Stanford机器学习笔记-3.Bayesian statistics and Regularization
Posted PusHpoP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Stanford机器学习笔记-3.Bayesian statistics and Regularization相关的知识,希望对你有一定的参考价值。
3. Bayesian statistics and Regularization
Content
3. Bayesian statistics and Regularization.
3.1 Underfitting and overfitting.
3.2 Bayesian statistics and regularization.
3.3 Optimize Cost function by regularization.
3.3.1 Regularized linear regression.
3.3.2 Regularized logistic regression.
3.4 Advanced optimization.
key words: underfitting, overfitting, regularization, bayesian statistic
3.1 Underfitting and overfitting
前面已经学习了线性回归模型与logistic回归模型,它们在很多方面都有应用,例如利用线性回归模型(也可以是多项式)进行房价预测,logistic回归模型垃圾邮件分类等。但是,在应用过程中可能存在一些问题,例如过拟合(overfitting),与之相对的就是欠拟合(underfitting)。
所谓过拟合,简单的说就是我们设计的学习模型对训练样本的学习能力太强大了,导致对训练样本拟合的太好。此时可能同学就有疑问:拟合得很好不是好事吗,为什么还是问题呢?注意,我们设计学习模型的目的并不是对训练样本拟合就ok了,我们训练模型是为了它能够对不在训练集中的数据有较好的预测。训练集是我们所研究的全体数据集的一个子集,我们认为它应该有像其他属于全体数据集的特征,但同时,它也通常有它自己独有的特征。所以,如果学习模型的学习能力太强,学到了训练集独有的特征,对训练样本拟合得太好,也就是过拟合,那么它可能对不属于训练集但属于我们研究的数据集的数据预测得不好,也就是泛化能力(generalization)下降。而欠拟合,就是对训练样本拟合得太差,连我们所研究的数据集都具有的特征都没有学到。从数学上分析,欠拟合将会导致很大的偏差(bias),而过拟合将会导致很大的方差(variance)。
下面通过图3-1线性回归中预测房价的例子和图3-2Logistic回归中0-1分类的例子直观感受欠拟合和过拟合。

图3-1 线性回归中的欠拟合与过拟合

图3-2 Logistic回归处理0-1分类问题中的欠拟合与过拟合
通常来说,欠拟合是比较好解决的,例如在线性回归和Logistic回归中,我们可能通过增加新的特征或者用较高次数的多项式。但过拟合是比较难以控制的,因为它非常的矛盾: 我们认为选出的训练集可以在很大程度上代表所研究的全体数据集,所以我们希望模型能够较好的拟合,但是,我们又知道训练集不可避免的有无法泛化的特征。所以或多或少我们的学习模型都会学到训练集所独有的特征。虽说如此,但还是有一些措施来减少过拟合的风险。
- 减少特征的数量
- 尽量选择我们认为具有一般化的特征,除去可能只有训练集才有的特征。(人工的)
- 采用模型选择算法(Model selection algorithm)
- 正则化(Regularization)
3.2 Bayesian statistics and regularization
正则化的基本思想是保留所有的特征量,但通过减少参数θ来避免某个特征量影响过大。
下面从Bayesian statistics(贝叶斯统计)学派来理解正则化。
在之前,我们通过利用极大似然法(maximum likelihood: ML)对参数θ进行估计,进而得到代价函数,认为θ的取值应使得似然函数最大,也就使得代价函数最小,即有
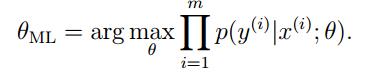
所以极大似然估计中认为θ是我们不知道的参数,而不是一个变量,这就是频率学派(frequentist statistics)的观点。这种观点认为,θ不是随机的(自然也就没有随机分布这一说法),它是常量,理应等于某些值。所以我们的工作是用比如极大似然这样统计学的方法来估计它。
但是贝叶斯学派认为,θ是未知的随机变量,所以在我们对训练集进行训练之前,θ就可能服从某种分布p(θ),我们称之为先验概率(prior distribution)。对于一个训练集 ![]() ,如果我们要对新的进行预测,我们可以通过贝叶斯公式算出θ的后验概率(posterior distribution),即:
,如果我们要对新的进行预测,我们可以通过贝叶斯公式算出θ的后验概率(posterior distribution),即:

上面就是完整的贝叶斯预测,但是事实上很难计算出θ的后验概率,因为(1)式要求对θ进行积分,而θ往往是高维的,所以很难实现。
因此在实际应用中我们常常是近似θ的后验概率。一种常用的近似方式就是一个点的估计来代替(2)式。The MAP(maximum a posteriori)估计如下:

我们发现(3)式相较于极大似然估计,只是后面乘了θ的先验概率。
在实际应用中,通常假设![]() (当然也有其他的假设方式)。在实际中,The Bayesian MAP estimate比极大似然估计更好的减少过拟合。例如,用Bayesian Logistic 回归算法可以用来处理特征数远大于训练样本数文本分类问题。
(当然也有其他的假设方式)。在实际中,The Bayesian MAP estimate比极大似然估计更好的减少过拟合。例如,用Bayesian Logistic 回归算法可以用来处理特征数远大于训练样本数文本分类问题。
3.3 Optimize Cost function by regularization
下面说明如何利用正则化来完善cost function. 首先看一个直观的例子。如图3-3所示,一开始由于多项式次数过高导致过拟合,但是如果在cost function后加上1000*theta3^2+1000*theta4^2, 为了使cost function最小,那么在优化(迭代)过程中,会使得theta3和theta4趋近于0,这样多项式后两项的高次作用就减少,过拟合得到了改善。这就相当于对非一般化特征量的惩罚。

图3-3 正则化的直观感受
3.3.1 Regularized linear regression
一般的,对于线性模型正则化后的cost function如下:
 (注意正则化不包括theta0)
(注意正则化不包括theta0)
Lambda的取值应该合适,如果过大(如10^10)将会导致theta都趋于0,所有的特征量没有被学习到,导致欠拟合。后面将会讨论lambda的取值,现在暂时认为在0~10之间。
既然cost function改变了,那么如果采用梯度下降法来优化,自然也要做相应的改变,如下:

作为线性回归的另一种模型,正规方程(the normal equations)也可以正则化,方式如下:
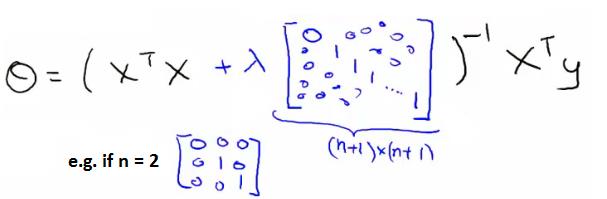
通过1.2.3节,我们知道,如果训练样本数m小于等于特征数n,那么X’X是不可逆的(使用matlab中pinv可以得到其伪逆),但是如果lambda > 0,则加上lambda乘以上图形式的矩阵后就可逆了。
3.3.2 Regularized logistic regression
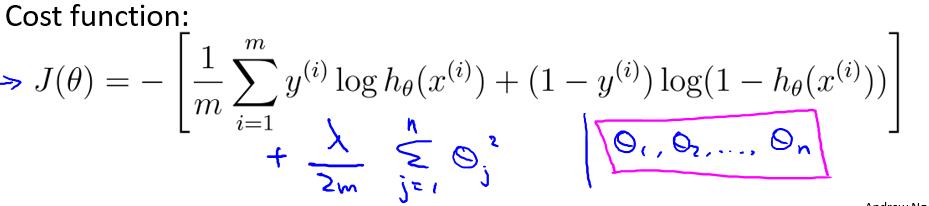

3.4 Advanced optimization
在实际的应用中,我们通常不会自己实现梯度下降法来优化目标函数,而是使用编程语言函数库。例如使用matlab中的fminunc函数。所以我们只需要编写出求cost function以及其导数的函数就可以了,以Logistic regression如下所示,(注意在matlab中向量下标以1开始,所以theta0应为theta(1))。

matlab实现Logistic regression的该函数代码如下:
function [J, grad] = costFunctionReg(theta, X, y, lambda) %COSTFUNCTIONREG Compute cost and gradient for logistic regression with regularization % J = COSTFUNCTIONREG(theta, X, y, lambda) computes the cost of using % theta as the parameter for regularized logistic regression and the % gradient of the cost w.r.t. to the parameters. m = length(y); % number of training examples n = size(X,2); % features number J = 0; grad = zeros(size(theta)); h = sigmoid(X * theta); % sigmoid function J = sum((-y) .* log(h) - (1-y) .* log(1-h)) / m + lambda * sum(theta(2:n) .^ 2) / (2*m); grad(1) = sum((h - y) .* X(:,1)) / m; for i = 2:n grad(i) = sum((h - y) .* X(:,i)) / m + lambda * theta(i) / m; end end
调用时的matlab代码片段如下:
% Initialize fitting parameters initial_theta = zeros(size(X, 2), 1); % Set regularization parameter lambda to 1 (you can vary this) lambda = 1; % Set Options options = optimset(\'GradObj\', \'on\', \'MaxIter\', 400); % Optimize [theta, J, exit_flag] = ... fminunc(@(t)(costFunctionReg(t, X, y, lambda)), initial_theta, options);
以上是关于Stanford机器学习笔记-3.Bayesian statistics and Regularization的主要内容,如果未能解决你的问题,请参考以下文章