文本分类Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification相关的知识,希望对你有一定的参考价值。
·摘要:
从模型的角度,本文作者将RNN(Bi-LSTM)和attention mechanism结合使用,提出AttRNN模型,应用到了NLP的关系抽取(Relation Classification)中,也可应用到文本分类任务中,提高精度。
·参考文献:
[1] Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification 论文链接:https://aclanthology.org/P16-2034.pdf
[1] 摘要
· 重要的信息可能出现在句子的任何位置。为了解决这些问题,提出基于注意力机制的双向长短期记忆网络(AttBiLSTM)来捕获句子中最重要的语义信息。
简单的理解就是,给句子向量乘上一个权重向量,按权重向量重新计算向量值。
[2] 模型
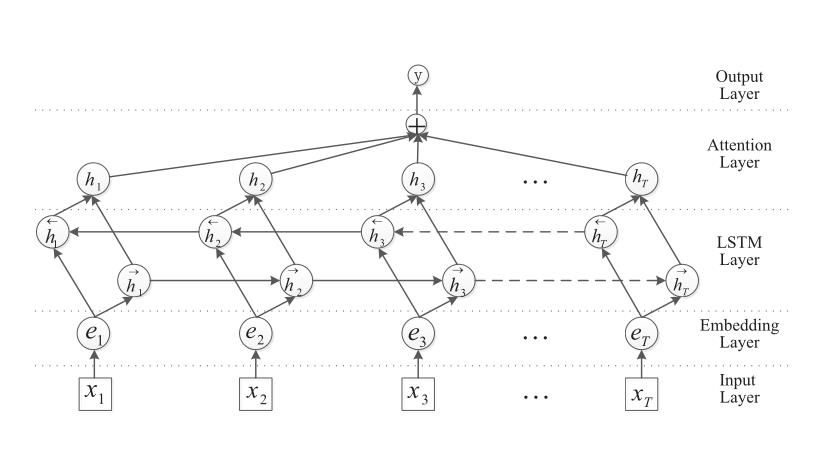
模型一共有6层,输入层、嵌入层、双向LSTM层、注意力机制层、全连接层、输出层。
双向LSTM的输出为2倍(正反两个反向)的[h1, h2,…hT]。普通RNN模型,就会把此处双向LSTM的输出作为全连接层的输入进行分类,在本文中还需经过注意力层。
注意力机制层的作用是找到一个句子中各个词的相关系数,然后把原来句子向量乘上这个系数。计算公式为:
M
=
t
a
n
h
(
H
)
α
=
s
o
f
t
m
a
x
(
w
T
M
)
r
=
∑
(
H
α
T
)
h
∗
=
t
a
n
h
(
r
)
\\beginaligned M = tanh(H)\\\\ \\alpha = softmax(w^TM)\\\\ r = \\sum (H \\alpha^T)\\\\ h^* = tanh(r)\\\\ \\endaligned
M=tanh(H)α=softmax(wTM)r=∑(HαT)h∗=tanh(r)
H
H
H是Bi-LSTM层的输出;
H
H
H经过激活函数后变成M;
w
w
w是一个可优化的一维张量数组相等,维度与
H
H
H的最后一个维度,即Bi-LSTM层的hidden_size * 2;
α
\\alpha
α即为注意力权重系数,表示一个句子中的词语之间的相关性;
r
r
r则为Bi-LSTM输出
H
H
H经过加权求和后的结果;最后通过
t
a
n
h
tanh
tanh激活函数生成表征向量
h
∗
=
t
a
n
h
(
r
)
h^*=tanh(r)
h∗=tanh(r);
关于注意力机制,可以参考下面两篇文章:
https://zhuanlan.zhihu.com/p/65304158
https://zhuanlan.zhihu.com/p/393940472
[3] 代码复现
贴出基础模型:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
# self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2))
self.w = nn.Parameter(torch.zeros(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x):
x, _ = x
emb = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * num_direction]=[128, 32, 256]
M = self.tanh1(H) # [128, 32, 256]
# M = torch.tanh(torch.matmul(H, self.u))
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # [128, 32, 1]
out = H * alpha # [128, 32, 256]
out = torch.sum(out, 1) # [128, 256]
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out
实验结果(baseline):
| 数据集 | RNN | RCNN | AttRNN |
|---|---|---|---|
| THUCNews | 90.73% | 91.21% | 90.62% |
[4] 获取本项目的源代码
如果需要本项目的源代码,请扫描关注我的公众号,回复“论文源码”。

以上是关于文本分类Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification的主要内容,如果未能解决你的问题,请参考以下文章
Learning from Interpretable Analysis:Attention-Based Knowledge Tracing
Learning from Interpretable Analysis:Attention-Based Knowledge Tracing
Learning from Interpretable Analysis:Attention-Based Knowledge Tracing
论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)
论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)