较低来判断是否异常,这在很多没有或是较少异常样本的场景下是具有很大优势的,毕竟时间序列的异常样本获取难度较大。
但是如前所述,聚类本身存在一定的缺陷,而且聚类算法并不多,也就五大类(基于中心,网格,密度等),在拥有一定量的异常样本时,分类算法的优势就体现出来了。因为时间序列的信息量很大,聚类算法最多依赖于时间序列间距离这一信息来进行计算,这样会带来大量的信息损失,而且在距离的定义上也存在大量的约束。而分类算法不同,可以接受线性或是非线性的信息,而且可以不需要距离的定义,那其实只要做一件事情,就是尽可能提取时间序列包含的信息。比如上例中,如果我们有异常和正常的划分,我们完全可以将多项式系数作为自变量来进行分类模型的训练,分类模型能够根据数据凸显出不同系数的重要性,而非在聚类中的等权关系。而且,分类问题也可以避免维度灾难的问题。因为没有距离的定义,这个也不复存在,我们可以随意地进行表征或是维度变换以满足算法所需。
以上是关于如何用Python对人员轨迹聚类的主要内容,如果未能解决你的问题,请参考以下文章
看完这篇文章,包你懂得如何用Python实现聚类算法的层次算法!