1 storm基本概念 + storm编程规范及demo编写
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1 storm基本概念 + storm编程规范及demo编写相关的知识,希望对你有一定的参考价值。
本博文的主要内容有
.Storm的单机模式安装
.Storm的分布式安装(3节点)
.No space left on device
.storm工程的eclipse的java编写
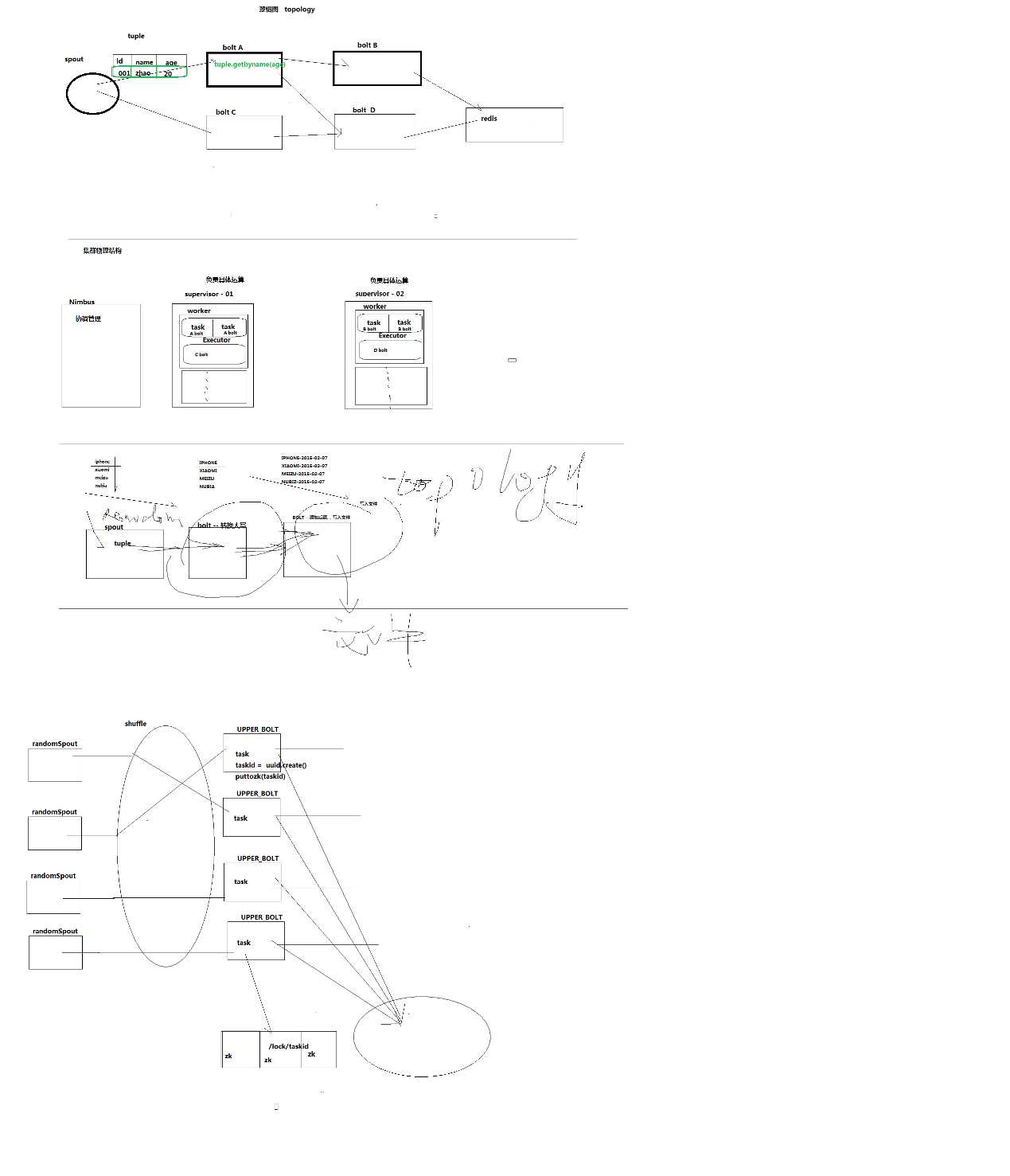
分布式的一个计算系统,但是跟mr不一样,就是实时的,实时的跟Mr离线批处理不一样。
离线mr主要是做数据挖掘、数据分析、数据统计和br分析。
Storm,主要是在线的业务系统。数据像水一样,源源不断的来,然后,在流动的过程中啊,就要把数据处理完。比如说,一些解析,业务系统里采集的一些日志信息、报文啊,然后呢,把它们解析成某一种格式,比如说解析过来的xml格式,然后呢,最后呢,要落到一个SQL或NoSQL数据库里去。
在这落进去之前,就得源源不断地,就要处理好,这一工具就是靠storm工具。
当然,hadoop也可以做,但是它那边是离线的批量。

Storm它自己,是不作任何存储的,数据有地方来,结果有地方去。一般是结合消息队列或数据库来用的,消息队列是数据源,数据库是数据目的地。











Bolts,可以理解为水厂里的处理的每个环节。
storm相关概念图
参考链接:http://www.xuebuyuan.com/1932716.html
http://www.aboutyun.com/thread-15397-1-1.html
Storm单机运行是不是不需要启动zookeeper、Nimbus、Supervisor ? About云开发
http://www.dataguru.cn/thread-477891-1-1.html
Storm单机+zookeeper集群安装
由于,Storm需要zookeeper,而,storm自带是没有zookeeper的。
需要依赖外部安装的zookeeper集群。业务里,一般都是3节点的zookeeper集群,而是这里只是现在入门,先来玩玩。
Zookeeper的单机模式安装,这里就不多赘述了。
见,我的博客
1 week110的zookeeper的安装 + zookeeper提供少量数据的存储
Storm的单机模式安装
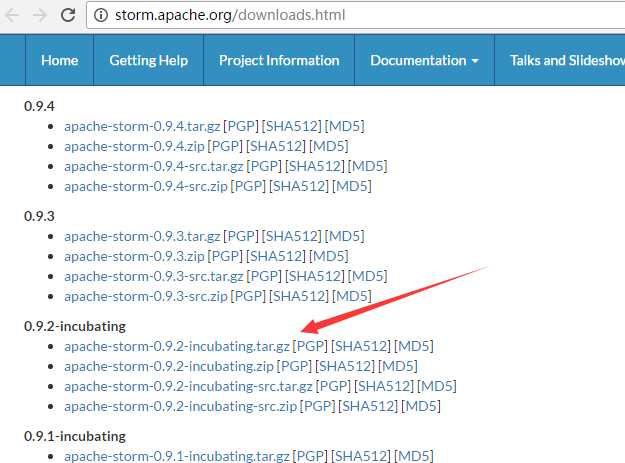
1、 apache-storm-0.9.2-incubating.tar.gz的下载
http://storm.apache.org/downloads.html
2、 apache-storm-0.9.2-incubating.tar.gz的上传
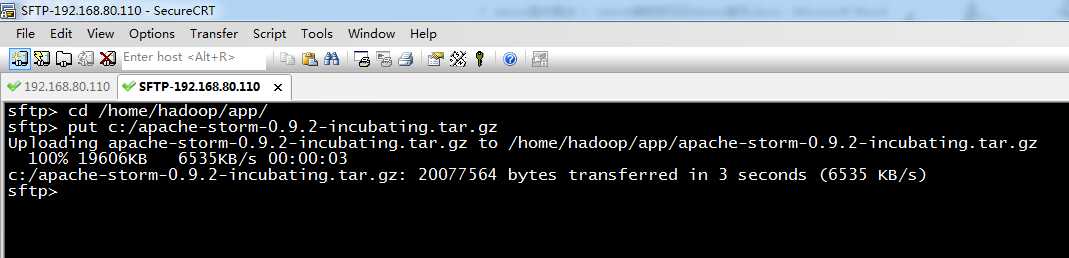
sftp> cd /home/hadoop/app/
sftp> put c:/apache-storm-0.9.2-incubating.tar.gz
Uploading apache-storm-0.9.2-incubating.tar.gz to /home/hadoop/app/apache-storm-0.9.2-incubating.tar.gz
100% 19606KB 6535KB/s 00:00:03
c:/apache-storm-0.9.2-incubating.tar.gz: 20077564 bytes transferred in 3 seconds (6535 KB/s)
sftp>

[[email protected] app]$ ls
hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65 kafka_2.10-0.8.1.1
[[email protected] app]$ ls
apache-storm-0.9.2-incubating.tar.gz hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65 kafka_2.10-0.8.1.1
3、 apache-storm-0.9.2-incubating.tar.gz的压缩
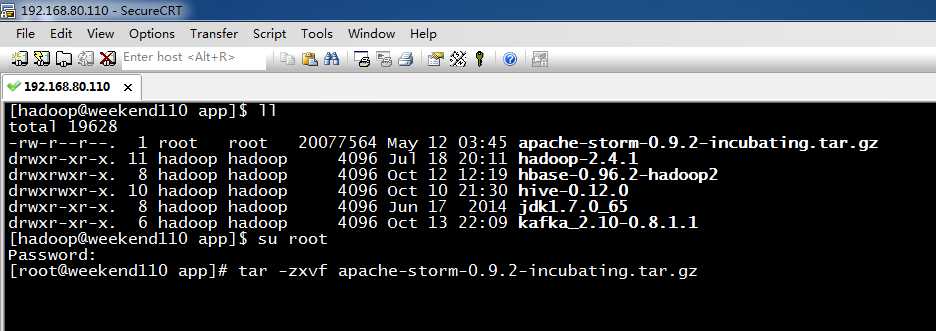
[[email protected] app]$ ll
total 19628
-rw-r--r--. 1 root root 20077564 May 12 03:45 apache-storm-0.9.2-incubating.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[[email protected] app]$ su root
Password:
[[email protected] app]# tar -zxvf apache-storm-0.9.2-incubating.tar.gz
4、 apache-storm-0.9.2-incubating.tar.gz的权限修改和删除压缩包
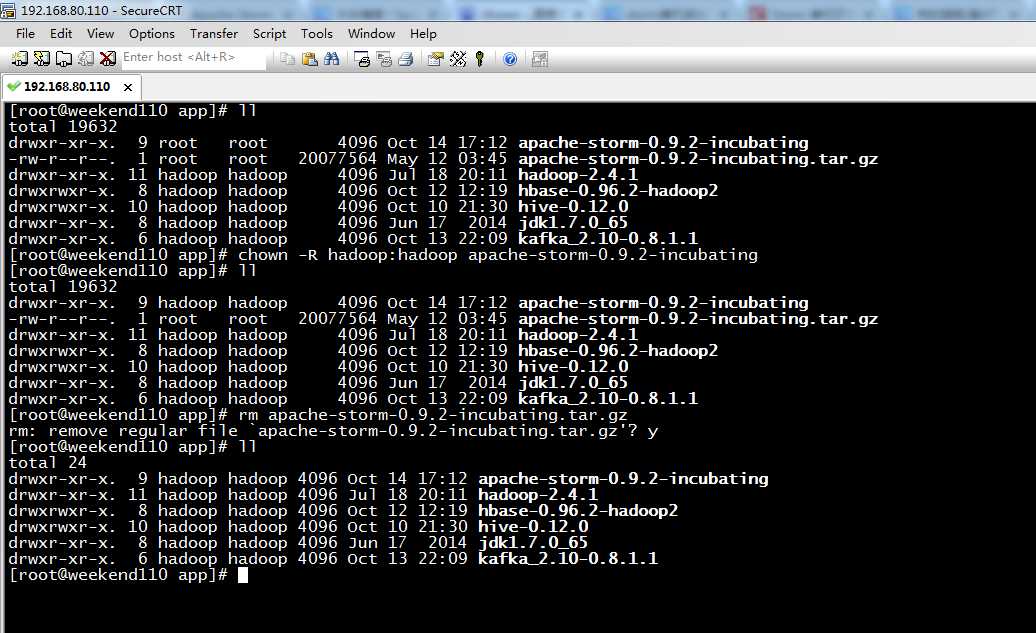
[[email protected] app]# ll
total 19632
drwxr-xr-x. 9 root root 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
-rw-r--r--. 1 root root 20077564 May 12 03:45 apache-storm-0.9.2-incubating.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[[email protected] app]# chown -R hadoop:hadoop apache-storm-0.9.2-incubating
[[email protected] app]# ll
total 19632
drwxr-xr-x. 9 hadoop hadoop 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
-rw-r--r--. 1 root root 20077564 May 12 03:45 apache-storm-0.9.2-incubating.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[[email protected] app]# rm apache-storm-0.9.2-incubating.tar.gz
rm: remove regular file `apache-storm-0.9.2-incubating.tar.gz‘? y
[[email protected] app]# ll
total 24
drwxr-xr-x. 9 hadoop hadoop 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[[email protected] app]#
5、 apache-storm-0.9.2-incubating.tar.gz的配置
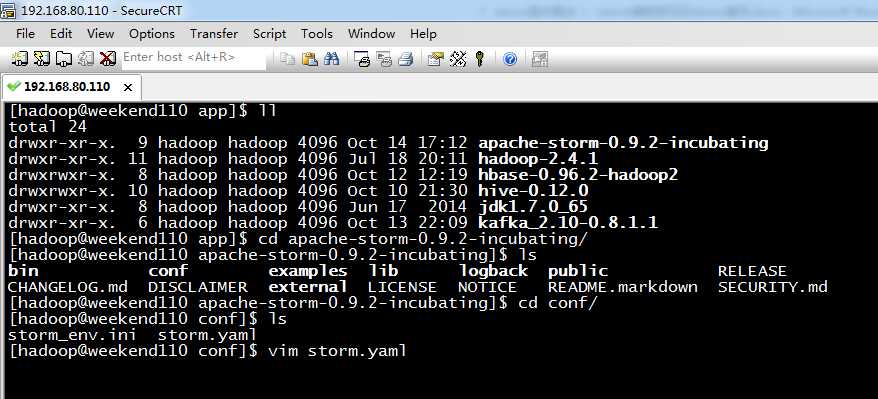
[[email protected] app]$ ll
total 24
drwxr-xr-x. 9 hadoop hadoop 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[[email protected] app]$ cd apache-storm-0.9.2-incubating/
[[email protected] apache-storm-0.9.2-incubating]$ ls
bin conf examples lib logback public RELEASE
CHANGELOG.md DISCLAIMER external LICENSE NOTICE README.markdown SECURITY.md
[[email protected] apache-storm-0.9.2-incubating]$ cd conf/
[[email protected] conf]$ ls
storm_env.ini storm.yaml
[[email protected] conf]$ vim storm.yaml
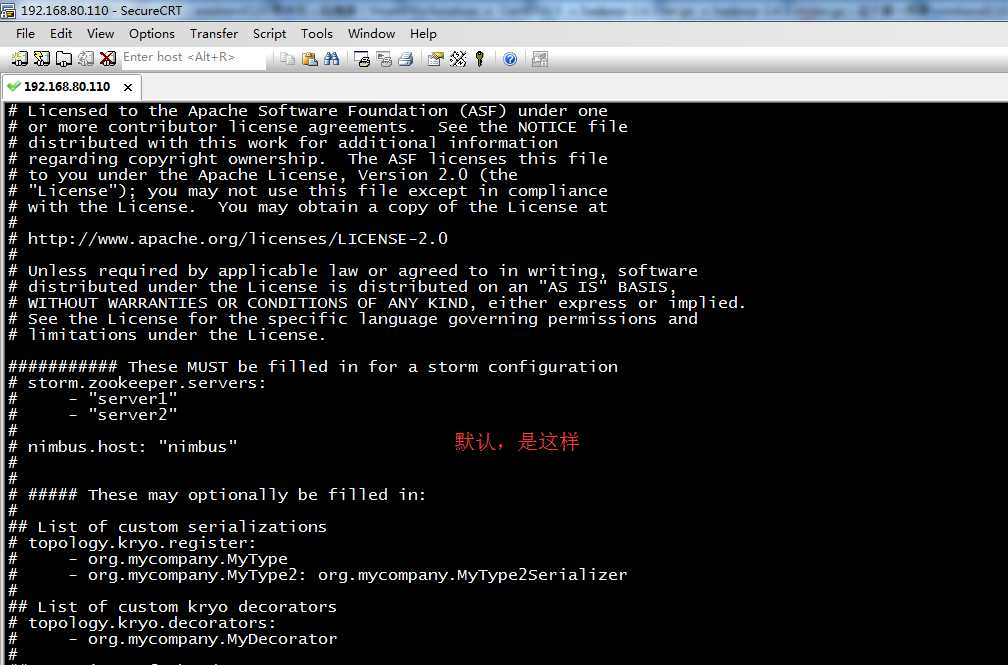
# storm.zookeeper.servers:
# - "server1"
# - "server2"
#
# nimbus.host: "nimbus"
修改为
#storm所使用的zookeeper集群主机
storm.zookeeper.servers:
- "weekend110"
#nimbus所在的主机名
nimbus.host: " weekend110"
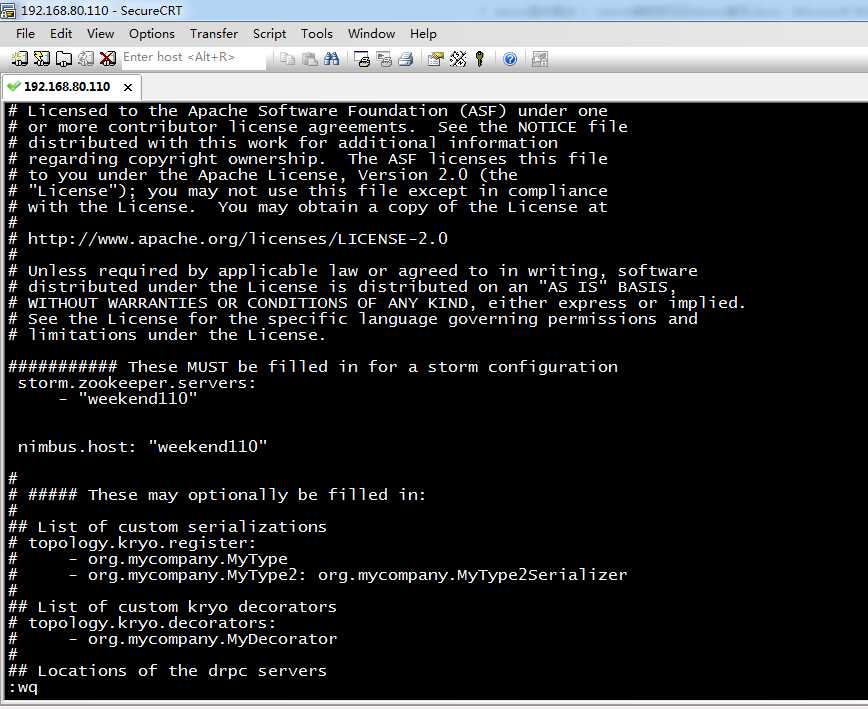
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "weekend110"
nimbus.host: "weekend110"
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2"
## Metrics Consumers
# topology.metrics.consumer.register:
# - class: "backtype.storm.metric.LoggingMetricsConsumer"
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
在这里,也许,修改不了,就换成root权限。
6、apache-storm-0.9.2-incubating.tar.gz环境变量
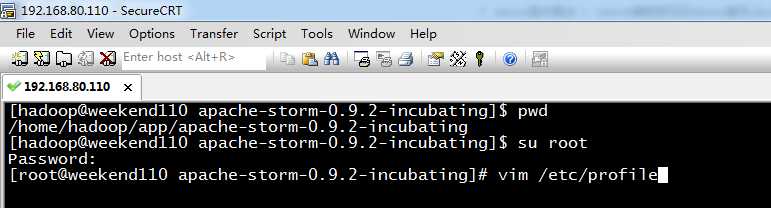
[[email protected] apache-storm-0.9.2-incubating]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating
[[email protected] apache-storm-0.9.2-incubating]$ su root
Password:
[[email protected] apache-storm-0.9.2-incubating]# vim /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper-3.4.6
export HIVE_HOME=/home/hadoop/app/hive-0.12.0
export HBASE_HOME=/home/hadoop/app/hbase-0.96.2-hadoop2
export STORM_HOME=/home/hadoop/app/apache-storm-0.9.2-incubating
export KAFKA_HOME=/home/hadoop/app/kafka_2.10-0.8.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin
[[email protected] apache-storm-0.9.2-incubating]# source /etc/profile
[[email protected] apache-storm-0.9.2-incubating]#
启动
先启动,外部安装的zookeeper,
[[email protected] apache-storm-0.9.2-incubating]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating
[[email protected] apache-storm-0.9.2-incubating]$ jps
4640 Jps
[[email protected] apache-storm-0.9.2-incubating]$ cd /home/hadoop/app/zookeeper-3.4.6/
[[email protected] zookeeper-3.4.6]$ pwd
/home/hadoop/app/zookeeper-3.4.6
[[email protected] zookeeper-3.4.6]$ cd bin
[[email protected] bin]$ ./zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[[email protected] bin]$ jps
4675 Jps
4659 QuorumPeerMain
[[email protected] bin]$ cd /home/hadoop/app/apache-storm-0.9.2-incubating/
[[email protected] apache-storm-0.9.2-incubating]$ cd bin
[[email protected] bin]$ ls
storm storm.cmd storm-config.cmd
[[email protected] bin]$ ./storm nimbus
参考:
一般,推荐
在nimbus机器上,执行
[[email protected] bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
//意思是,启动主节点
[[email protected] bin]$ nohup ./storm ui 1>/dev/null 2>&1 &
//意思是,启动ui界面
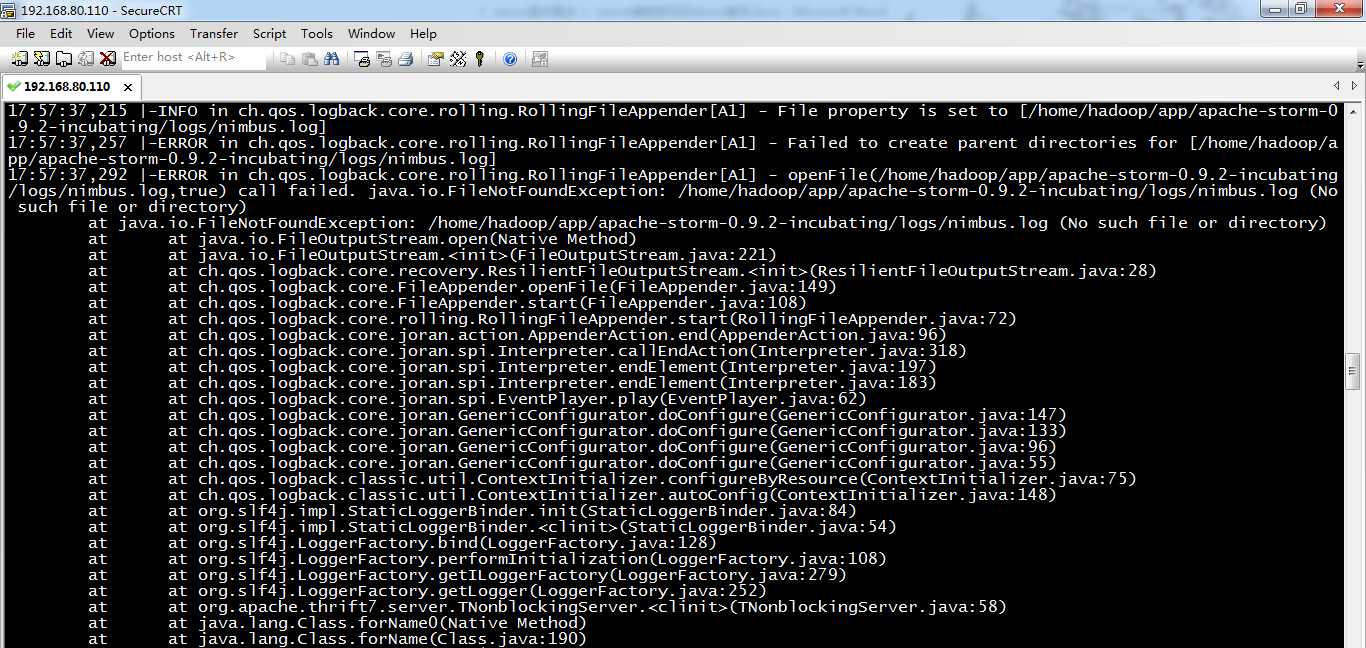
启动,报错误。
http://blog.csdn.net/asas1314/article/details/44088003
参考这篇博客。
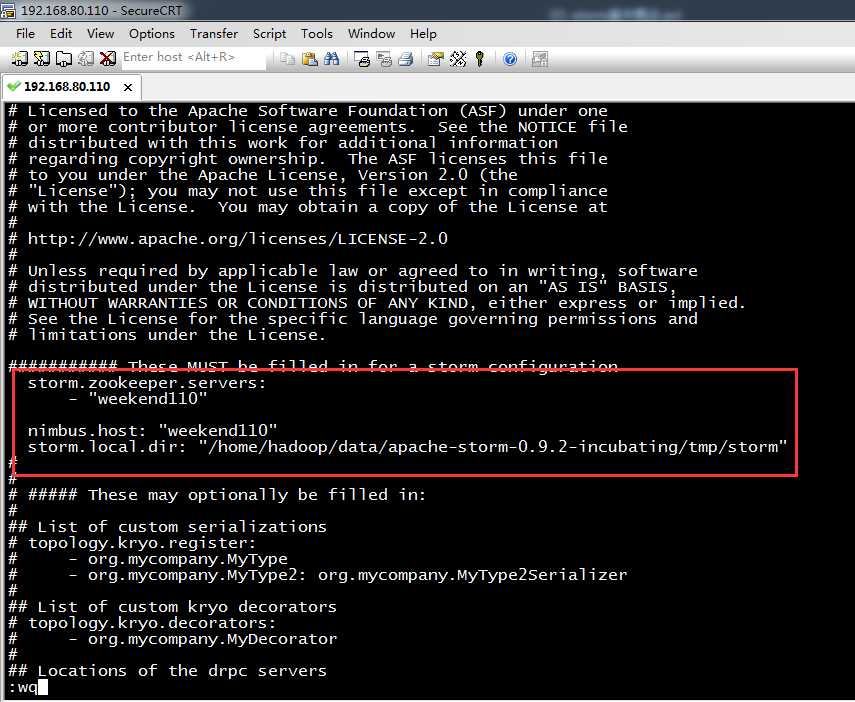
storm.zookeeper.servers:
- "192.168.1.117"
nimbus.host: "192.168.1.117"
storm.local.dir: "/home/chenny/Storm/tmp/storm"
java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"
topology.debug: "true"
需要注意的是Storm读取此配置文件,要求每一行开始都要有一个空格,每一个冒号后面也要有一个空格,否则就会出现错误,造成启动失败。我们同样可以为Storm添加环境变量,来方便我们的启动、停止。
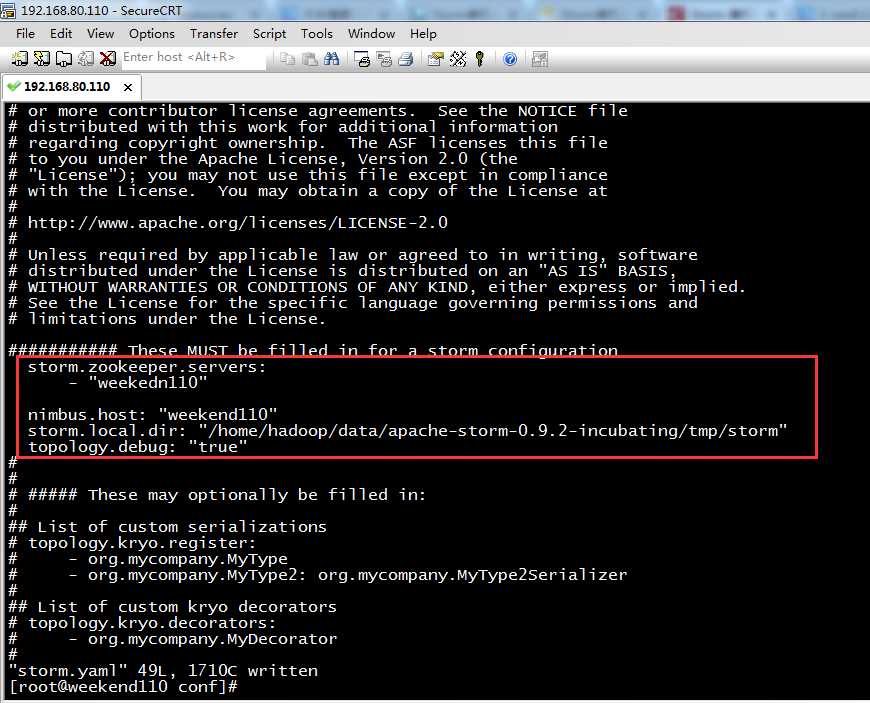
storm.zookeeper.servers:
- "weekedn110"
nimbus.host: "weekend110"
storm.local.dir: "/home/hadoop/data/apache-storm-0.9.2-incubating/tmp/storm"
topology.debug: "true"

[[email protected] apache-storm-0.9.2-incubating]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating
[[email protected] apache-storm-0.9.2-incubating]$ mkdir -p /home/hadoop/data/apache-storm-0.9.2-incubating/tmp/storm
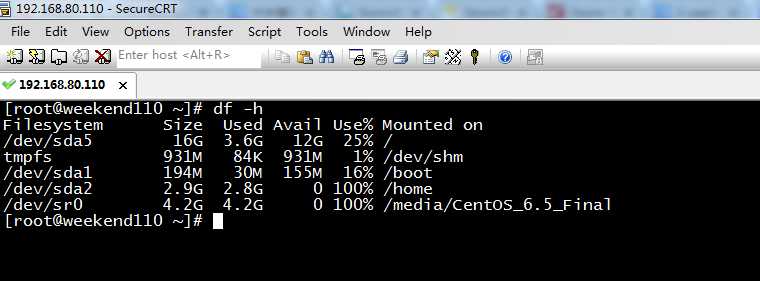
mkdir: cannot create directory `/home/hadoop/data/apache-storm-0.9.2-incubating‘: No space left on device
[[email protected] apache-storm-0.9.2-incubating]$
清理下磁盘,就好。
参考博客: http://www.3fwork.com/b902/002559MYM000559/
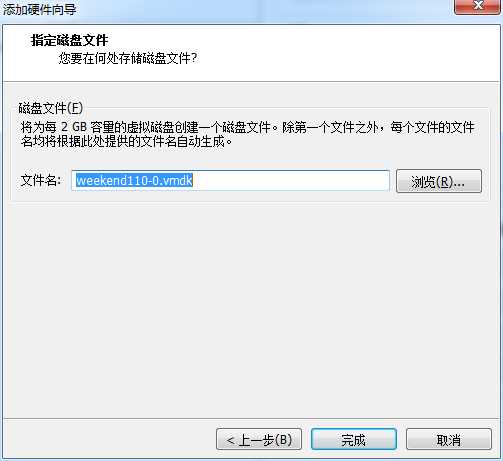
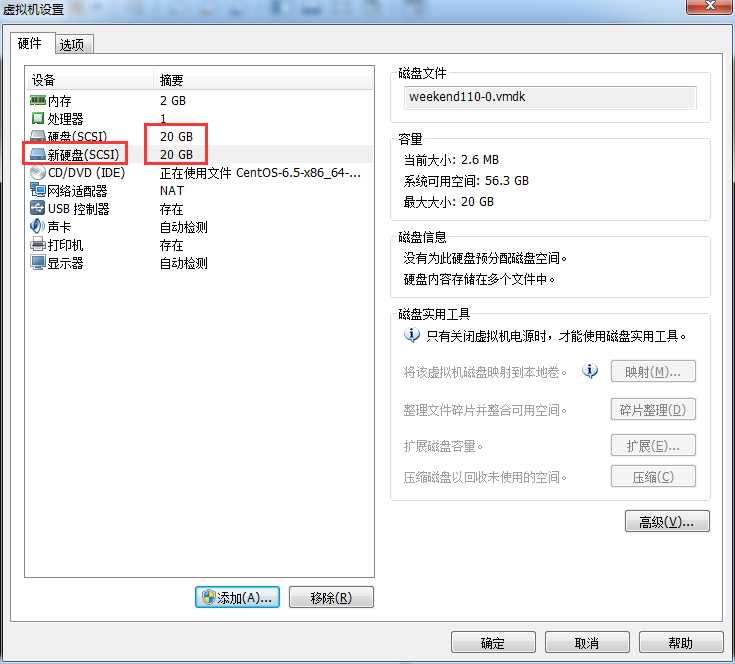
1、使用fdisk -l查询当前系统分区情况
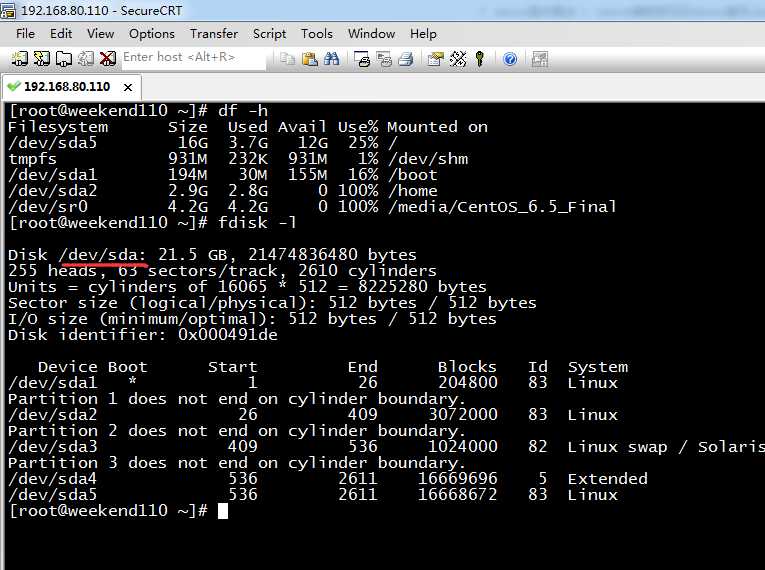
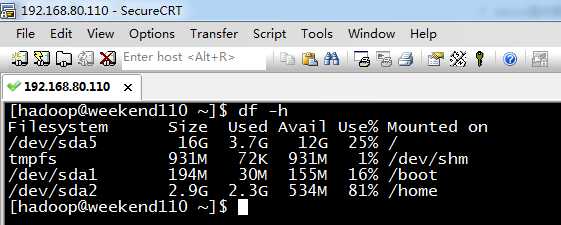
[[email protected] ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 16G 3.7G 12G 25% /
tmpfs 931M 232K 931M 1% /dev/shm
/dev/sda1 194M 30M 155M 16% /boot
/dev/sda2 2.9G 2.8G 0 100% /home
/dev/sr0 4.2G 4.2G 0 100% /media/CentOS_6.5_Final
[[email protected] ~]# fdisk -l
Disk /dev/sda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000491de
Device Boot Start End Blocks Id System
/dev/sda1 * 1 26 204800 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 26 409 3072000 83 Linux
Partition 2 does not end on cylinder boundary.
/dev/sda3 409 536 1024000 82 Linux swap / Solaris
Partition 3 does not end on cylinder boundary.
/dev/sda4 536 2611 16669696 5 Extended
/dev/sda5 536 2611 16668672 83 Linux
[[email protected] ~]#
可以看到新增加的sda磁盘还没有分区!!!
重启机器,后,再次执行
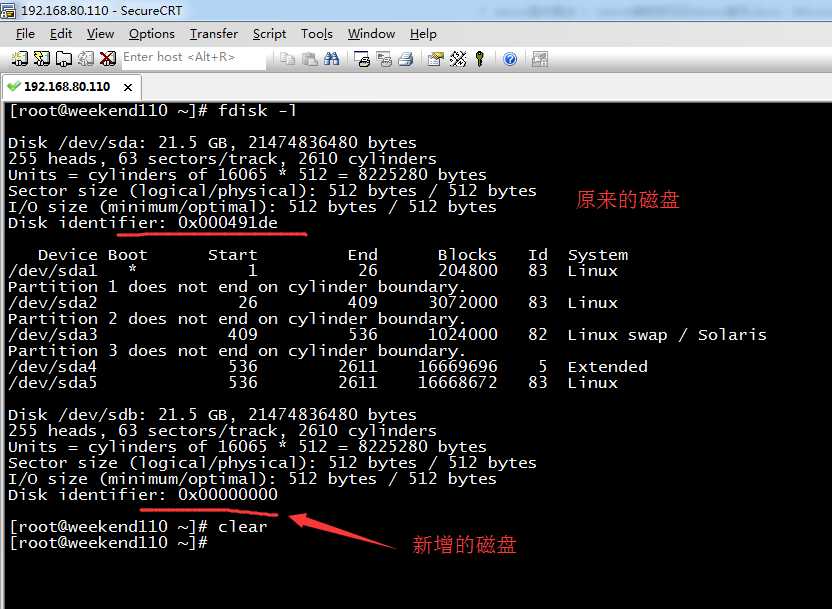
[[email protected] ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 16G 3.7G 12G 25% /
tmpfs 931M 72K 931M 1% /dev/shm
/dev/sda1 194M 30M 155M 16% /boot
/dev/sda2 2.9G 2.8G 0 100% /home
[[email protected] ~]# fdisk -l
Disk /dev/sda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000491de
想说的是,一看/dev/sda,就是原来的硬盘。
Device Boot Start End Blocks Id System
/dev/sda1 * 1 26 204800 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 26 409 3072000 83 Linux
Partition 2 does not end on cylinder boundary.
/dev/sda3 409 536 1024000 82 Linux swap / Solaris
Partition 3 does not end on cylinder boundary.
/dev/sda4 536 2611 16669696 5 Extended
/dev/sda5 536 2611 16668672 83 Linux
Disk /dev/sdb: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
想说的是,一看/dev/sda,就是新增的硬盘。
2.创建主分区
因为,新增磁盘,是sdb。
fdisk /dev/sdb
输入n
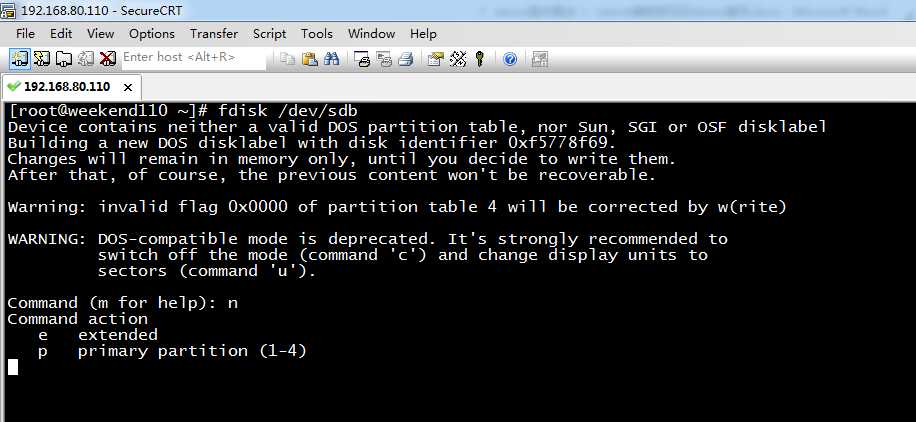
[[email protected] ~]# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0xf5778f69.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won‘t be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It‘s strongly recommended to
switch off the mode (command ‘c‘) and change display units to
sectors (command ‘u‘).
Command (m for help): n
Command action
e extended
p primary partition (1-4)
提示说,输入p
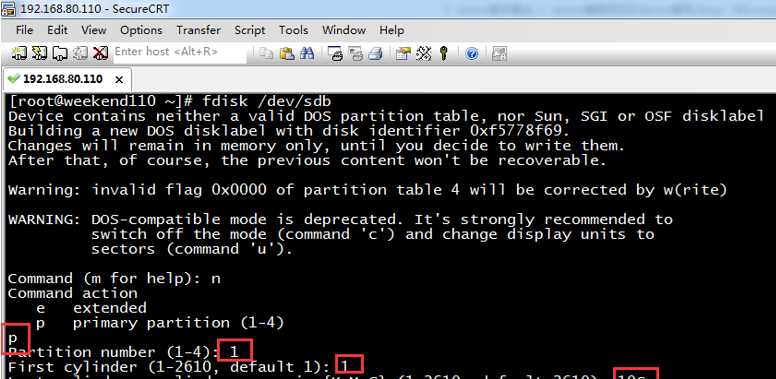
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-2610, default 1): 1
Last cylinder, +cylinders or +size{K,M,G} (1-2610, default 2610): +10G
Command (m for help):
在输入结束柱面的这里如果你不知道该输入多大的数字,你可以输入+然后输入你要设的大小。这里我设置10G的主分区。
输入p查看分区信息,可以看到刚创建的sdb1主分区。
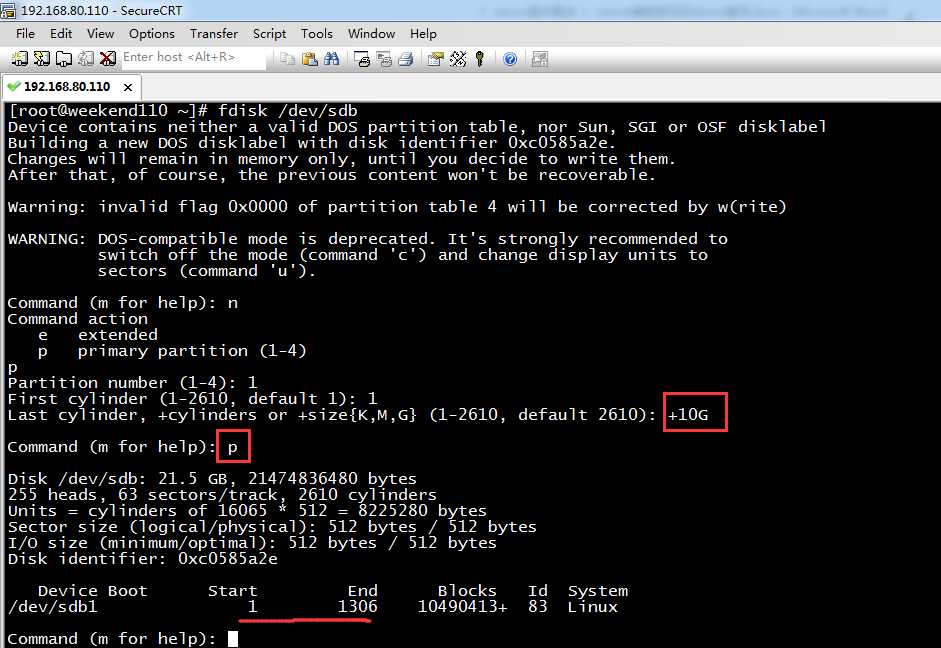
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xc0585a2e
Device Boot Start End Blocks Id System
/dev/sdb1 1 1306 10490413+ 83 Linux
Command (m for help):
3、创建扩展分区
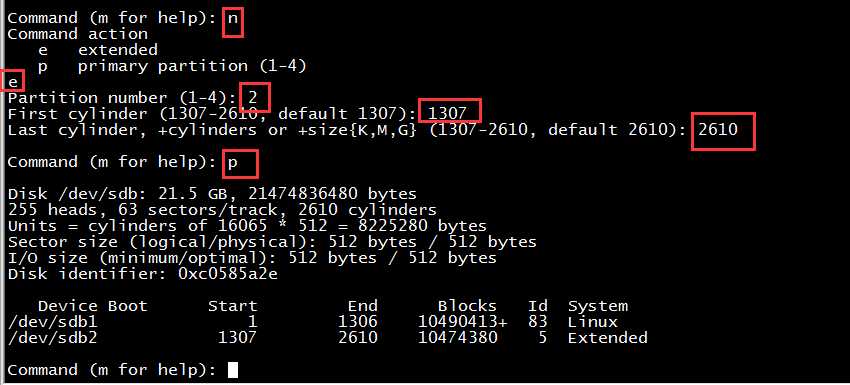
Command (m for help): n
Command action
e extended
p primary partition (1-4)
e
Partition number (1-4): 2
First cylinder (1307-2610, default 1307): 1307
Last cylinder, +cylinders or +size{K,M,G} (1307-2610, default 2610): 2610
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xc0585a2e
Device Boot Start End Blocks Id System
/dev/sdb1 1 1306 10490413+ 83 Linux
/dev/sdb2 1307 2610 10474380 5 Extended
Command (m for help):
图片上通过红色标注了操作步骤。可以看到当前已创建了sdb2扩展分区,柱面从1037-2610,即将剩下的所有空间创建为扩展分区。
4.创建逻辑分区
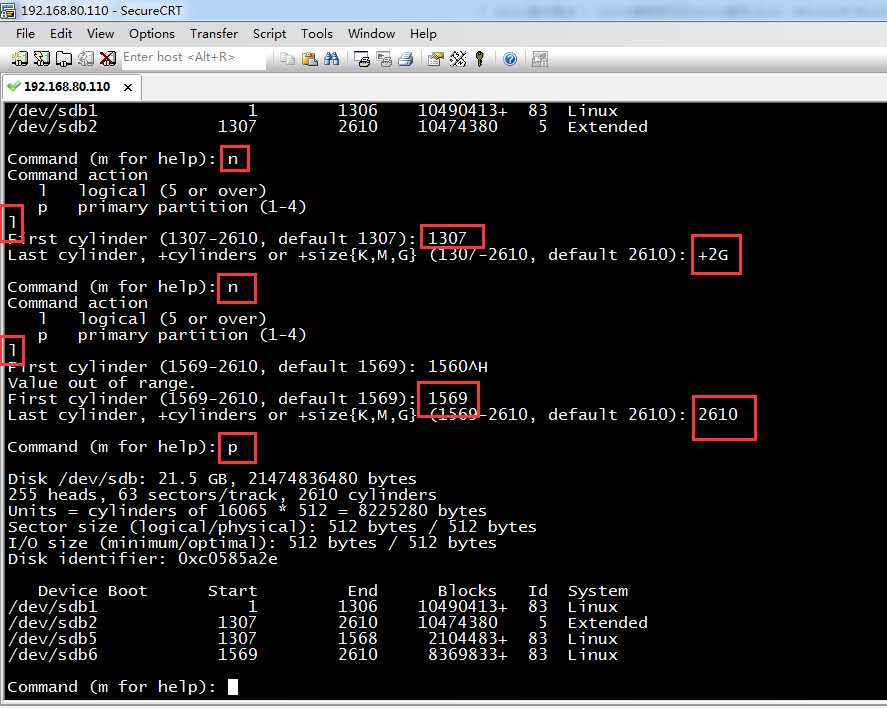
Command (m for help): n
Command action
l logical (5 or over)
p primary partition (1-4)
l
First cylinder (1307-2610, default 1307): 1307
Last cylinder, +cylinders or +size{K,M,G} (1307-2610, default 2610): +2G
Command (m for help): n
Command action
l logical (5 or over)
p primary partition (1-4)
l
First cylinder (1569-2610, default 1569): 1560^H
Value out of range.
First cylinder (1569-2610, default 1569): 1569
Last cylinder, +cylinders or +size{K,M,G} (1569-2610, default 2610): 2610
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xc0585a2e
Device Boot Start End Blocks Id System
/dev/sdb1 1 1306 10490413+ 83 Linux
/dev/sdb2 1307 2610 10474380 5 Extended
/dev/sdb5 1307 1568 2104483+ 83 Linux
/dev/sdb6 1569 2610 8369833+ 83 Linux
Command (m for help):
总共创建了两个逻辑分区,逻辑分区默认从5开始,第一个逻辑分区大小2G,用来做交换分区用,剩下全部给sdb6.
5.修改文件类型ID
因为默认分区id都是83即linux文件类型,现在将sdb5的文件类型ID改成82即交换分区。
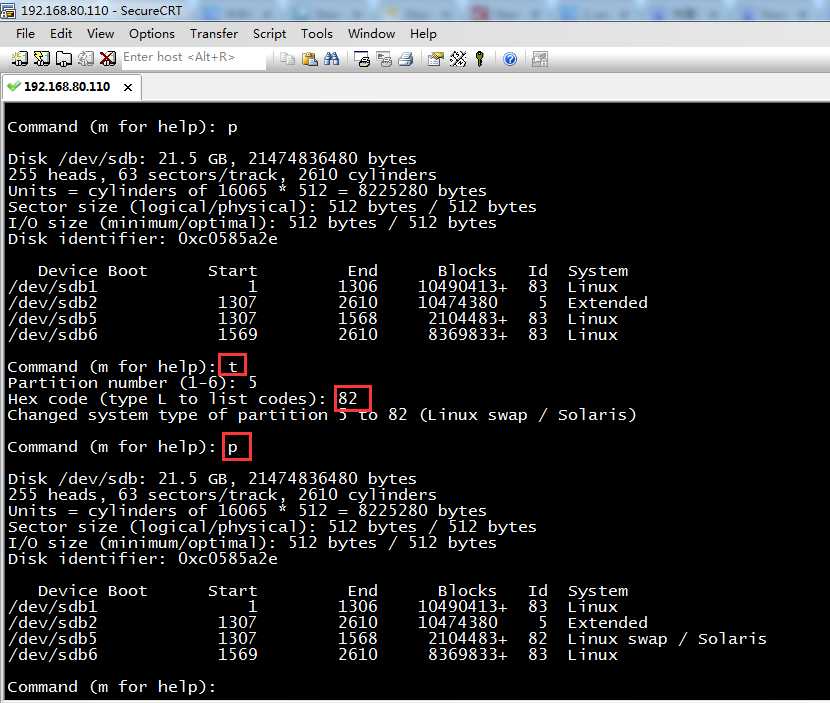
Command (m for help): t
Partition number (1-6): 5
Hex code (type L to list codes): 82
Changed system type of partition 5 to 82 (Linux swap / Solaris)
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xc0585a2e
Device Boot Start End Blocks Id System
/dev/sdb1 1 1306 10490413+ 83 Linux
/dev/sdb2 1307 2610 10474380 5 Extended
/dev/sdb5 1307 1568 2104483+ 82 Linux swap / Solaris
/dev/sdb6 1569 2610 8369833+ 83 Linux
Command (m for help):
6.保存退出
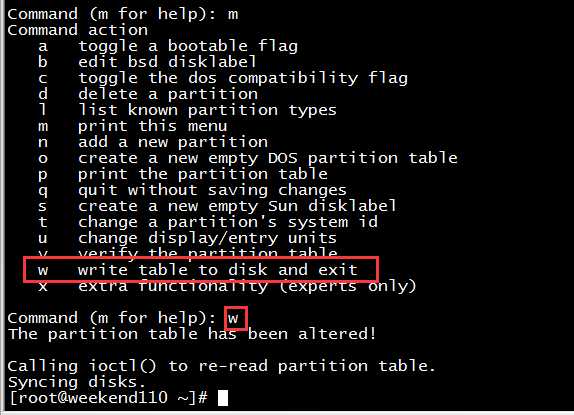
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition‘s system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[[email protected] ~]#
7.格式化分区
接下来要对sdb的每一个分区进行格式化,
注意:扩展分区不需要进行格式
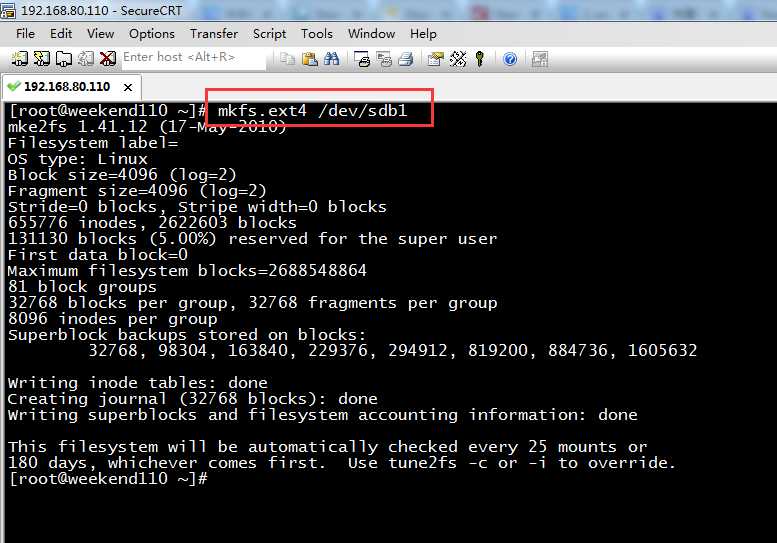
[[email protected] ~]# mkfs.ext4 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
655776 inodes, 2622603 blocks
131130 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2688548864
81 block groups
32768 blocks per group, 32768 fragments per group
8096 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 25 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[[email protected] ~]#
[[email protected] ~]# mkfs.ext4 /dev/sdb6
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
523264 inodes, 2092458 blocks
104622 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2143289344
64 block groups
32768 blocks per group, 32768 fragments per group
8176 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 25 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[[email protected] ~]#
swap分区格式化要使用
mkswap /dev/sdb5
[[email protected] ~]# mkswap /dev/sdb5
Setting up swapspace version 1, size = 2104476 KiB
no label, UUID=d28dfa28-7303-463a-ae0c-b1751786c656
[[email protected] ~]#
加载文件
swapon /dev/sdb5
查看是否生效
swapon -s
[[email protected] ~]# swapon /dev/sdb5
[[email protected] ~]# swapon -s
Filename Type Size Used Priority
/dev/sda3 partition 1023992 0 -1
/dev/sdb5 partition 2104472 0 -2
[[email protected] ~]#
可以看到sda3,和sdb5这两个swap分区
8.挂载分区
这里直接使用修改文件的方式永久挂载
创建挂载文件路径
mkdir sdb1 sdb6
[[email protected] ~]# mkdir sdb1 sdb6
[[email protected] ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 16G 3.7G 12G 25% /
tmpfs 931M 72K 931M 1% /dev/shm
/dev/sda1 194M 30M 155M 16% /boot
/dev/sda2 2.9G 2.8G 0 100% /home
[[email protected] ~]#
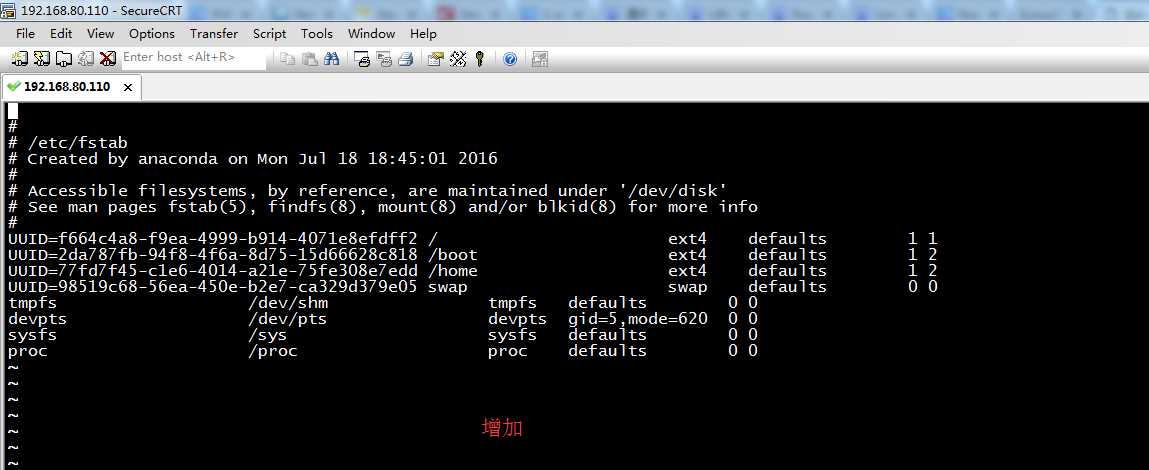
#
# /etc/fstab
# Created by anaconda on Mon Jul 18 18:45:01 2016
#
# Accessible filesystems, by reference, are maintained under ‘/dev/disk‘
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=f664c4a8-f9ea-4999-b914-4071e8efdff2 / ext4 defaults 1 1
UUID=2da787fb-94f8-4f6a-8d75-15d66628c818 /boot ext4 defaults 1 2
UUID=77fd7f45-c1e6-4014-a21e-75fe308e7edd /home ext4 defaults 1 2
UUID=98519c68-56ea-450e-b2e7-ca329d379e05 swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
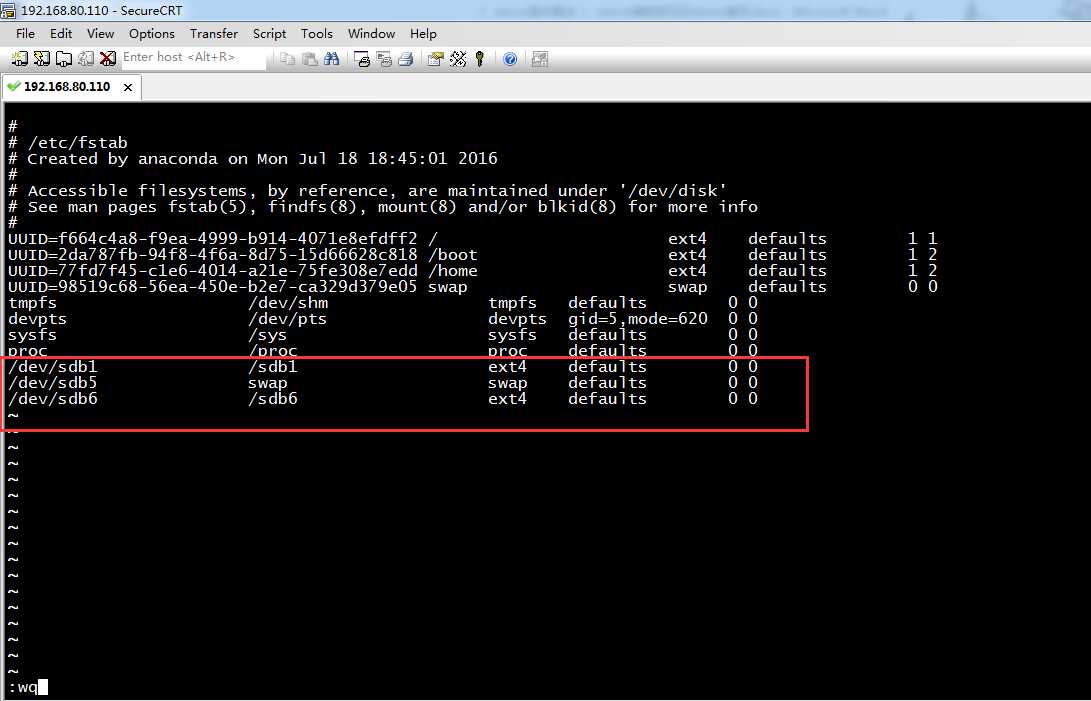
/dev/sdb1 /sdb1 ext4 defaults 0 0
/dev/sdb5 swap swap defaults 0 0
/dev/sdb6 /sdb6 ext4 defaults 0 0
9.立即生效
partprobe
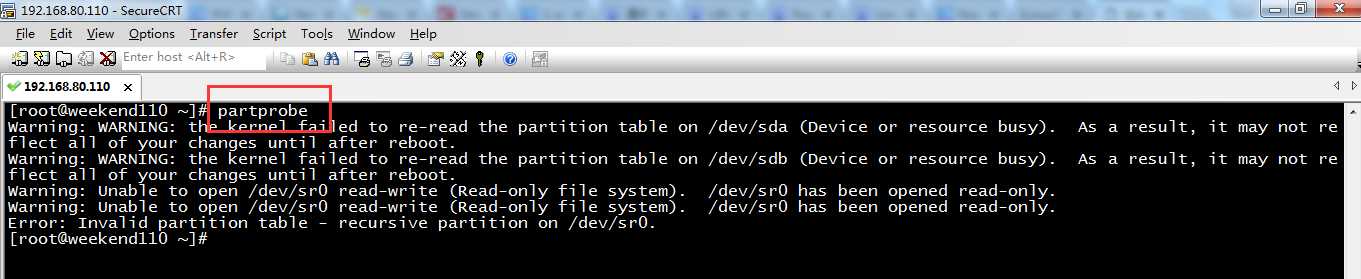
[[email protected] ~]# partprobe
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sdb (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Error: Invalid partition table - recursive partition on /dev/sr0.
[[email protected] ~]#
在我的虚拟机上面无法立即生效,重启机器。
shutdown -r now
[[email protected] ~]# shutdown -r now
Broadcast message from [email protected]
(/dev/pts/0) at 23:58 ...
The system is going down for reboot NOW!
[[email protected] ~]#
没生效,那是因为,遇到了
Error: Invalid partition table - recursive partition on /dev/sr0.
参考博客:
http://www.mincoder.com/article/3454.shtml
决方法:执行partprobe 命令
partprobe包含在parted的rpm软件包中。
partprobe可以修改kernel中分区表,使kernel重新读取分区表。
因此,使用该命令就可以创建分区并且在不重新启动机器的情况下系统能够识别这些分区。
[[email protected] ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 16G 3.7G 12G 25% /
tmpfs 931M 72K 931M 1% /dev/shm
/dev/sda1 194M 30M 155M 16% /boot
/dev/sda2 2.9G 2.8G 0 100% /home
[[email protected] ~]# partprobe
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sdb (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Error: Invalid partition table - recursive partition on /dev/sr0.
[[email protected] ~]# rpm -q parted
parted-2.1-21.el6.x86_64
[[email protected] ~]# partprobe
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sdb (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Error: Invalid partition table - recursive partition on /dev/sr0.
[[email protected] ~]# mkfs -t ext4 /dev/sr0
mke2fs 1.41.12 (17-May-2010)
/dev/sr0 is entire device, not just one partition!
Proceed anyway? (y,n) y
/dev/sr0: Read-only file system while setting up superblock
[[email protected] ~]# partprobe
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sdb (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
Error: Invalid partition table - recursive partition on /dev/sr0.
[[email protected] ~]#
[[email protected] ~]# fdisk -l /dev/sda
Disk /dev/sda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000491de
Device Boot Start End Blocks Id System
/dev/sda1 * 1 26 204800 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 26 409 3072000 83 Linux
Partition 2 does not end on cylinder boundary.
/dev/sda3 409 536 1024000 82 Linux swap / Solaris
Partition 3 does not end on cylinder boundary.
/dev/sda4 536 2611 16669696 5 Extended
/dev/sda5 536 2611 16668672 83 Linux
[[email protected] ~]#
经过,这个问题,依然还是解决不了。。
为此,我把storm的路径,安装到了,/usr/local/下,
吸取了,教训,就是,在系统安装之前。分区要大些。
特别对于/和/home/,这两个分区。因为是常安装软件的目录啊!!!呜呜~~
在这里,我依然还是未解决问题。
记本博文于此,为了方便日后的再常阅和再解决!
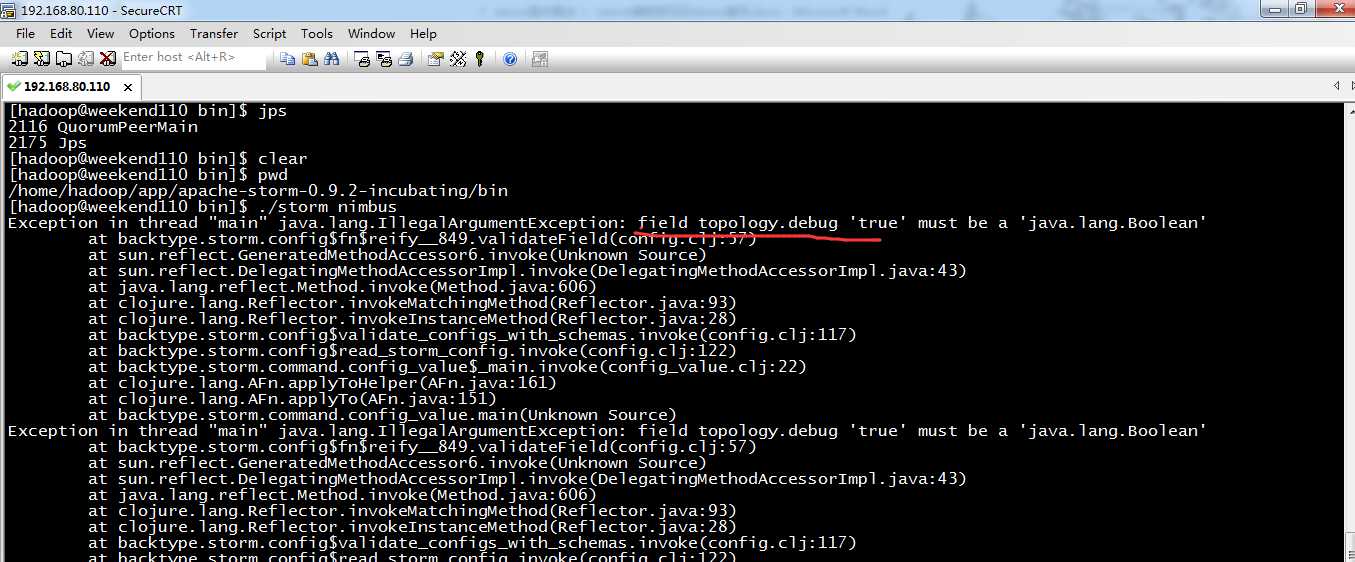
错误:
Exception in thread "main" java.lang.IllegalArgumentException: field topology.debug ‘true‘ must be a ‘java.lang.Boolean‘
但是,这是前台程序,把这个窗口一关,就不行了。
一般,推荐
[[email protected] bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
//意思是,启动主节点
[[email protected] bin]$ nohup ./storm ui 1>/dev/null 2>&1 &
//意思是,启动ui界面
[[email protected] bin]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating/bin
[[email protected] bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
[1] 2700
[[email protected] bin]$ nohup ./storm ui 1>/dev/null 2>&1 &
[2] 2742
[[email protected] apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2701 config_value //代表,正在启动,是中间进程,这里是nimbus的中间进程
2710 Jps
[[email protected] apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2700 nimbus
2743 config_value //代表,正在启动,是中间进程,这里是core的中间进程
2752 Jps
[[email protected] apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2797 nimbus
2742 core
2826 Jps
[[email protected] apache-storm-0.9.2-incubating]$
启动storm
在nimbus主机上
nohup ./storm nimbus 1>/dev/null 2>&1 &
nohup ./storm ui 1>/dev/null 2>&1 &
在supervisor主机上
nohup ./storm supervisor 1>/dev/null 2>&1 &
[[email protected] bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
[3] 2864
[[email protected] bin]$ nohup ./storm supervisor 1>/dev/null 2>&1 &
[4] 2875
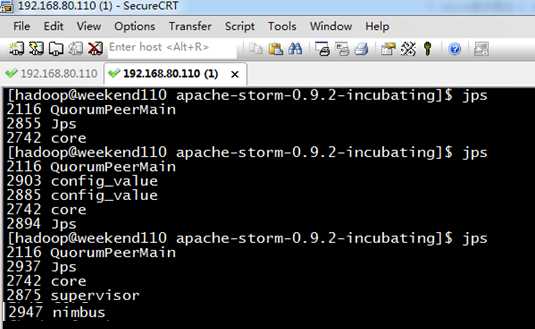
[[email protected] apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2855 Jps
2742 core
[[email protected] apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2903 config_value
2885 config_value
2742 core
2894 Jps
[[email protected] apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2937 Jps
2742 core
2875 supervisor
2947 nimbus
[[email protected] apache-storm-0.9.2-incubating]$
进入,
Storm UI
Cluster Summary
|
Version |
Nimbus uptime |
Supervisors |
Used slots |
Free slots |
Total slots |
Executors |
Tasks |
|
0.9.2-incubating |
10m 41s |
1 |
0 |
4 |
4 |
0 |
0 |
Topology summary
|
Name |
Id |
Status |
Uptime |
Num workers |
Num executors |
Num tasks |
Supervisor summary
|
Id |
Host |
Uptime |
Slots |
Used slots |
|
3a41e7dd-0160-4ad0-bad5-096cdba4647e |
weekend110 |
9m 30s |
4 |
0 |
Nimbus Configuration
|
Key |
Value |
|
dev.zookeeper.path |
/tmp/dev-storm-zookeeper |
|
topology.tick.tuple.freq.secs |
|
|
topology.builtin.metrics.bucket.size.secs |
60 |
|
topology.fall.back.on.java.serialization |
true |
|
topology.max.error.report.per.interval |
5 |
|
zmq.linger.millis |
5000 |
|
topology.skip.missing.kryo.registrations |
false |
|
storm.messaging.netty.client_worker_threads |
1 |
|
ui.childopts |
-Xmx768m |
|
storm.zookeeper.session.timeout |
20000 |
|
nimbus.reassign |
true |
|
topology.trident.batch.emit.interval.millis |
500 |
|
storm.messaging.netty.flush.check.interval.ms |
10 |
|
nimbus.monitor.freq.secs |
10 |
|
logviewer.childopts |
-Xmx128m |
|
java.library.path |
/usr/local/lib:/opt/local/lib:/usr/lib |
|
topology.executor.send.buffer.size |
1024 |
|
storm.local.dir |
/home/hadoop/data/apache-storm-0.9.2-incubating/tmp/storm |
|
storm.messaging.netty.buffer_size |
5242880 |
|
supervisor.worker.start.timeout.secs |
120 |
|
topology.enable.message.timeouts |
true |
|
nimbus.cleanup.inbox.freq.secs |
600 |
|
nimbus.inbox.jar.expiration.secs |
3600 |
|
drpc.worker.threads |
64 |
|
topology.worker.shared.thread.pool.size |
4 |
|
nimbus.host |
weekend110 |
|
storm.messaging.netty.min_wait_ms |
100 |
|
storm.zookeeper.port |
2181 |
|
transactional.zookeeper.port |
|
|
topology.executor.receive.buffer.size |
1024 |
|
transactional.zookeeper.servers |
|
|
storm.zookeeper.root |
/storm |
|
storm.zookeeper.retry.intervalceiling.millis |
30000 |
|
supervisor.enable |
true |
|
storm.messaging.netty.server_worker_threads |
1 |
|
storm.zookeeper.servers |
weekend110 |
|
transactional.zookeeper.root |
/transactional |
|
topology.acker.executors |
|
|
topology.transfer.buffer.size |
1024 |
|
topology.worker.childopts |
|
|
drpc.queue.size |
128 |
|
worker.childopts |
-Xmx768m |
|
supervisor.heartbeat.frequency.secs |
5 |
|
topology.error.throttle.interval.secs |
10 |
|
zmq.hwm |
0 |
|
drpc.port |
3772 |
|
supervisor.monitor.frequency.secs |
3 |
|
drpc.childopts |
-Xmx768m |
|
topology.receiver.buffer.size |
8 |
|
task.heartbeat.frequency.secs |
3 |
|
topology.tasks |
|
|
storm.messaging.netty.max_retries |
30 |
|
topology.spout.wait.strategy |
backtype.storm.spout.SleepSpoutWaitStrategy |
|
nimbus.thrift.max_buffer_size |
1048576 |
|
topology.max.spout.pending |
|
|
storm.zookeeper.retry.interval |
1000 |
|
topology.sleep.spout.wait.strategy.time.ms |
1 |
|
nimbus.topology.validator |
backtype.storm.nimbus.DefaultTopologyValidator |
|
supervisor.slots.ports |
6700,6701,6702,6703 |
|
topology.debug |
false |
|
nimbus.task.launch.secs |
120 |
|
nimbus.supervisor.timeout.secs |
60 |
|
topology.message.timeout.secs |
30 |
|
task.refresh.poll.secs |
10 |
|
topology.workers |
1 |
|
supervisor.childopts |
-Xmx256m |
|
nimbus.thrift.port |
6627 |
|
topology.stats.sample.rate |
0.05 |
|
worker.heartbeat.frequency.secs |
1 |
|
topology.tuple.serializer |
backtype.storm.serialization.types.ListDelegateSerializer |
|
topology.disruptor.wait.strategy |
com.lmax.disruptor.BlockingWaitStrategy |
|
topology.multilang.serializer |
backtype.storm.multilang.JsonSerializer |
|
nimbus.task.timeout.secs |
30 |
|
storm.zookeeper.connection.timeout |
15000 |
|
topology.kryo.factory |
backtype.storm.serialization.DefaultKryoFactory |
|
drpc.invocations.port |
3773 |
|
logviewer.port |
8000 |
|
zmq.threads |
1 |
|
storm.zookeeper.retry.times |
5 |
|
topology.worker.receiver.thread.count |
1 |
|
storm.thrift.transport |
backtype.storm.security.auth.SimpleTransportPlugin |
|
topology.state.synchronization.timeout.secs |
60 |
|
supervisor.worker.timeout.secs |
30 |
|
nimbus.file.copy.expiration.secs |
600 |
|
storm.messaging.transport |
backtype.storm.messaging.netty.Context |
|
logviewer.appender.name |
A1 |
|
storm.messaging.netty.max_wait_ms |
1000 |
|
drpc.request.timeout.secs |
600 |
|
storm.local.mode.zmq |
false |
|
ui.port |
8080 |
|
nimbus.childopts |
-Xmx1024m |
|
storm.cluster.mode |
distributed |
|
topology.max.task.parallelism |
|
|
storm.messaging.netty.transfer.batch.size |
262144 |
这里呢,我因为,是方便入门和深入理解概念。所以,玩得是单机模式。
storm分布式模式
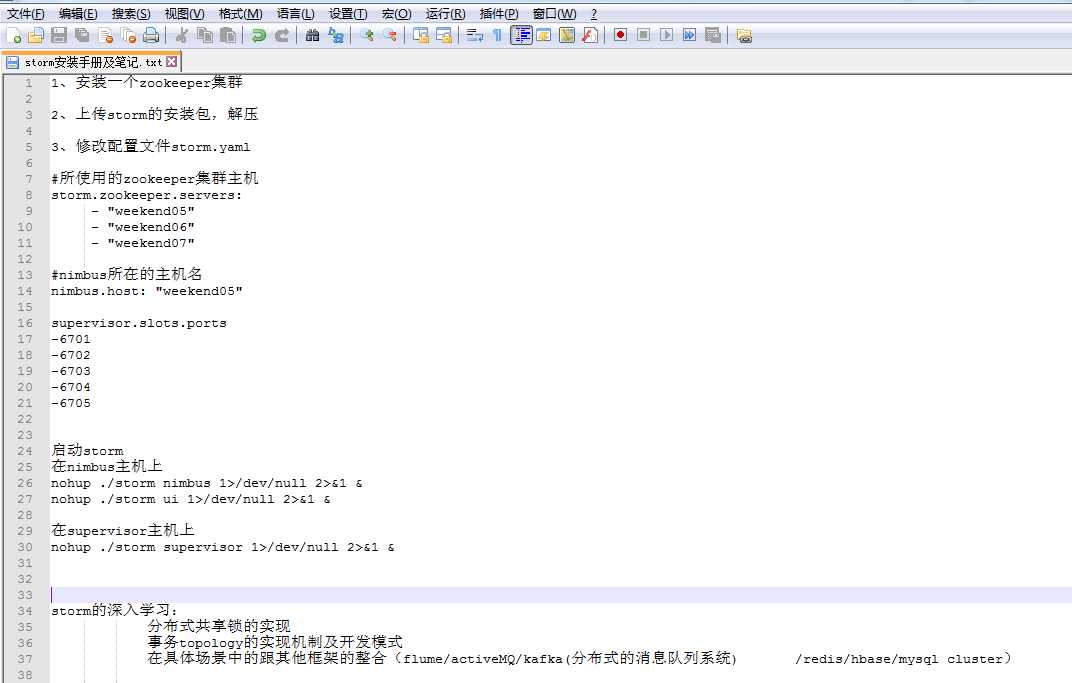
1、安装一个zookeeper集群
2、上传storm的安装包,解压
3、修改配置文件storm.yaml
#所使用的zookeeper集群主机
storm.zookeeper.servers:
- "weekend05"
- "weekend06"
- "weekend07"
#nimbus所在的主机名
nimbus.host: "weekend05"
supervisor.slots.ports
-6701
-6702
-6703
-6704
-6705
启动storm
在nimbus主机上
nohup ./storm nimbus 1>/dev/null 2>&1 &
nohup ./storm ui 1>/dev/null 2>&1 &
在supervisor主机上
nohup ./storm supervisor 1>/dev/null 2>&1 &
storm的深入学习:
分布式共享锁的实现
事务topology的实现机制及开发模式
在具体场景中的跟其他框架的整合(flume/activeMQ/kafka(分布式的消息队列系统) /redis/hbase/mysql cluster)
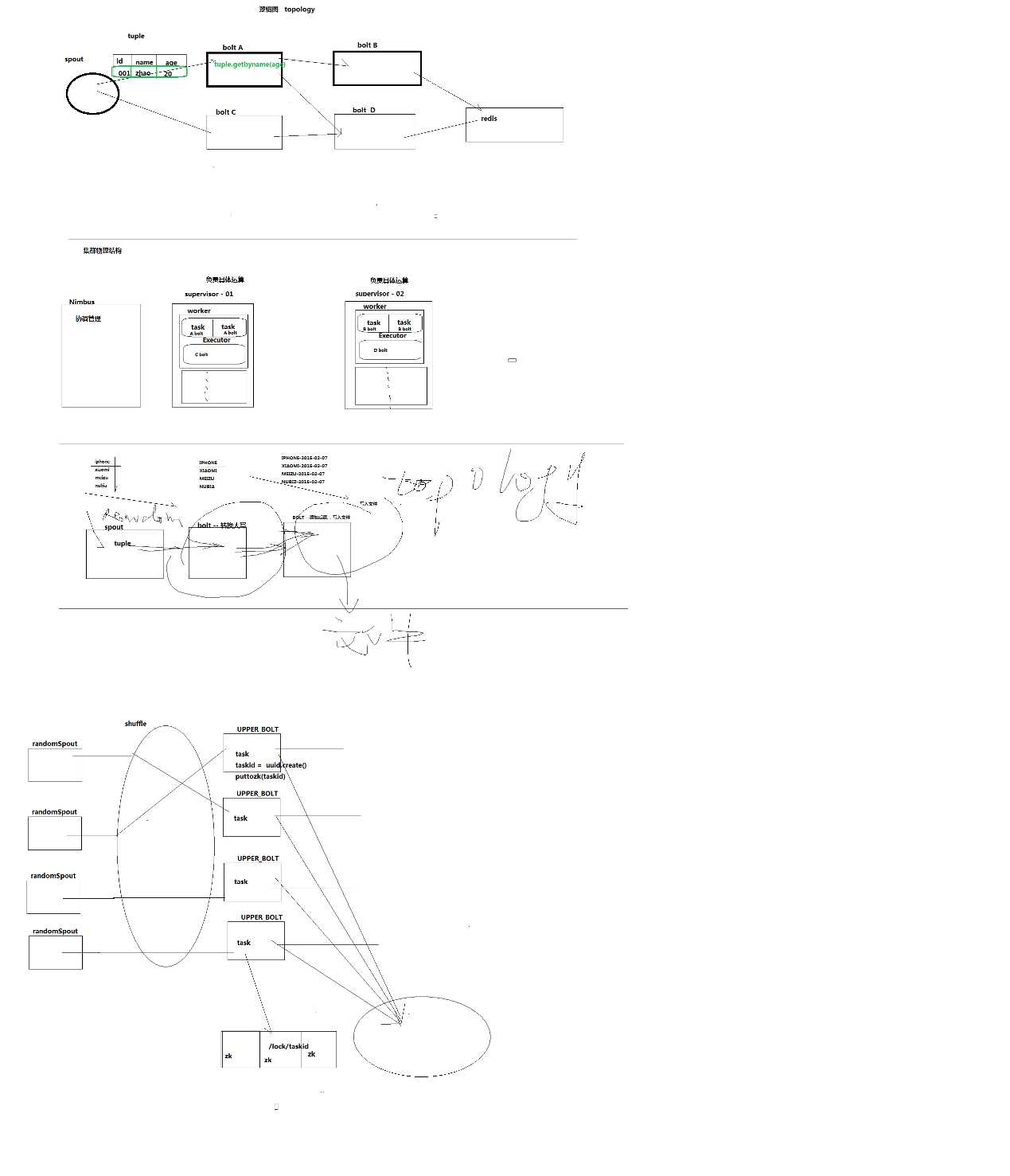
手机实时位置查询。
新建storm工程
这里,推荐用新建Maven工程,多好!
当然,为了照顾初学者,手工添加导入依赖包。
同时,各位来观看我本博客的博友们,其实,在生产是一定要是Maven的啊!何止能出书的人。
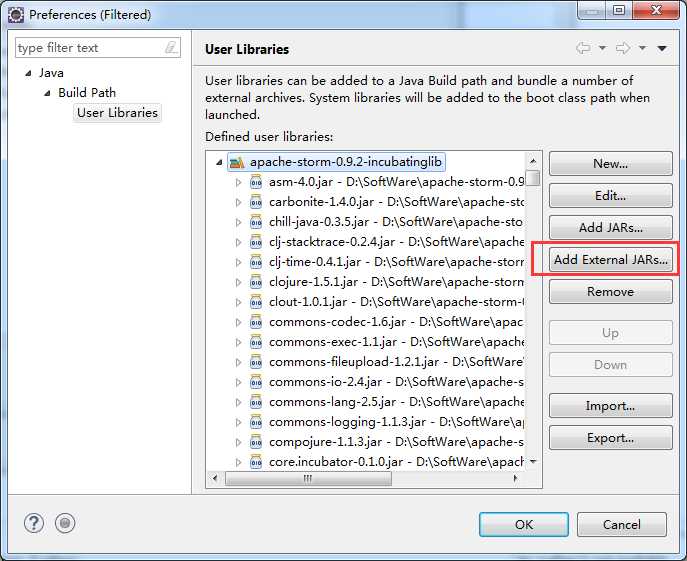
weekend110-storm -> Build Path -> Configure Build Path
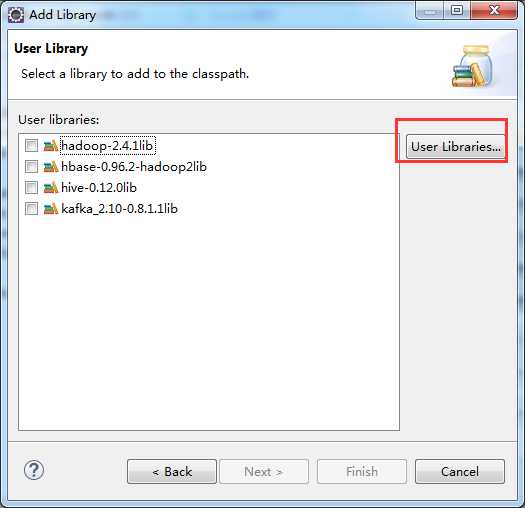
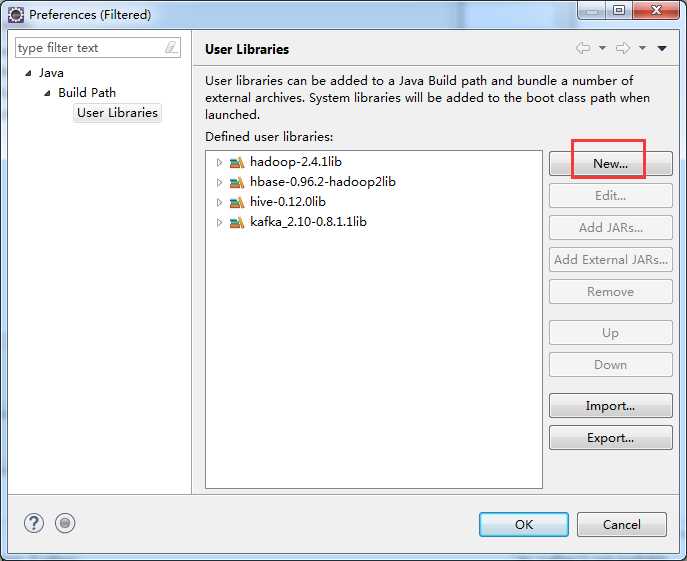
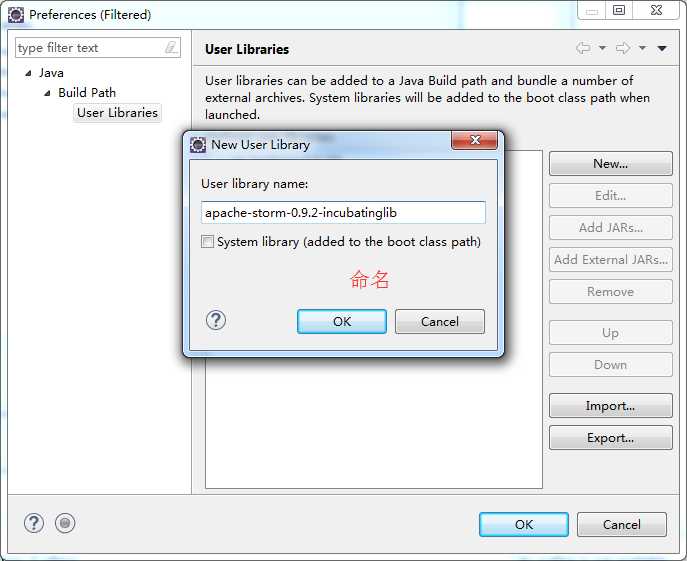
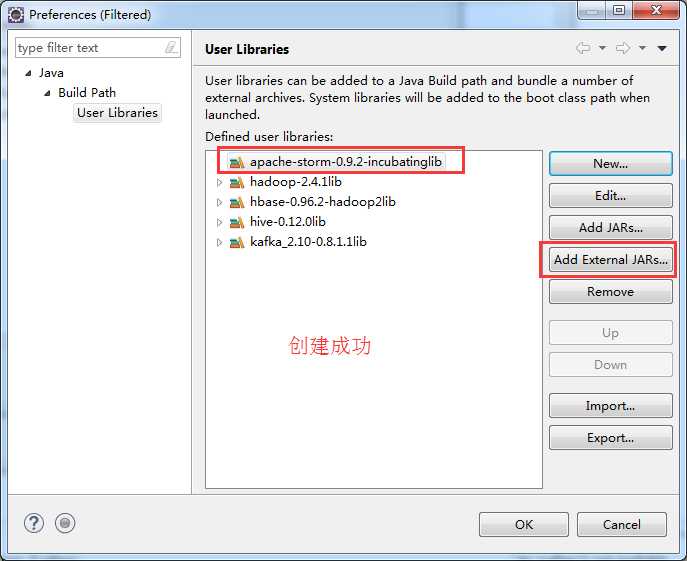

D:\SoftWare\apache-storm-0.9.2-incubating\lib
D:\SoftWare\apache-storm-0.9.2-incubating\external\storm-kafka
这个很重要,一般storm和kafka,做整合,是必须要借助用到这个jar包的。
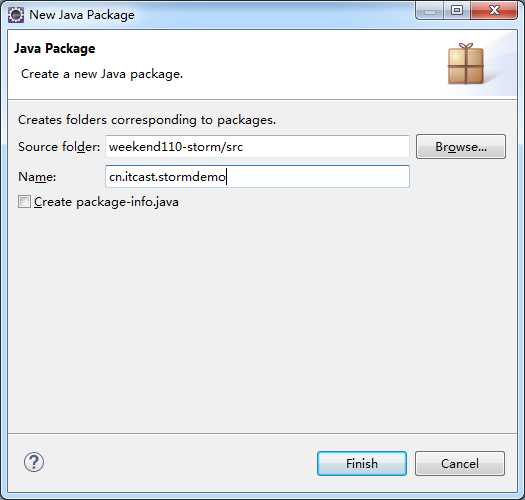
新建包cn.itcast.stormdemo
新建类RandomWordSpout.java
新建类UpperBolt.java
新建类 SuffixBolt.java
新建类 TopoMain.java
编写代码
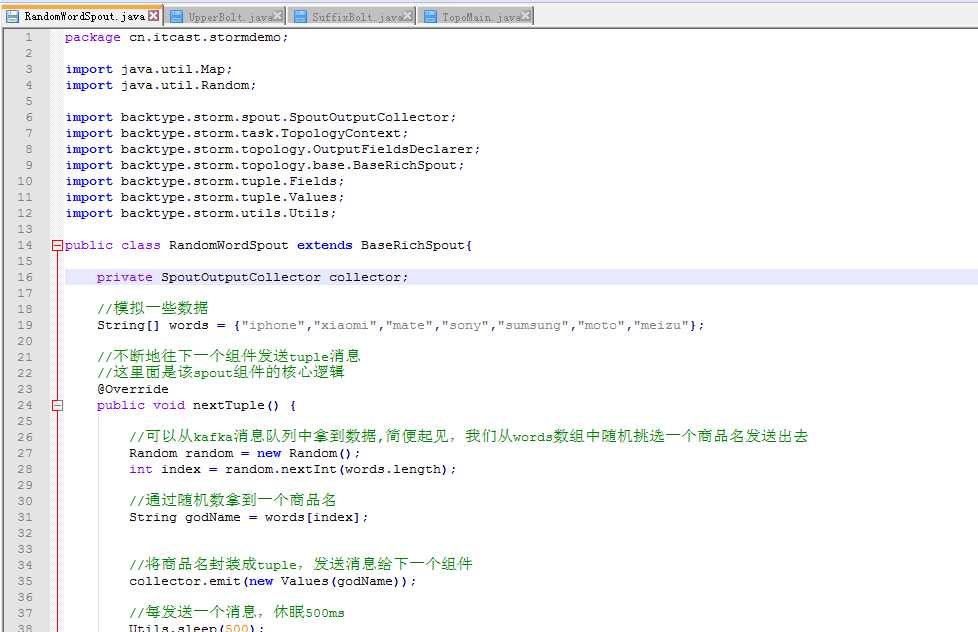
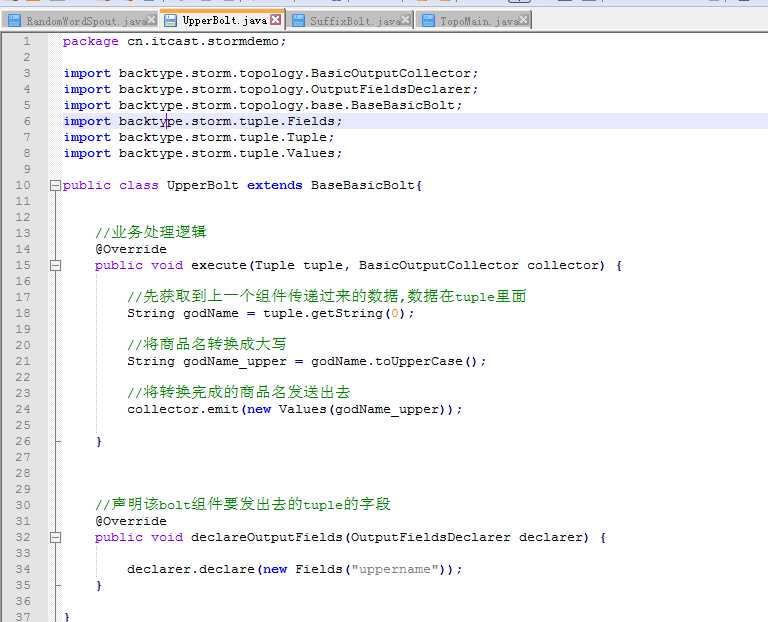
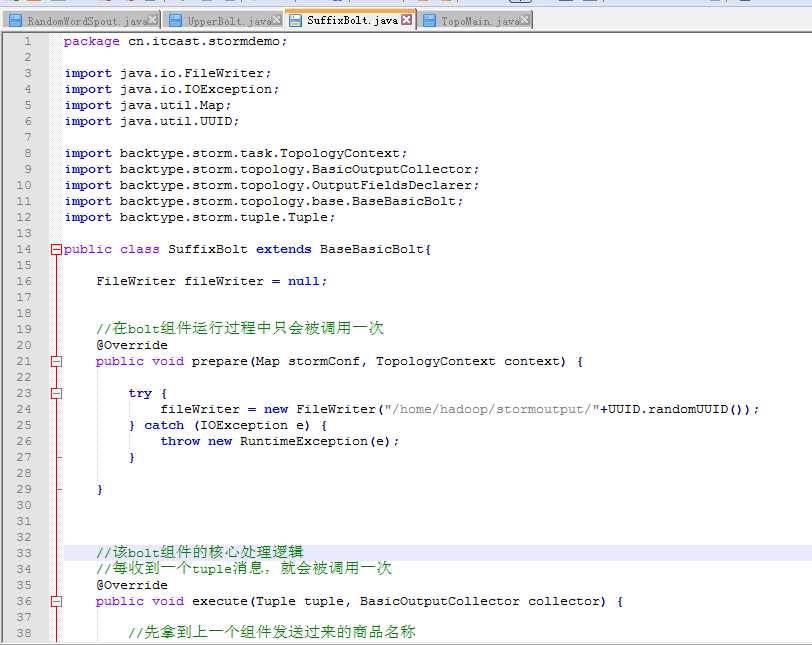
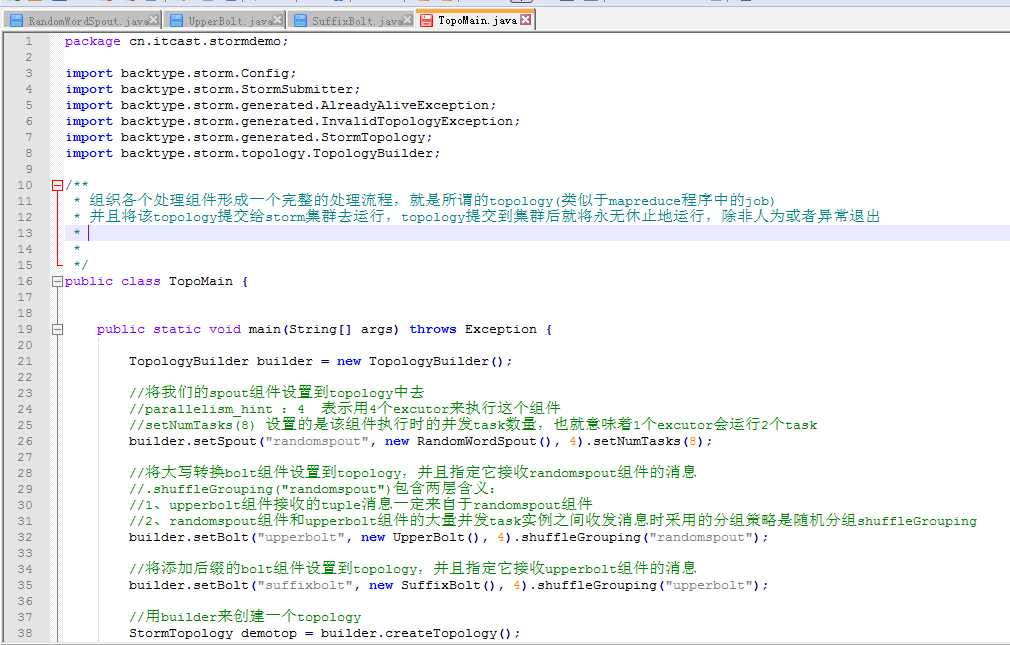
RandomWordSpout.java
package cn.itcast.stormdemo;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class RandomWordSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
//模拟一些数据
String[] words = {"iphone","xiaomi","mate","sony","sumsung","moto","meizu"};
//不断地往下一个组件发送tuple消息
//这里面是该spout组件的核心逻辑
@Override
public void nextTuple() {
//可以从kafka消息队列中拿到数据,简便起见,我们从words数组中随机挑选一个商品名发送出去
Random random = new Random();
int index = random.nextInt(words.length);
//通过随机数拿到一个商品名
String godName = words[index];
//将商品名封装成tuple,发送消息给下一个组件
collector.emit(new Values(godName));
//每发送一个消息,休眠500ms
Utils.sleep(500);
}
//初始化方法,在spout组件实例化时调用一次
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
//声明本spout组件发送出去的tuple中的数据的字段名
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("orignname"));
}
}
UpperBolt.java
package cn.itcast.stormdemo;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class UpperBolt extends BaseBasicBolt{
//业务处理逻辑
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先获取到上一个组件传递过来的数据,数据在tuple里面
String godName = tuple.getString(0);
//将商品名转换成大写
String godName_upper = godName.toUpperCase();
//将转换完成的商品名发送出去
collector.emit(new Values(godName_upper));
}
//声明该bolt组件要发出去的tuple的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("uppername"));
}
}
SuffixBolt.java
package cn.itcast.stormdemo;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class SuffixBolt extends BaseBasicBolt{
FileWriter fileWriter = null;
//在bolt组件运行过程中只会被调用一次
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
fileWriter = new FileWriter("/home/hadoop/stormoutput/"+UUID.randomUUID());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//该bolt组件的核心处理逻辑
//每收到一个tuple消息,就会被调用一次
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先拿到上一个组件发送过来的商品名称
String upper_name = tuple.getString(0);
String suffix_name = upper_name + "_itisok";
//为上一个组件发送过来的商品名称添加后缀
try {
fileWriter.write(suffix_name);
fileWriter.write("\n");
fileWriter.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//本bolt已经不需要发送tuple消息到下一个组件,所以不需要再声明tuple的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}
TopoMain.java
package cn.itcast.stormdemo;
import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
/**
* 组织各个处理组件形成一个完整的处理流程,就是所谓的topology(类似于mapreduce程序中的job)
* 并且将该topology提交给storm集群去运行,topology提交到集群后就将永无休止地运行,除非人为或者异常退出
*
*
*/
public class TopoMain {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
//将我们的spout组件设置到topology中去
//parallelism_hint :4 表示用4个excutor来执行这个组件
//setNumTasks(8) 设置的是该组件执行时的并发task数量,也就意味着1个excutor会运行2个task
builder.setSpout("randomspout", new RandomWordSpout(), 4).setNumTasks(8);
//将大写转换bolt组件设置到topology,并且指定它接收randomspout组件的消息
//.shuffleGrouping("randomspout")包含两层含义:
//1、upperbolt组件接收的tuple消息一定来自于randomspout组件
//2、randomspout组件和upperbolt组件的大量并发task实例之间收发消息时采用的分组策略是随机分组shuffleGrouping
builder.setBolt("upperbolt", new UpperBolt(), 4).shuffleGrouping("randomspout");
//将添加后缀的bolt组件设置到topology,并且指定它接收upperbolt组件的消息
builder.setBolt("suffixbolt", new SuffixBolt(), 4).shuffleGrouping("upperbolt");
//用builder来创建一个topology
StormTopology demotop = builder.createTopology();
//配置一些topology在集群中运行时的参数
Config conf = new Config();
//这里设置的是整个demotop所占用的槽位数,也就是worker的数量
conf.setNumWorkers(4);
conf.setDebug(true);
conf.setNumAckers(0);
//将这个topology提交给storm集群运行
StormSubmitter.submitTopology("demotopo", conf, demotop);
}
}
补充:
http://www.cnblogs.com/vincent-vg/p/5850852.html
以上是关于1 storm基本概念 + storm编程规范及demo编写的主要内容,如果未能解决你的问题,请参考以下文章