Learning from Interpretable Analysis:Attention-Based Knowledge Tracing
Posted sereasuesue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Learning from Interpretable Analysis:Attention-Based Knowledge Tracing相关的知识,希望对你有一定的参考价值。
一篇短文
Learning from Interpretable Analysis: Attention-Based Knowledge Tracing | SpringerLink
International Conference on Artificial Intelligence in Education
摘要
知识追踪是个性化教育中一个公认的问题,也是一项重要的任务。近年来,人们提出了许多现有的工作来处理知识跟踪任务,特别是基于递归神经网络的方法,如深度知识跟踪(DKT)。然而,DKT在预测输出中存在振动问题。在本文中,为了更好地理解DKT的问题,我们使用了一个名为有限状态自动机(FSA)的数学计算模型,它可以根据外部输入从一种状态转换为另一种状态,以解释接收输入时DKT的隐藏状态转换。我们发现这两个问题的根本原因是DKT不能在FSA的帮助下处理长序列输入。因此,我们提出了一种有效的基于注意力的模型,它可以通过直接捕获输入的每个项目之间的关系来解决上述问题,而不管输入序列的长度如何。实验结果表明,在几个著名语料库上,我们提出的模型可以显著优于最新的方法。
引言
DKT在预测输出中仍然存在振动[9]。这是不合理的,因为学生的知识状态预计会随着时间逐渐过渡,但不会在掌握和尚未掌握之间交替。为了找出问题的根本原因,我们使用FSA作为一种可解释的结构,可以从DKT中学习到,因为FSA在处理顺序数据时具有更易于解释的内部机制[3]。我们参考[3]为DKT构建了一个FSA,以解释每个输入序列上的元素如何影响DKT的隐藏状态。当FSA接受输入项时,表示该项对模型的最终预测输出有积极影响,反之亦然。我们在图1中显示了每个输入序列的接受率。我们可以从图1中得出结论,输入序列越长,拒绝项目的比例越高,预测精度越低。这种现象与[7]中的描述一致,后者指出LSTM[2]在输入序列过长时具有捕获特征的弱点。因此,我们提出了一个模型来解决KT中的长序列输入问题,实验表明,我们提出的模型在解决上述问题方面是有效的。
贡献:是第一批采用FSA对KT任务进行深入分析的团队。通过使用FSA解释学习状态的变化,我们可以更好地理解现有基于RNN的方法的问题。其次,根据可解释性分析,我们提出了一个多头部注意模型来处理KT中的长序列输入问题。最后,我们在真实数据集上对我们的模型进行了评估,结果表明我们的模型改进了最新的基线。
模型
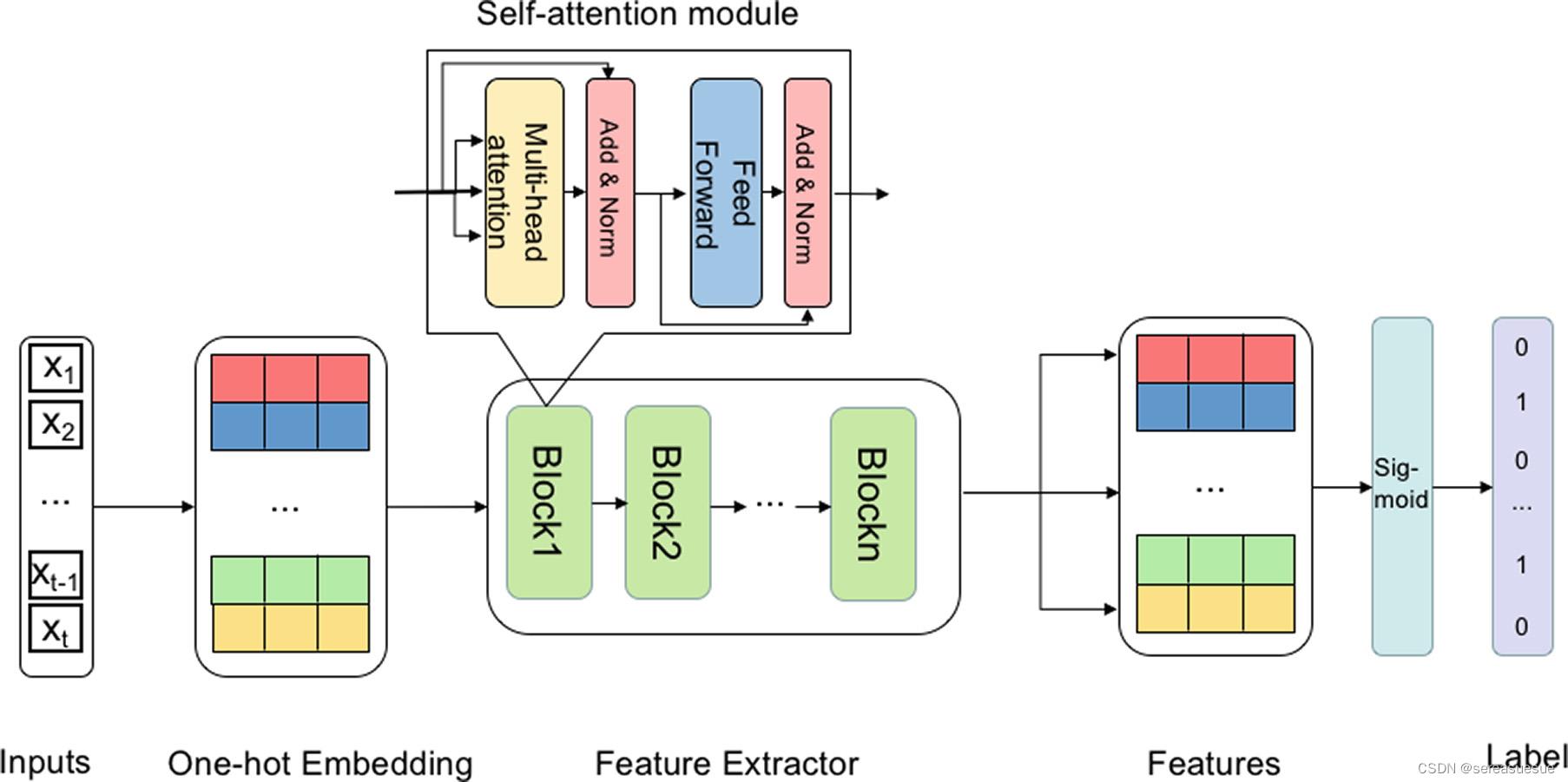
模型结构
- 嵌入层:包含问题和相应答案的元组首先被投影到实值向量中,即一个热嵌入。
- 特征提取:之后,向量被送入特征提取程序,其目的是捕获输入之间潜在的依赖关系。特征提取程序的主要组件由N个相同的块组成。每个块有两个子层。第一个是多头自我注意机制[8],是提取器的关键元件,第二个是完全连接的前馈网络[8]。自我注意通过使用标度点积注意计算输入序列中每个项目的相似性来实现全局关系的提取[8]。在这里,注意力被计算了h次,这使得模型能够在不同的代表子空间中学习相关信息,并使其成为所谓的多头模型。
- 预测和损失:在预测阶段,只有注意力子层的最顶层输出被带到Sigmoid函数中,以做出最终决策。预测和优化过程与[9]相同,我们在此不再赘述。
实验
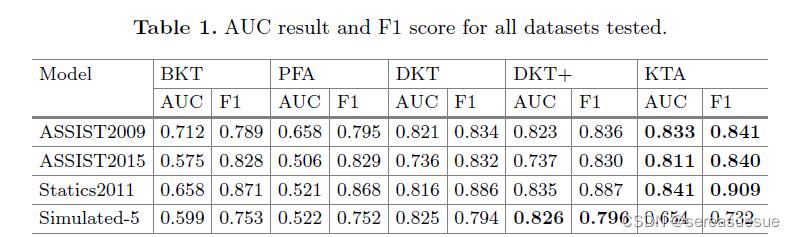

思考
作者并没有花很多篇幅说明可解释性,只是说通过FSA对KT任务进行深入分析,发现了RNN的问题(长期依赖性),然后提出了个引入注意力的模型KTA(并没有什么新的东西)
以上是关于Learning from Interpretable Analysis:Attention-Based Knowledge Tracing的主要内容,如果未能解决你的问题,请参考以下文章