Attention-based Model
Posted lee-yl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Attention-based Model相关的知识,希望对你有一定的参考价值。
一、Attention与其他模型
1、LSTM、RNN的缺点:输入的Memory长度不能太长,否则参数会很多。
采用attention可以输入长Memory,参数不会变多。
2、Sequence to Sequence Learning : 输入和输出的句子长度可以不一样,常用来做句子翻译。
比如:将中文的4个字”机器学习“翻译成英文的2个单词”machine learning“。
二、Attention的研究发展
1、在RNN模型上使用了attention机制来进行图像分类【google mind团队的这篇论文《Recurrent Models of Visual Attention》】
2、将attention应用到机器翻译中,第一次用在NLP中【Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》】
1、Recurrent Models of Visual Attention
注意力集中到图像的特定部分。而且人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。下图是这篇论文的核心模型示意图。
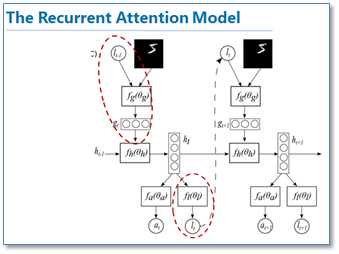
该模型是在传统的RNN上加入了attention机制(即红圈圈出来的部分),通过attention去学习一幅图像要处理的部分,每次当前状态,都会根据前一个状态学习得到的要关注的位置l和当前输入的图像,去处理注意力部分像素,而不是图像的全部像素。这样的好处就是更少的像素需要处理,减少了任务的复杂度。可以看到图像中应用attention和人类的注意力机制是很类似的,接下来我们看看在NLP中使用的attention。
2、Attention-based RNN in NLP
2.1 Neural Machine Translation by Jointly Learning to Align and Translate
最大的特点还在于它可以可视化对齐,并且在长句的处理上更有优势。
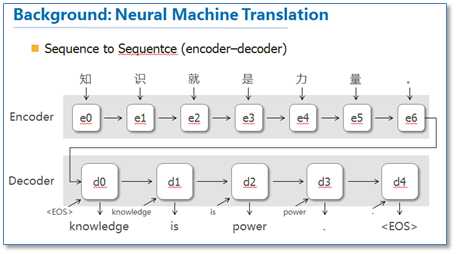
这篇论文算是在NLP中第一个使用attention机制的工作。他们把attention机制用到了神经网络机器翻译(NMT)上,NMT其实就是一个典型的sequence to sequence模型,也就是一个encoder to decoder模型,传统的NMT使用两个RNN,一个RNN对源语言进行编码,将源语言编码到一个固定维度的中间向量,然后在使用一个RNN进行解码翻译到目标语言,传统的模型如下图:
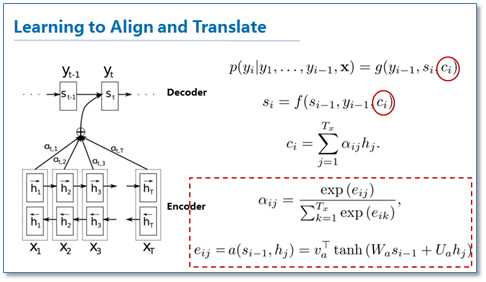
这篇论文提出了基于attention机制的NMT,模型大致如下图:
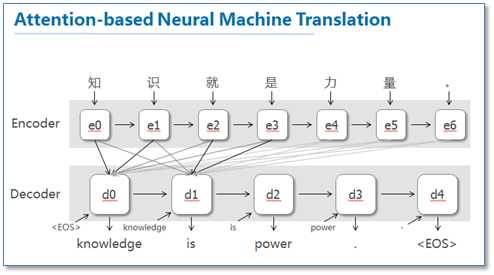
图中我并没有把解码器中的所有连线画玩,只画了前两个词,后面的词其实都一样。可以看到基于attention的NMT在传统的基础上,它把源语言端的每个词学到的表达(传统的只有最后一个词后学到的表达)和当前要预测翻译的词联系了起来,这样的联系就是通过他们设计的attention进行的,在模型训练好后,根据attention矩阵,我们就可以得到源语言和目标语言的对齐矩阵了。具体论文的attention设计部分如下:
2.2 Effective Approaches to Attention-based Neural Machine Translation [2]
这篇论文是继上一篇论文后,一篇很具代表性的论文,他们的工作告诉了大家attention在RNN中可以如何进行扩展,这篇论文对后续各种基于attention的模型在NLP应用起到了很大的促进作用。在论文中他们提出了两种attention机制,一种是全局(global)机制,一种是局部(local)机制。
首先我们来看看global机制的attention,其实这和上一篇论文提出的attention的思路是一样的,它都是对源语言对所有词进行处理,不同的是在计算attention矩阵值的时候,他提出了几种简单的扩展版本。
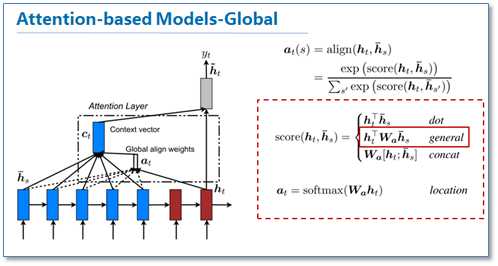

在他们最后的实验中general的计算方法效果是最好的。
我们再来看一下他们提出的local版本。主要思路是为了减少attention计算时的耗费,作者在计算attention时并不是去考虑源语言端的所有词,而是根据一个预测函数,先预测当前解码时要对齐的源语言端的位置Pt,然后通过上下文窗口,仅考虑窗口内的词。
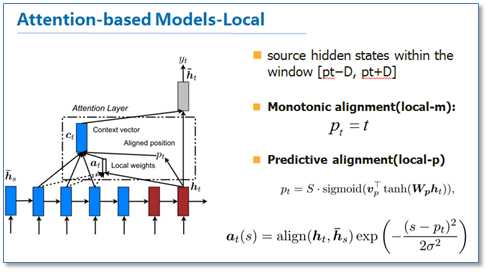
里面给出了两种预测方法,local-m和local-p,再计算最后的attention矩阵时,在原来的基础上去乘了一个pt位置相关的高斯分布。作者的实验结果是局部的比全局的attention效果好。
这篇论文最大的贡献我觉得是首先告诉了我们可以如何扩展attention的计算方式,还有就是局部的attention方法。
3、Attention-based CNN in NLP
随后基于Attention的RNN模型开始在NLP中广泛应用,不仅仅是序列到序列模型,各种分类问题都可以使用这样的模型。那么在深度学习中与RNN同样流行的卷积神经网络CNN是否也可以使用attention机制呢?《ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs》 [13]这篇论文就提出了3中在CNN中使用attention的方法,是attention在CNN中较早的探索性工作。
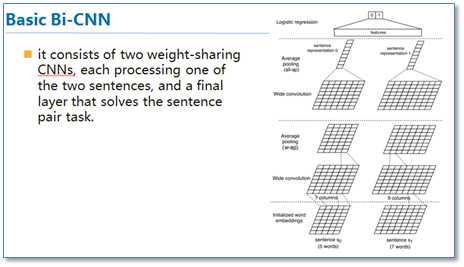
传统的CNN在构建句对模型时如上图,通过每个单通道处理一个句子,然后学习句子表达,最后一起输入到分类器中。这样的模型在输入分类器前句对间是没有相互联系的,作者们就想通过设计attention机制将不同cnn通道的句对联系起来。
第一种方法ABCNN0-1是在卷积前进行attention,通过attention矩阵计算出相应句对的attention feature map,然后连同原来的feature map一起输入到卷积层。具体的计算方法如下。
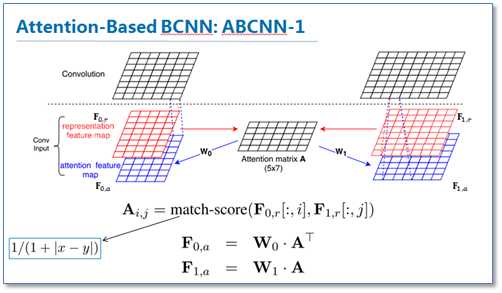
第二种方法ABCNN-2是在池化时进行attention,通过attention对卷积后的表达重新加权,然后再进行池化,原理如下图。
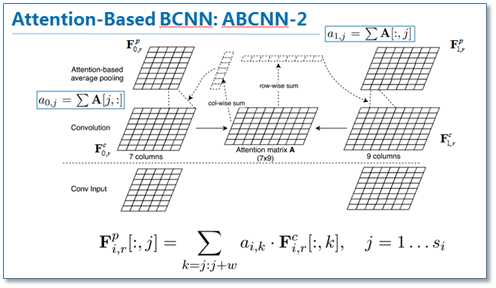
第三种就是把前两种方法一起用到CNN中,如下图
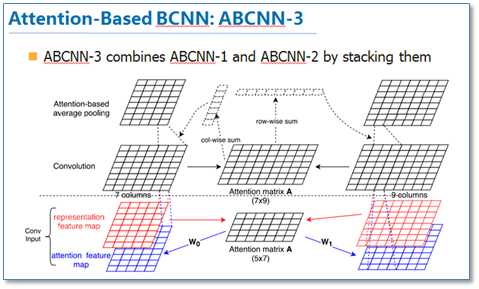
这篇论文提供了我们在CNN中使用attention的思路。现在也有不少使用基于attention的CNN工作,并取得了不错的效果。
三、Attention的本质
1、解释
Google给出注意力机制的定义为,给定一个Query和一系列的key-value对一起映射出一个输出。
- 将Query与key进行相似性度量(类似于上述的权重wij)
- 将求得的相似性度量进行缩放标准化
- 将权重与value进行加权
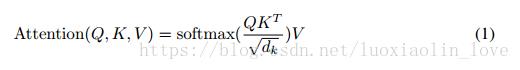
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,如下图。
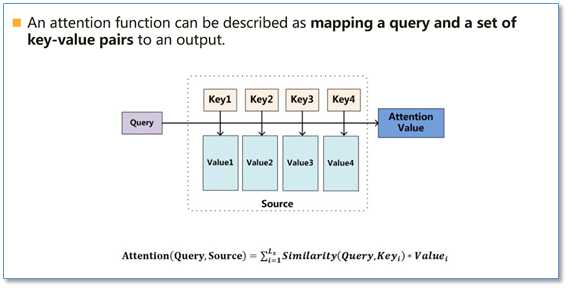
在计算attention时主要分为三步,
第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
第二步一般是使用一个softmax函数对这些权重进行归一化;
最后将权重和相应的键值value进行加权求和得到最后的attention。目前在NLP研究中,key和value常常都是同一个,即key=value。

1、在NLP中:
理解成自动加权,它可以把两个你想要联系起来的不同模块,通过加权的形式进行联系。目前主流的计算公式有以下几种:

通过设计一个函数将目标模块mt和源模块ms联系起来,然后通过一个soft函数将其归一化得到概率分布。
目前Attention在NLP中已经有广泛的应用。它有一个很大的优点就是可以可视化attention矩阵来告诉大家神经网络在进行任务时关注了哪些部分。
2、在query推荐中,
可以理解成相似度。
2 论文
2.1Attention is all you need[1]
接下来我将介绍《Attention is all you need》这篇论文。这篇论文是google机器翻译团队在2017年6月放在arXiv上,最后发表在2017年nips上,到目前为止google学术显示引用量为119,可见也是受到了大家广泛关注和应用。这篇论文主要亮点在于1)不同于以往主流机器翻译使用基于RNN的seq2seq模型框架,该论文用attention机制代替了RNN搭建了整个模型框架。2)提出了多头注意力(Multi-headed attention)机制方法,在编码器和解码器中大量的使用了多头自注意力机制(Multi-headed self-attention)。3)在WMT2014语料中的英德和英法任务上取得了先进结果,并且训练速度比主流模型更快。
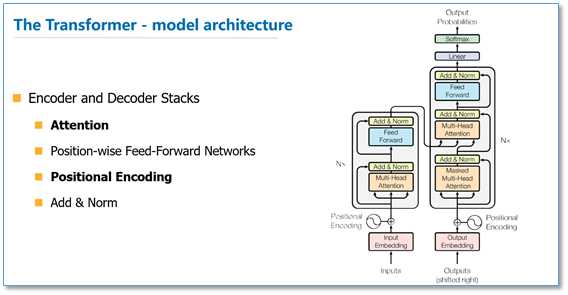
该论文模型的整体结构如下图,还是由编码器和解码器组成,在编码器的一个网络块中,由一个多头attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。类似于编码器,只是解码器的一个网络块中多了一个多头attention层。为了更好的优化深度网络,整个网络使用了残差连接和对层进行了规范化(Add&Norm)。
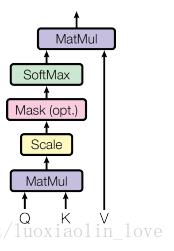
下面我们重点关注一下这篇论文中的attention。在介绍多头attention之前,我们先看一下论文中提到的放缩点积attention(scaled dot-Product attention)。对比我在前面背景知识里提到的attention的一般形式,其实scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大。

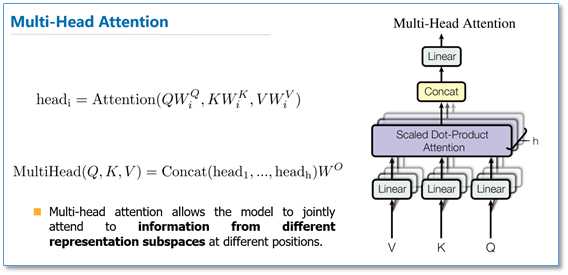
多头attention(Multi-head attention)结构如下图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息,后面还会根据attention可视化来验证。
那么在整个模型中,是如何使用attention的呢?如下图,首先在编码器到解码器的地方使用了多头attention进行连接,K,V,Q分别是编码器的层输出(这里K=V)和解码器中都头attention的输入。其实就和主流的机器翻译模型中的attention一样,利用解码器和编码器attention来进行翻译对齐。然后在编码器和解码器中都使用了多头自注意力self-attention来学习文本的表示。Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
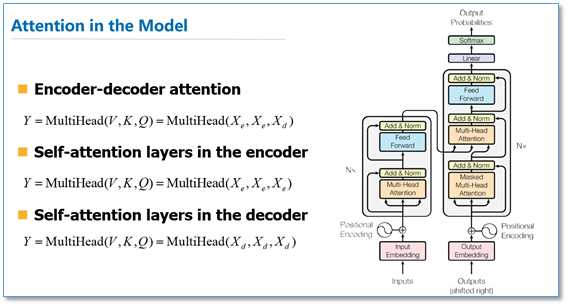
【对自己画重点:】为什么要用self-attention?
对于使用自注意力机制的原因,论文中提到主要从三个方面考虑
(每一层的复杂度,是否可以并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。
当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention。在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。
在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。可以捕获长距离依赖关系。

2.2、self-attention in NLP
2.2.1 Deep Semantic Role Labeling with Self-Attention[8]
这篇论文来自AAAI2018,厦门大学Tan等人的工作。他们将self-attention应用到了语义角色标注任务(SRL)上,并取得了先进的结果。这篇论文中,作者将SRL作为一个序列标注问题,使用BIO标签进行标注。然后提出使用深度注意力网络(Deep Attentional Neural Network)进行标注,网络结构如下。在每一个网络块中,有一个RNN/CNN/FNN子层和一个self-attention子层组成。最后直接利用softmax当成标签分类进行序列标注。
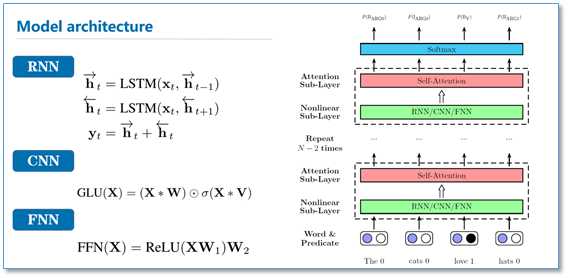
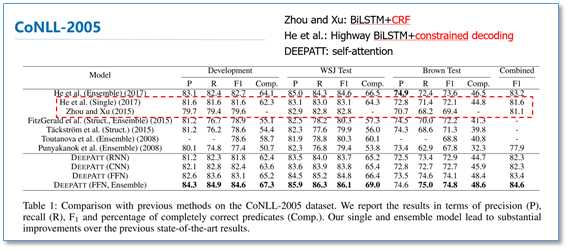
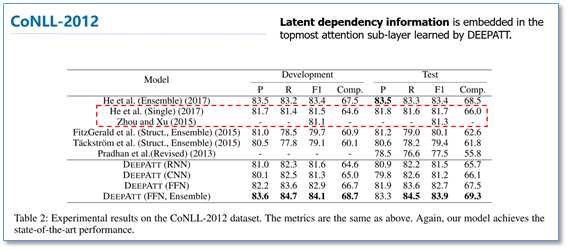
该模型在CoNLL-2005和CoNll-2012的SRL数据集上都取得了先进结果。我们知道序列标注问题中,标签之间是有依赖关系的,比如标签I,应该是出现在标签B之后,而不应该出现在O之后。目前主流的序列标注模型是BiLSTM-CRF模型,利用CRF进行全局标签优化。在对比实验中,He et al和Zhou and Xu的模型分别使用了CRF和constrained decoding来处理这个问题。可以看到本论文仅使用self-attention,作者认为在模型的顶层的attention层能够学习到标签潜在的依赖信息。
3.2 Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction[7]
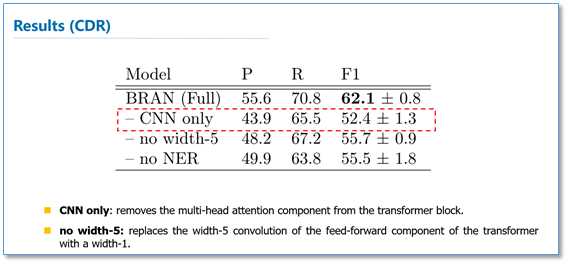
这篇论文是Andrew McCallum团队应用self-attention在生物医学关系抽取任务上的一个工作,应该是已经被NAACL2018接收。这篇论文作者提出了一个文档级别的生物关系抽取模型,里面做了不少工作,感兴趣的读者可以更深入阅读原文。我们这里只简单提一下他们self-attention的应用部分。论文模型的整体结构如下图,他们也是使用google提出包含self-attention的transformer来对输入文本进行表示学习,和原始的transformer略有不同在于他们使用了窗口大小为5的CNN代替了原始FNN。

我们关注一下attention这部分的实验结果。他们在生物医学药物致病数据集上(Chemical Disease Relations,CDR)取得了先进结果。去掉self-attention这层以后可以看到结果大幅度下降,而且使用窗口大小为5的CNN比原始的FNN在这个数据集上有更突出的表现。
四、self-attention
1、是什么?
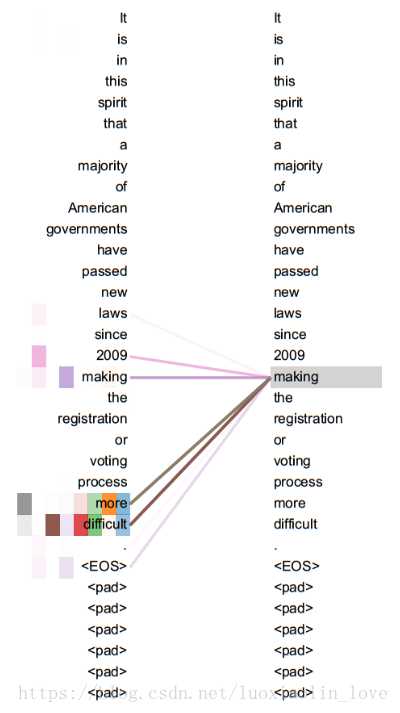
attention机制通常用在encode与decode之间,但是self-attention则是输入序列与输出序列相同,寻找序列内部元素的关系即 K=V=Q。l例如《Attention Is All You Need》在编码器中使用self-attention,利用上一步的input值计算当前该位置input的值。如下图:
2、为什么?
尽管attention机制由来已久,但真正令其声名大噪的是google 2017年的这篇名为《attention is all your need》的论文。
让我们从一个简单的例子看起:
假设我们想用机器翻译的手段将下面这句话翻译成中文:
“The animal didn’t cross the street because it was too tired”
当机器读到“it”时,“it”代表“animal”还是“street”呢?对于人类来讲,这是一个极其简单的问题,但是对于机器或者说算法来讲却十分不容易。
self-Attention则是处理此类问题的一个解决方案,也是目前看起来一个比较好的方案。当模型处理到“it”时,self-Attention可以将“it”和“animal‘联系到一起。
3、怎么做?
通俗地讲,当模型处理一句话中某一个位置的单词时,self-Attention允许它看一看这句话中其他位置的单词,看是否能够找到能够一些线索,有助于更好地表示(或者说编码)这个单词。
如果你对RNN比较熟悉的话,我们不妨做一个比较。RNN通过保存一个隐藏态,将前面词的信息编码后依次往后面传递,达到利用前面词的信息来编码当前词的目的。而self-Attention仿佛有个上帝之眼,纵观全局,看看上下文中每个词对当前词的贡献。

下面来看下具体是怎么实现的。
首先,来看下怎样使用向量来计算self-attention,紧接着看如何用矩阵来计算self-attention。
使用向量
如下图所示,一般而言,输入的句子进入模型的第一步是对单词进行embedding,每个单词对应一个embedding。对于每个embedding,我们创建三个向量,Query、Key和Value向量。我们如何来创建三个向量呢?如图,我们假设embedding的维度为4,我们希望得到一个维度为3的Query、Key和Value向量,只需将每个embedding乘上一个维度为4*3的矩阵即可。这些矩阵就是训练过程中要学习的。

那么,Query、Key和Value向量代表什么呢?他们在attention的计算中发挥了什么样的作用呢?
我们用一个例子来说明:
首先要明确一点,self-attention其实是在计算每个单词对当前单词的贡献,也就是对每个单词对当前单词的贡献进行打分score。假设我们现在要计算下图中所有单词对第一个单词”Thinking”的打分。那么分分数如何计算呢,只需要将该单词的Query向量和待打分单词的Key向量做点乘即可。比如,第一个单词对第一个单词的分数为q1× k1,第二个单词对第一个单词的分数为q1×k2。

我们现在得到了两个单词对第一个单词的打分(分数是个数字了),然后将其进行softmax归一化。需要注意的是,在BERT模型中,作者在softmax之前将分数除以了Key的维度的平方根(据说可以保持梯度稳定)。softmax得到的是每个单词在Thinking这个单词上的贡献的权重。显然,当前单词对其自身的贡献肯定是最大的。
接着就是Value向量登场的地方了。将上面的分数分别和Value向量相乘,注意这里是对应位置相乘。

最后,将相乘的结果求和,这就得到了self-attention层对当前位置单词的输出。对每个单词进行如上操作,就能得到整个句子的attention输出了。在实际使用过程中,一般采用矩阵计算使整个过程更加高效。

在开始矩阵计算之前,先回顾总结一下上面的步骤:
-
- 创建Query、Key、Value向量
- 计算每个单词在当前单词的分数
- 将分数归一化后与Value相乘
- 求和
值得注意的是,上面阐述的过程实际上是Attention机制的计算流程,对于self-Attention,Query=Key=Value。
Matrix Calculation of Self-Attention
其实矩阵计算就是将上面的向量放在一起,同时参与计算。
首先,将embedding向量pack成一个矩阵X。假设我们有一句话有长度为10,embedding维度为4,那么X的维度为(10 × 4).

假设我们设定Q、K、V的维度为3.第二步我们构造一个维度为(4×3)的权值矩阵。将其与X做矩阵乘法,得到一个10×3的矩阵,这就能得到Query了。依样画葫芦,同样可以得到Key和Value。

最后,将Query和Key相乘,得到打分,然后经过softmax,接着乘上V的到最终的输出。

4、self-attention的计算

4.1、《Self-Attention with Relative Position Representations》
参考:
https://www.cnblogs.com/robert-dlut/p/5952032.html
https://www.cnblogs.com/robert-dlut/p/8638283.html
https://blog.csdn.net/jasonzhoujx/article/details/83386627
https://state-of-art.top/2019/01/06/BERT系列(一)Self-attention/
以上是关于Attention-based Model的主要内容,如果未能解决你的问题,请参考以下文章
Learning from Interpretable Analysis:Attention-Based Knowledge Tracing
Learning from Interpretable Analysis:Attention-Based Knowledge Tracing
论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)
论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)
文本分类Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
文本分类Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification