论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)相关的知识,希望对你有一定的参考价值。
文章目录
摘要

在本文中,我们提出了一种将外部知识整合到循环神经网络 (RNN) 中的新方法。我们建议将词典特征集成到基于 RNN 的体系结构的自我注意机制中。这种对注意力分布的调节形式,加强了手头任务中最显着的词的贡献。我们介绍了三种方法,即注意力串联、基于特征的门控和仿射变换。在六个基准数据集上的实验表明了我们方法的有效性。基于注意特征的门控在任务之间产生一致的性能改进。我们的方法作为基于 RNN 的模型的简单附加模块实现,具有最小的计算开销,并且可以适应任何深度神经架构。
简单来说,文章尝试了三种方法,将外部只是成功融入并且提升了效果。
文章贡献

我们的贡献如下:
(1)我们提出了一种将外部知识整合到基于 RNN 的架构的替代方法。
(2)我们提出了我们提出的方法始终优于强基线的经验结果。
(3)我们报告了在两个数据集中的SOTA表现。我们公开了我们的源代码。
Proposed Model
Word Embedding Layer

词嵌入层。单词 w1, w2, …, wT 的输入序列被投影到低维向量空间 RW ,其中 W 是嵌入层的大小,T 是句子中单词的数量。我们使用预训练的词嵌入来初始化嵌入层的权重。
LSTM Layer

Self-Attention Layer

External Knowledge

在这项工作中,我们利用人类专家现有的语言和情感知识来增强我们的模型。具体来说,我们利用包含心理语言学、情感和情感注释的词典。我们通过连接表 1 中所示词典中的单词注释,为词汇表中的每个单词构建一个特征向量 c(wi)。对于缺失的单词,我们在 c(wi) 的相应维度中附加零。
Conditional Attention Mechanism

我们扩展了标准的自注意力机制(等式 1、2),以便根据每个单词的先验词汇信息来调节给定句子的注意力分布。为此,我们使用单词注释 hi 以及每个单词的词典特征 c(wi) 作为自我注意层的输入。因此,我们替换方程式中的 f(hi)。 1 与 f(hi, c(wi))。具体来说,我们探索了三种调节方法,如图 1 所示。
我们将条件函数称为 fi(.),将权重矩阵称为 Wi,将偏差称为 bi,其中 i 是每种方法的指示性字母。我们在第 5 节(表 3)中展示了我们的结果,我们将三种调节方法表示为“conc。 ”、“门”和“仿射”。
这里值得注意,因为需要融入外部知识,因此上面提到的注意力机制的输入不再是 f(hi)而是f(hi, c(wi)),因为还需要外部知识的输入。
接下来就是重点,文章介绍的三种方法:
Attentional Concatenation

在这种方法中,如图 1(a) 所示,我们学习了每个单词注释 hi 与其词典特征 c(wi) 的串联函数。直觉是,通过为 hi 添加额外的维度,学习到的表征更具辨别力。具体来说: fc(hi, c(wi)) = tanh(Wc[hi k c(wi)] + bc) (3) 其中 k 表示级联操作,Wc, bc 是可学习的参数。
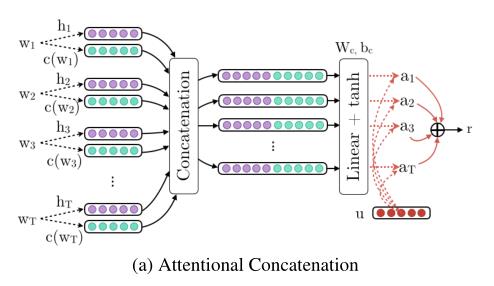
简单来说就是在词的embedding和词典信息的embedding进行concat作为注意力机制的输入。
Attentional Feature-based Gating

第二种方法,如图1(b)所示,学习应用于每个单词注释hi的特征掩码。具体而言,具有S形激活函数的门机制从每个值介于0和1之间的c(wi)生成掩码向量(图中的黑点和白点)。1(b))。直觉上,这种门控机制根据词汇信息选择hi的显著维度(即特征)。形式上:fg(hi,c(wi))=σ(Wgc(wi)+bg) hi(4)其中
hi(4)其中 表示元素乘法,Wg、bg是可学习的参数。
表示元素乘法,Wg、bg是可学习的参数。

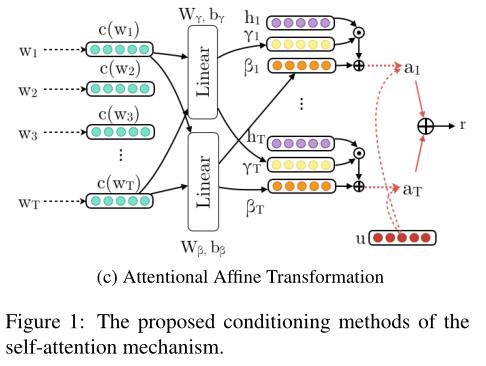
Attentional Affine Transformation

第三种方法,如图1(c)所示,采用了Perez等人(2017)的工作,并将特征仿射变换应用于隐藏状态的潜在空间。具体而言,我们使用词典特征c(wi),以便有条件地生成相应的缩放γ(·)和移位β(·)向量。具体而言:fa(hi,c(wi))=γ(c(wi))?hi+β(c(wi))(5)γ(x)=Wγx+bγ,β(x)=Wβx+bβ(6),其中Wγ、Wβ、bγ、bβ是可学习的参数。
实验结果

最后看得出gate+emb.conc的效果是最好的。
以上是关于论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)的主要内容,如果未能解决你的问题,请参考以下文章