Bayesian statistics
Posted yuliured
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Bayesian statistics相关的知识,希望对你有一定的参考价值。
目录
1Bayesian model selection(贝叶斯模型选择)
使用多项式阶数过高会导致过拟合,过低会导致欠拟合。正则化参数过小会导致过拟合,过大会导致欠拟合。我们面临一系列不同复杂度的模型,如何选择,就是模型选择问题。
一个方法是使用交叉验证(cross-validation)来估计所有备选模型的错误,挑选最好的一个模型。However, this requires fitting each model K times, where K is the number of CV folds.
一个高效的方法是计算模型的后验:

我们很容易计算最大后验概率模型:
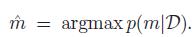
这就叫贝叶斯模型选择。
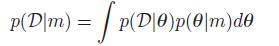
这个quantity叫marginal likelihood,integrated likelihood,或者模型m的evidence。
1.1奥卡姆剃刀(Occam’s razor)原理
One might think that using p(D|m) to select models would always favor the model with the most parameters. This is true if we use
p(D|θm^)
to select models, where
θ^m
is the MLE or MAP estimate of the parameters for model m, because models with more parameters will fit the data better, and hence achieve higher likelihood. However, if we integrate out the parameters,rather than maximizing them, we are automatically protected from overfitting: models with more parameters do not necessarily have higher marginal likelihood. This is called the Bayesian Occam’s razor effect, named after the principle known as Occam’s razor, which says one should pick the simplest model that adequately explains the data.
【在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。】
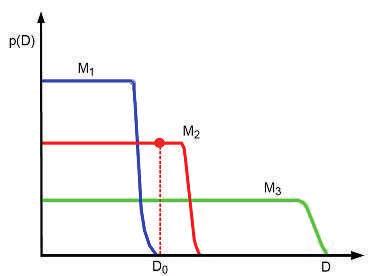
Bayesian Occam’s razor解释图:D0为真实的观测数据,模型M1最简单,M3最复杂。
因为简单的模型只能产生简单的数据,复杂的模型参数多,不仅可以产生简单的数据,同时可以产生复杂的数据。当给定的一个数据集后,简单的模型由于表现能力差,使用边缘似然函数比较小,同时由于过于复杂的模型可以产生更多的复杂数据,那么它产生该特定数据的概率就会相对变小,因此它的边缘似然函数同样不大。只有复杂度适中的模型的边缘似然函数最大。
【假设有K个模型
M1,...,Mk
,我们想知道模型
Mk
产生数据D的可能性的大小,即产生数据D的概率是多少,并以此作为模型优劣的标准。这个过程叫做模型选择或模型评估。】
2Computing the marginal likelihood (evidence)
贝叶斯推断中边际似然函数涉及到维数较高的复杂积分的计算, 因而精确地计算边际似然函数往往有困难.经常会选择一种近似方法来估计边际似然函数。
2-1 BIC approximation to log marginal likelihood
一个简单流行的近似是贝叶斯信息标准(Bayesian information criterion or BIC),它的形式为:

其中, 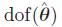 是模型的自由度,
是模型的自由度,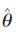 是模型的MLE.
是模型的MLE.
一个非常相似的表达是Akaike information criterion or AIC,定义为
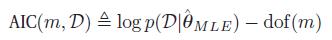
这是来源于频率学框架的,不能用来做marginal likelihood的近似推断。
BIC对参数增加的惩罚力度大于户AIC,这使得AIC选择的是更复杂的模型,但是这能导致更好的预测准确性。
2-2贝叶斯因子
Suppose our prior on models is uniform ,那么模型的选择相当于选择有更高边际似然的模型。
,那么模型的选择相当于选择有更高边际似然的模型。
考虑模型M0,M1,定义贝叶斯因子为两个的比:
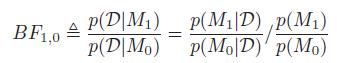

Jeffreys解释贝叶斯因子的标准
3先验
在Bayes 分析中,进行统计推断与决策所依赖的后验分布是以先验分布为基础。因此,如何获得先验分布是Bayes 方法的最关键问题。
3-1 确定无信息先验分布的Jeffreys原则
Jeffreys先验(Jeffreys’ Prior) Jeffreys提出的选取先验分布的原则是一种不变原理,采用Fisher信息阵的平方根作为θ的无信息先验分布。
Jeffreys 提出了一种基于信息函数的无信息先验分布选择方法,即Jeffreys 原则,较好地解决了Bayes假设中的一个矛盾,即若对参数θ 选用均匀分布,则其函数g(θ) 往往不是均匀分布。同时,该原则给出了寻求先验分布的具体办法。
Jeffreys原则:
按照原则决定参数θ 的先验分布为π(θ) ,对于θ 的函数g(θ) 作为参数,按照同一原则决定的η = g(θ) 的先验分布是πg(η) ,则应有关系式:
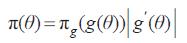
若选取的π(θ) 符合上式,则用θ 或θ 的函数g(θ) 导出的先验分布总是一致的。
困难之处在于如何找出满足上式的π(θ) 。Jeffreys 巧妙的利用了Fisher信息阵的性质,找到了符合要求的π(θ) 。
引理: 设g(θ) 是θ 的函数,η = g(θ) 与θ 具有相同的维数k ,则有:
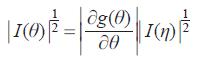
其中,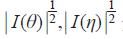 分别表示
分别表示 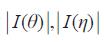 的行列式的平方根,|∂g(θ)/∂θ|是((∂g(θ))/∂θ)行列式绝对值。
的行列式的平方根,|∂g(θ)/∂θ|是((∂g(θ))/∂θ)行列式绝对值。
由此引理与Jeffreys原则,可取:π(θ)∝|I(θ)|^1/2
该式对标量参数和矢量参数都适用。
推导:
p(φ) is non-informative,θ = h(φ) for some function h, should also be non-informative
let us pick: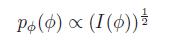
where I(φ) is the Fisher information:
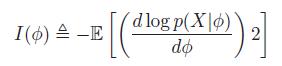
有
平方并取x的期望,得到
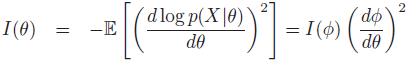
即
so we find the transformed prior is:
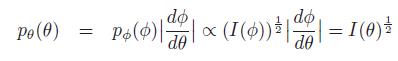
So pθ(θ) and pφ(φ) are the same.
3-2共轭先验(Conjugate Priors)
共轭先验是指先验分布和后验分布来自同一个分布族的情况,就是说先验和后验有相同的分布形式(当然,参数是不同的)。这些共轭先验是结合似然的形式推导出来的。
Conjugate prior的意义:
使得贝叶斯推理更加方便,比如在Sequential Bayesian inference(连续贝叶斯推理)中,得到一个observation之后,可以算出一个posterior(后验)。由于选取的是 Conjugate prior共轭先验,因此后验和原来先验的形式一样,可以把该后验当做新的先验,用于下一次observation,然后继续迭代。
4Hierarchical Bayes
计算后验p(θ|D)的一个关键是带超参数η的p(θ|η),如果我们不知道η,可以使用前面的无信息先验,更多的贝叶斯方法是通过先验的先验!
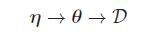
这就是层级贝叶斯模型。
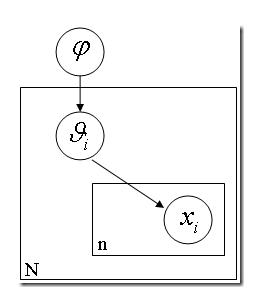
如果你手头有 N 枚硬币,它们是同一个工厂铸出来的,你把每一枚硬币掷出一个结果,然后基于这 N 个结果对这 N 个硬币的 θ (出现正面的比例)进行推理。然而我们又知道每个硬币的 p(θ) 是有一个先验概率的,也许是一个 beta 分布。也就是说,每个硬币的实际投掷结果 Xi 服从以 θ 为中心的正态分布,而 θ 又服从另一个以 Ψ 为中心的 beta 分布。层层因果关系就体现出来了。进而 Ψ 还可能依赖于因果链上更上层的因素,以此类推。
5Empirical Bayes
在分层贝叶斯模型中,我们需要在多层级潜在变量上计算后验。例如,两个层级的模型:

一种经验贝叶斯分析就是用边际分布来估计η,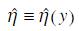 ,比如说可以用
,比如说可以用
边际极大似然估计,然后以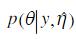 作为后验分布的估计。
作为后验分布的估计。
6Bayesian decision theory
选择未知的状态/参数/标签,y ∈ Y,然后产生一个观测x ∈ X。然后我们做出决策,选择一个行为a,从行为空间A中选择,损失为L(y, a)。
例如,使用误分类损失L(y, a) = I(y ≠ a),或者平方损失
L(y,a)=(y−a)2
.
我们的目标是产生一个决策过程或者策略,δ : X → A,表示每一个可能的输入最佳的行为action。最优化,意味着最小化期望损失:
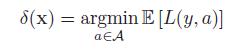
使用贝叶斯方法的决策理论,最优化行为,用于观测x,行为a,最小化后验期望损失:
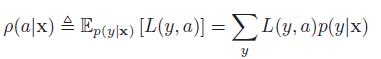
因此,贝叶斯估计,也称为贝叶斯决策规则(Bayes decision rule)为:

基于最小错误率的贝叶斯决策
以后验概率值的大小做判据

基于最小风险的贝叶斯决策
判决依据为对该观测值X条件下各个状态后验概率求加权和的方法

λ(i)j 表示观测样本X实属类别j被判为i所造成的损失。
6-1拒绝选择
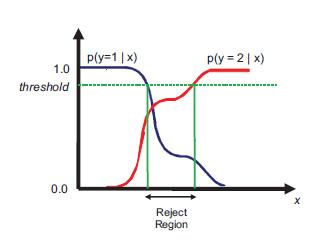
如上图,分类错误来自于在输入中不同类别在相同空间区域上有重叠,这时候可以采取拒绝分类的方法,即reject option。当样本落在这个区域的时候,就有疑惑的结果留待人类专家来判定。
引入一个阈值threshold,将最大后验概率小于或者等于该阈值的输入样本X拒绝预测。
设a = C + 1相当于选择reject action,a ∈ 1, … , C相当于选择一个类
定义损失函数为:

λr is the cost of the reject action, and λs is the cost of a substitution error
6-2The false positive vs false negative tradeoff
二元决策问题中两类错误:
1)False Positive 假阳性也被称为误报或者虚警(把“不是”说成“是”),估计量
y^
=1,真实为y=0
2)False Negative 假阴性也被称为漏报(把“是”说成“不是”),估计量
y^
=0,真实为y=1
损失矩阵:

LFN是false negative的损失,LFP是false positive的损失,则这两个actions的后验期望损失为:
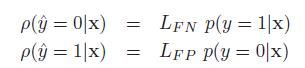
6-2-1完美的ROC曲线
假设类标签数据集 ,决策规则δ(x)=l(f(X)>τ,τ是阈值,对于每个给定的τ可以使用决策规则来计算true positives, false positives, true negatives, 和false negatives各自的数量。
,决策规则δ(x)=l(f(X)>τ,τ是阈值,对于每个给定的τ可以使用决策规则来计算true positives, false positives, true negatives, 和false negatives各自的数量。

confusion matrix,N+ 是真实数量的阳性, (N_+ ) ̂ 是被声称的阳性, N- 真实数量的阴性,(N_- ) ̂是被声称的阴性。
TPR(true positive rate)
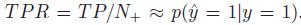
FPR(false alarm rate)

不单单使用一个固定的阈值τ,而是一系列的τ值时,绘制出将FPR定义为x轴,TPR定义为y轴的曲线,称为ROC曲线:

两个假设的分类系统ROC曲线。A比B效果好。
左下角:(FPR = 0, TPR = 0),设置τ=1,所有的类别被分为negative
右上角:(FPR = 1, TPR = 1),设置τ=0,所有的类别被分位positive
【最好的预测方式是一个在左上角的点,在ROC空间坐标轴(0,1)点,这个代表着100%灵敏(没有假阴性)和100%特异(没有假阳性)。而(0,1)点被称为“完美分类器”。一个完全随机的预测会得到一条从左下到右上对角线(也叫无识别率线)上的一个点,这条线上的任一点对应的准确度(ACC)都是50%。】
ROC曲线下面的区域称为AUC,AUC分数越高越好,最大为1.
6-2-2Precision Recall曲线(查准率-查全率曲线)
PR曲线在分类、检索等领域有着广泛的使用,来表现分类/检索的性能。
精度:
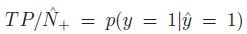 ,反映了被分类器判定的正例中真正的正例样本的比重
,反映了被分类器判定的正例中真正的正例样本的比重
召回率:
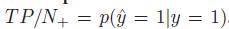 ,反映了被正确判定的正例占总的正例的比重
,反映了被正确判定的正例占总的正例的比重
【如果是分类器的话,通过调整分类阈值,可以得到不同的P-R值,从而可以得到一条曲线(纵坐标为P,横坐标为R)。通常随着分类阈值从大到小变化(大于阈值认为P),查准率减小,查全率增加。比较两个分类器好坏时,显然是查得又准又全的比较好,也就是的PR曲线越往坐标(1,1)的位置靠近越好。】

precision-recall曲线。A比B效果好。
6-2-3F-scores
在检索系统中,希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。一个综合评价指标定义为F score 或者F1 score:
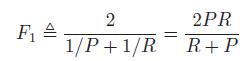
参考链接:
贝叶斯统计基础
以上是关于Bayesian statistics的主要内容,如果未能解决你的问题,请参考以下文章
Stanford机器学习笔记-3.Bayesian statistics and Regularization
Bayesian Statistics for Genetics | 贝叶斯与遗传学
论文导读Learning Bayesian Networks: The Combination of Knowledge and Statistical Data