3.TF-IDF算法介绍应用NLTK实现TF-IDF算法Sklearn实现TF-IDF算法算法的不足算法改进
Posted to.to
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.TF-IDF算法介绍应用NLTK实现TF-IDF算法Sklearn实现TF-IDF算法算法的不足算法改进相关的知识,希望对你有一定的参考价值。
3.TF-IDF
3.1.TF-IDF算法介绍
3.2.TF-IDF应用
3.3.NLTK实现TF-IDF算法
3.4.Sklearn实现TF-IDF算法
3.5.Jieba实现TF-IDF算法
3.6.TF-IDF算法的不足
3.7.TF-IDF算法改进—TF-IWF算法
3.TF-IDF
以下转自:https://blog.csdn.net/asialee_bird/article/details/81486700
3.1.TF-IDF算法介绍
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其它文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词除以文章总词数),以防止它偏向长的文件。

其中ni,j是该词在文件dj中出现的次数,分母则是文件dj中所有词汇出现的次数总和;
(2)IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率(IDF):某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
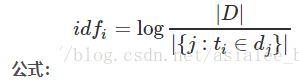
其中,|D|是语料库中的文件总和。 |{j:ti∈dj}|表示包含词语ti的文件数目(即ni,j≠0的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
即:
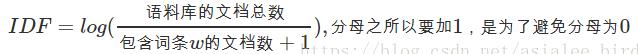
(3)TF-IDF实际上是:TF*IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
公式:
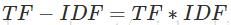
注:TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
3.2.TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
3.3.NLTK实现TF-IDF算法
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
# 首先,构建语料库corpus
sents = ['this is sentence one', 'this is sentence two', 'this is sentence three']
sents = [word_tokenize(sent) for sent in sents] # 对每个句子进行分词
print(sents) # 输出分词后的结果
'''
输出结果:
[['this', 'is', 'sentence', 'one'], ['this', 'is', 'sentence', 'two'], ['this', 'is', 'sentence', 'three']]
'''
corpus = TextCollection(sents) # 构建语料库
print(corpus) # 输出分词后的结果
'''
输出结果:
<Text: this is sentence one this is sentence two...>
'''
# 计算语料库中"one"的tf值
tf = corpus.tf('one', corpus) # 结果为: 1/12
print(tf)
'''
输出结果:
0.08333333333333333
'''
# 计算语料库中"one"的idf值
idf = corpus.idf('one') # log(3/1)
print(idf)
"""
输出结果:
1.0986122886681098
"""
# 计算语料库中"one"的tf-idf值
tf_idf = corpus.tf_idf('one', corpus)
print(tf_idf)
'''
输出结果:
0.0915510240556758
'''
3.4.Sklearn实现TF-IDF算法
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train = ['TF-IDF 主要 思想 是', '算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test = ['原始 文本 进行 标记', '主要 思想']
# 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer(max_features=10)
# 该类会统计每个词语的tf-idf权值
tf_idf_transformer = TfidfTransformer()
# 将文本转为词频矩阵并计算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
print("--------------------------tf_idf-------------------------------")
print(tf_idf)
print('--------------------------x_train_weight-----------------------')
# 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
x_train_weight = tf_idf.toarray()
print(x_train_weight)
print("---------------------------------------------------------------")
# 对测试集进行tf-idf权重计算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
print('输出x_train文本向量:')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
输出结果:
--------------------------tf_idf-------------------------------
(0, 2) 0.7071067811865476
(0, 0) 0.7071067811865476
(1, 9) 0.3349067026613031
(1, 7) 0.4403620672313486
(1, 6) 0.4403620672313486
(1, 5) 0.4403620672313486
(1, 3) 0.4403620672313486
(1, 1) 0.3349067026613031
(2, 9) 0.22769009319862868
(2, 8) 0.29938511033757165
(2, 4) 0.8981553310127149
(2, 1) 0.22769009319862868
--------------------------x_train_weight-----------------------
[[0.70710678 0. 0.70710678 0. 0. 0.
0. 0. 0. 0. ]
[0. 0.3349067 0. 0.44036207 0. 0.44036207
0.44036207 0.44036207 0. 0.3349067 ]
[0. 0.22769009 0. 0. 0.89815533 0.
0. 0. 0.29938511 0.22769009]]
---------------------------------------------------------------
输出x_train文本向量:
[[0.70710678 0. 0.70710678 0. 0. 0.
0. 0. 0. 0. ]
[0. 0.3349067 0. 0.44036207 0. 0.44036207
0.44036207 0.44036207 0. 0.3349067 ]
[0. 0.22769009 0. 0. 0.89815533 0.
0. 0. 0.29938511 0.22769009]]
输出x_test文本向量:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]]
3.5.Jieba实现TF-IDF算法
import jieba.analyse
text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
keywords=jieba.analyse.extract_tags(text, topK=20, withWeight=False, allowPOS=())
print(keywords)
注:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本。
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight为是否一并返回关键词权重值,默认值为False
- allowPOS仅包括指定词性的词,默认为空,即不筛选
3.6.TF-IDF算法的不足
TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词, 十分有效地反映单词的重要程度和特征词的分布情 况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
TF-IDF算法实现简单快速,但是仍有许多不足之处:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
3.7.TF-IDF算法改进—TF-IWF算法
https://pdf.hanspub.org//CSA20130100000_81882762.pdf
以上是关于3.TF-IDF算法介绍应用NLTK实现TF-IDF算法Sklearn实现TF-IDF算法算法的不足算法改进的主要内容,如果未能解决你的问题,请参考以下文章