TF-IDF算法简介
TF-IDF概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
原理
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
TF表示分词在文档中出现的频率,算法是:(该分词在该文档出现的次数)/(该文档分词的总数),这个值越大表示这个词越重要,即权重就越大,TF (例如:一篇文档分词后,总共有500个分词,而分词”Hello”出现的次数是20次,则TF值是: tf =20/500=0.04)。
IDF是是一个词语普遍重要性的度量。一个文档库中,一个分词出现在的文档数越少越能和其它文档区别开来。算法是: log(总文档数/(出现该分词的文档数+1)) 。如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词),IDF (例如:一个文档库中总共有10000篇文档, 99篇文档中出现过“Hello”分词,则idf是: Idf = log(10000/(99+1)) =2)。
TF-IDF=词频(TF)*逆文档频率(IDF),TF-IDF与一个词在文档中的出现次数成正比,与整个语料库中包含该词的文档数成反比(例如:一篇文档分词后,总共有500个分词,而分词”Hello”出现的次数是20次,则TF值是: tf =20/500=0.04;一个文档库中总共有10000篇文档, 99篇文档中出现过“Hello”分词,则idf是: Idf = log(10000/(99+1)) =2;TF-IDF= 0.04*2=0.08)。
用途
自动提取关键词,计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。信息检索时,对于每个文档,都可以分别计算一组搜索词("TF-IDF"、"MapReduce")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
优缺点
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不 多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的(一种解决方法是,对全文的第一段和 每一段的第一句话,给予较大的权重。)。
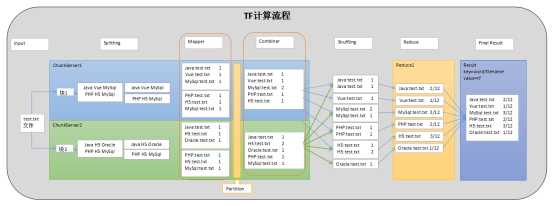
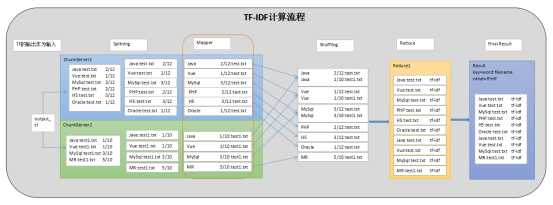
MapReduce实现TF-IDF的思路
实现思路
通过两个MapReduce实现,第一个MapReduce计算出TF,第二个MapReduce计算IDF和TF-IDF并写入到输出文件中
第一个MR
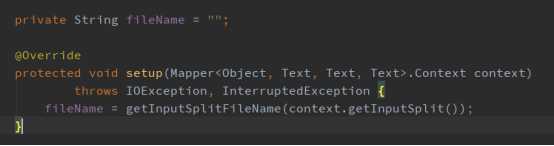
第一步:在setup阶段通过FileSplit获取文件名,代码实现如下:
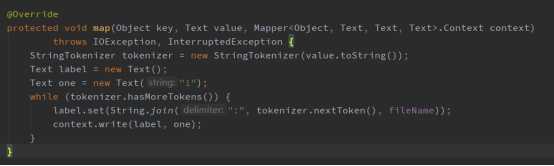
第二步:在map阶段利用StringTokenizer分词器,根据空白字符(“ ”,“\\t”,“\\n”)分割字符串,存储为<key=word:filename, value=1>的键值对,代码实现如下:
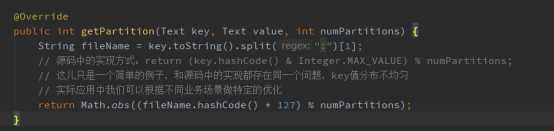
第三步:自定义Partition,一个文件指定给一个Reduce处理(这种处理问题很容易导致负载不均,实际开发中根据不同的业务需求,可以做相应的调整。例如:我们统计文档是全英文的可以根据首字母来指定不同的reduce,然后把计算总次数单独给一个reduce来计算) ,代码实现如下:
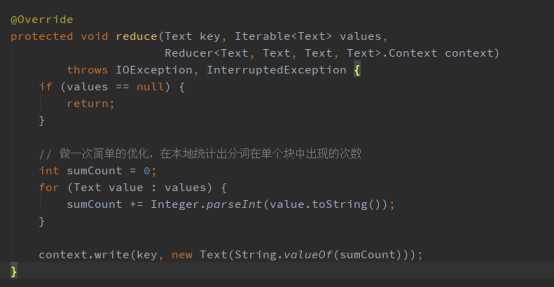
第四步:重写Combiner,因为Combiner在本地执行,所以Combiner可以做一定的优化,减少IO开销,在Combiner阶段对单个分词在文件块中出现的次数(这儿只能统计单个分词在单个文件块中出现的次数,不是在文章中的出现次数)做一次统计,存储为<key=word:filename, value=单个分词在文件块中出现的次数>的键值对,代码实现如下:
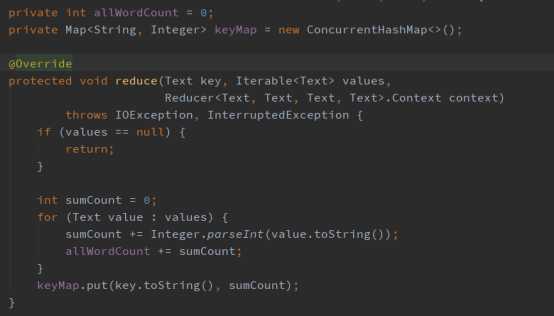
第五步:1、Reduce阶段,首先重写reduce方法,统计该文档分词的总数和该分词在该文档出现的次数,代码实现如下:
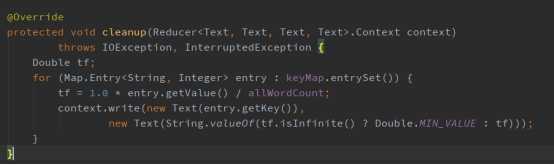
2、最后重写cleanup方法,计算该分词的TF值,写入到tf的临时输出文件中,存储类型为<key=word:filename, value=tf>(这儿需要对tf做一个判断,因为分母一定大于或等于分子,有可能会出现无穷小) ,代码实现如下:
第二个MR
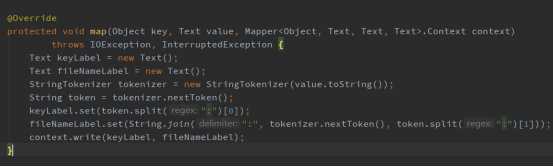
第一步:Map阶段利用StringTokenizer分词器,根据空白字符(“ ”,“\\t”,“\\n”)分割字符串,存储为<key=word, value=tf:filename>的键值对,代码实现如下:
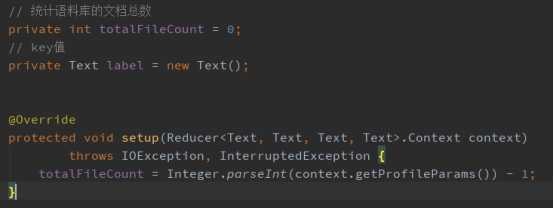
第二步:1、首先重写setup方法,统计语料库的文档总数,代码实现如下:
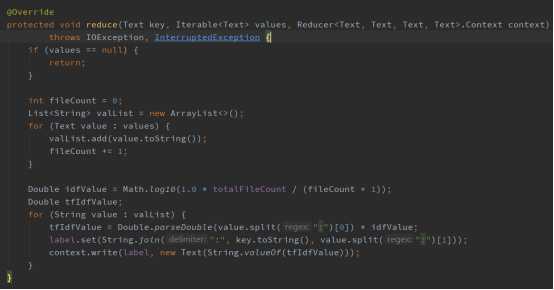
2、然后统计包含分词的文档数,计算分词的IDF值,最后计算TF-IDF值,并写入到输出文件中,代码实现如下:
MR的高级定制
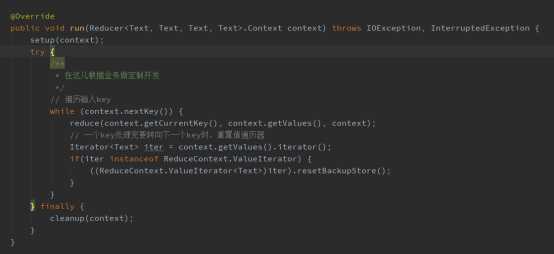
一、打开源码,我们可以看到,MapReduce的执行过程都是由run方法来控制,根据不同的业务可以重写Mapper的run方法,定制任务的执行过程,代码实现如下:
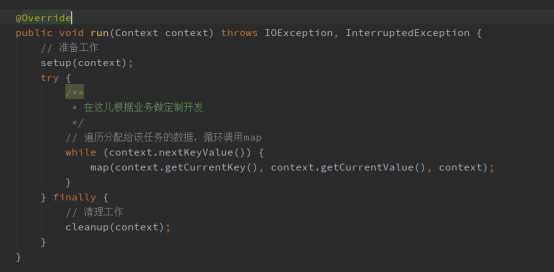
二、重写Reducer的run方法,根据特定业务需求控制任务的执行过程,代码实现如下: