Proximal Algorithms 1 介绍
Posted mtandhj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Proximal Algorithms 1 介绍相关的知识,希望对你有一定的参考价值。
定义
令\(f: \mathrmR^n \rightarrow \mathrmR \cup \+ \infty \\)为闭的凸函数,即其上镜图:
\[
\mathbfepi f = \ (x, t) \in \mathrmR^n \times \mathrmR| f(x) \le t\
\]
为非空闭的凸集,定义域:
\[
\mathbfdom f = \x \in \mathrmR^n| f(x) < + \infty\
\]
近端算子(是这么翻译的?)proximal operator \(\mathbfprox_f: \mathrmR^n \rightarrow \mathrmR^n\)定义为:
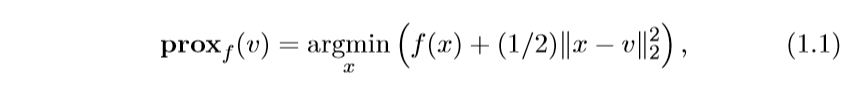
我们常常会对添加一个比例系数\(\lambda\),而关心\(\lambda f\)的近端算子:
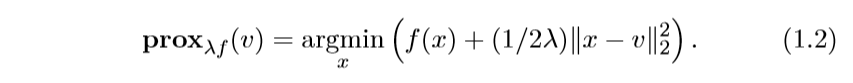
注:等式右边乘以一个常数\(\lambda\)便是\(\lambda f\)的形式,所以是等价的。
解释
图形解释
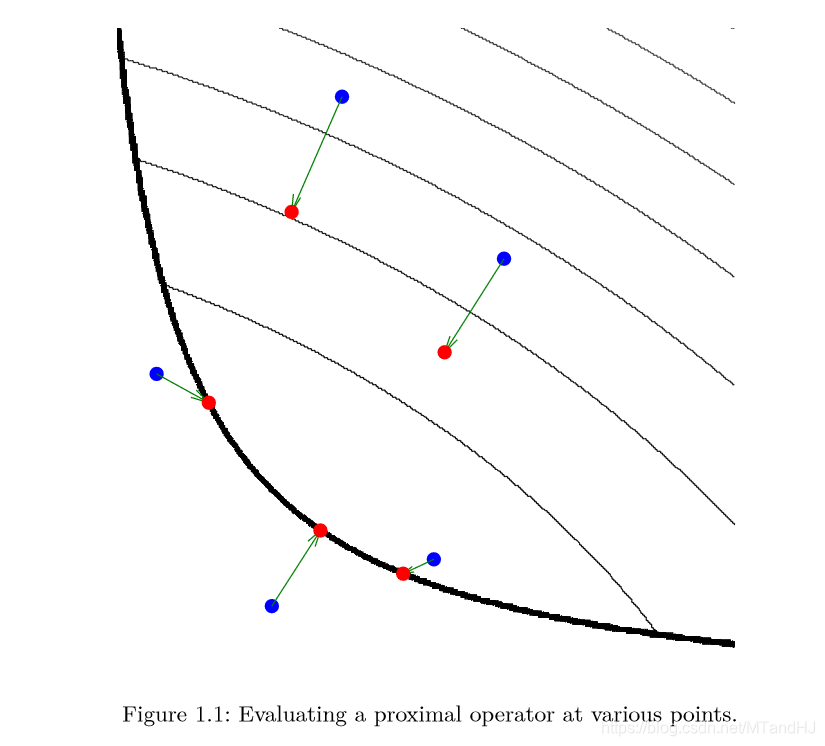
注:图中的细黑线是函数\(f\)的等值线,而粗黑线表示定义域的边界。在蓝色的点处估计其\(\mathbfprox_f\)得到红色的点。
可以发现,\(\mathbfprox_f(v)\)实际上是对点\(v\)附近的一个估计。
梯度解释
假设\(\lambda\)很小,且\(f\)可微,那么,容易知道\(f(x) + \frac12\lambda\|x-v\|_2^2\)取得极值(实际上也是最值)的条件是:
\[
\nabla f(x) +\fracx-v\lambda=0 \Rightarrow x=v-\lambda \nabla f(x) \approx v-\lambda \nabla f(v)
\]
可以看到,\(\mathbfprox_f(v)\)近似为在\(v\)点的梯度下降,而\(\lambda\)为步长。
一个简单的例子
有一个问题,就是,如果我们的目的是最小化\(f(x)\),那么利用\(\mathbfprox_f\)会不会太愚蠢了,既然我们能求解\(\mathbfprox_f\),那么直接最小化\(f(x)\)应该也不是难事吧。这个问题留到以后再讨论吧,我也不知道能否找到一个恰当的例子来反驳。
当\(f\)是一个示性函数:
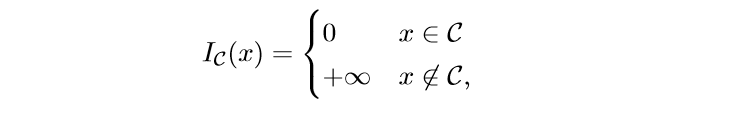
其中\(\mathcalC\)为非空凸集,我们来看看这个时候的\(\mathbfprox_f(v)\):
\[
\mathbfprox_\lambda f(v)= \mathrmargmin_x \: I_\mathcalC(x) + \frac12 \lambda\|x-v\|_2^2
\]
首先,我们可以确定\(x \in \mathcalC\), 否则结果为无穷,所以,问题可以转化为一个Euclid范数下投影问题:
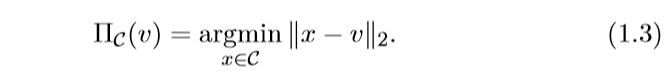
所以一个问题是,如果\(\mathbfprox_f\)的尾项不用\(\ell_2\)范数,用别的范数会变成什么样?
以上是关于Proximal Algorithms 1 介绍的主要内容,如果未能解决你的问题,请参考以下文章
Proximal Algorithms 2 Properties
近端策略优化算法(Proximal Policy Optimization Algorithms, PPO)
PPO姿态控制基于强化学习(Proximal Policy Optimization)PPO训练的无人机姿态控制simulink仿真
Proximal Gradient Descent-近端梯度下降