storm基本概念
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm基本概念相关的知识,希望对你有一定的参考价值。
参考技术A 流式计算中,各个中间件产品对计算过程中的角色的抽象都不尽相同,实现方式也是千差万别。本文针对storm中间件在进行流式计算中的几个概念做个概括总结。storm分布式计算结构称为topology(拓扑)由stream,spout,bolt组成。
spout代表一个storm拓扑中的数据入口,连接到数据源,将数据转化为一个个tuple,并发射tuple
stream是由无限制个tuple组成的序列。tuple为storm的核心数据结构,是包含了一个或多个键值对的列表。
bolt可以理解为计算程序中的运算或者函数,bolt的上游是输入流,经过bolt实施运算后,可输出一个或者多个输出流。
bolt可以订阅多个由spout或者其他bolt发射的数据流,用以构建复杂的数据流转换网络。
上述即为storm最基本的组成元素,无论storm如何运行,都是以stream,spout,bolt做为最基本的运行单元。而这三者则是共同构成了一个storm拓扑topology。
首先需要明确一个概念,bolt,spout实例,都属于任务,spout产生数据流,并发射,bolt消费数据流,进行计算,并进行落地或再发射,他们的存在以及运行过程都需要消耗资源,而storm集群是一个提供了资源的集群,我们要做的就是将spout/boult实例合理分配到storm集群提供的计算资源上,这样就可以让spout/bolt得以执行。
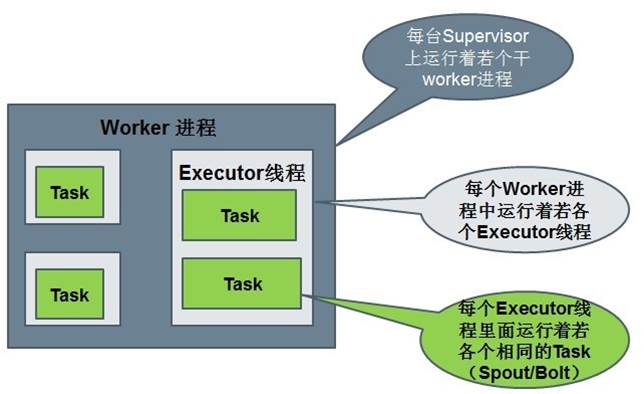
worker为JVM进程,一个topology会分配到一个或者多个worker上运行。
executor是worker内的java线程,是具体执行bolt/spout实例用的。下篇文章在介绍如何提供storm并行计算能力时会介绍worker以及executor的配置。
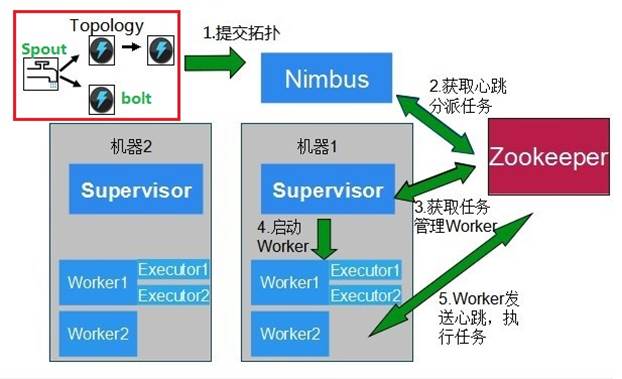
在storm中,worker是由supervisor进程创建,并进行监控的。storm集群遵循主从模式,主为nimbus,从为supervisor,storm集群由一个主节点(确实有单点问题),和多个工作节点(supervisor)组成,并使用zookeeper来协调集群中的状态信息,比如任务分配情况,worker状态,supervisor的拓扑度量。
通过配置可指定supervisor上可运行多少worker。一个worker代表一个slot。
nimbus守护进程的主要职责是管理,协调和监控在集群上运行的topology.包括topology的发布,任务指派,事件处理失败时重新指派任务。
supervisor守护进程等待nimbus分配任务后生成并监控workers执行任务。supervosior和worker都是运行在不同的JVM进程上。
了解了集群模式下,storm大致的分布概念,下面结合笔者做的一个实例,了解一下如何发布计算资源到storm集群上。
笔者定义了一个spout,两个bolt 运算过程如下:
其中streamMaking是一个不断生成随机数(5~30)的spout实例,Step1Bolt会过滤掉15以下的随机数(过滤),15以上的随机数会乘以16(计算),再将结果向后发射。Step2Bolt订阅Step1Bolt发射的数据,接收数据后,打印输出。流程结束。
笔者在定义spout/bolt实例时,配置了spout,bolt的并行执行数。其中
streamMaking:4 Step1Bolt:2 Step2Bolt 1
这样,发布成功后,storm会根据我的配置,分配足够的计算资源给予spout/bolt进行执行。
发布:
发布时,spout和bolt都是在一起以jar的形式发布到nimbus上的,分配后,内部定义的spout和bolt将以组件的形式被nimbus分配至worker进程中执行。
其中worker都是由supervisor创建的,创建出来的worker进程与supervisor是分开的不同进程。一个supervisor可创建多少worker可通过修改storm安装目录下的storm.yaml进行配置。
task是执行的最小单元。spout/bolt实例在定义中指定了,要起多少task,以及多少executor。也即一个topology发布之前已经定义了task总量,和需要多少资源来执行我的task总量。nimbus将根据已有的计算资源进行分配。
下图中: nimbus左边代表着计算任务量,和所需计算配置
nimbus右边代表着计算资源
nimbus将根据计算资源信息,合理的分发计算任务量。
发布成功后,通过storm自带的UI功能,可以查看你发布的topology运行以及其中每个组件的分布执行情况。
监控图像中清晰的显示了,目前部署的topology,以及topology中每个组件所分配的计算资源所在host,以及每个组件发射了多少tuple,接收了多少tuple,以及有多少个executor在并行执行。
本文讲述了storm内的基本元素以及基本概念,后续将讲述storm的重点配置信息,以及如何提高并发计算能力,窗口概念等高级特性,后续会进行源码分析,以及与其他实时计算中间件的比较。
Storm 简介及组件的基本概念
如果需要实现一个实时计算系统
全量数据处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近这两年也不会有s4, Storm ,puma这些实时计算系统如雨后春笋般冒出来啦。先抛开s4, Storm ,puma这些系统不谈,我们首先来看一下,如果让我们自己设计一个实时计算系统,我们要解决哪些问题。
● 低延迟。都说了是实时计算系统了,延迟是一定要低的。
● 高性能。性能不高就是浪费机器,浪费机器就是浪费钱。
● 分布式。系统都是为应用场景而生的,如果你的应用场景、你的数据和计算单机就能搞定,那么不用考虑这些复杂的问题了。我们所说的是单机搞不定的情况。
● 可扩展。伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以希望这个系统是可扩展的。
● 容错。这是分布式系统中通用问题。一个节点挂了不能影响我的应用。
好,如果仅仅需要解决这5个问题,可能会有无数种方案,而且各有千秋,随便举一种方案,使用消息队列+分布在各个机器上的工作进程就可以了。
1. 容易在上面开发应用程序。你设计的系统需要应用程序开发人员考虑各个处理组件的分布、消息的传递吗?如果是,那有点麻烦啊,开发人员可能会用不好,也不会想去用。
2. 消息不丢失。用户发布的一个宝贝消息不能在实时处理的时候给丢了,对吧?更严格一点,如果是一个精确数据统计的应用,那么它处理的消息要不多不少才行。这个要求有点高。
3. 消息严格有序。有些消息之间是有强相关性的,比如同一个宝贝的更新和删除操作消息,如果处理时搞乱顺序完全是不一样的效果了。
不知道大家对这些问题是否都有了自己的答案,下面让我们带着这些问题,一起来看一看 Storm 的吧。
Storm 是什么
如果只用一句话来描述 Storm 的话,可能会是这样:分布式实时计算系统。按照 Storm 作者的说法, Storm 对于实时计算的意义类似于hadoop对于批处理的意义。我们都知道,根据google mapreduce来实现的hadoop为我们提供了map、reduce原语,使我们的批处理程序变得非常地简单和优美。同样, Storm 也为实时计算提供了一些简单优美的原语。我们会在第三节中详细介绍。
我们来看一下 Storm 的适用场景。
1.流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到数据库中。
2.连续计算:Storm可以进行连续查询并把结果即时反馈给客户,比如将热门话题发送到客户端,网站指标等。
3.分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
Storm 中的一些概念
首先我们通过一个 Storm 和 hadoop 的对比来了解 Storm 中的基本概念。

接下来我们再来具体看一下这些概念。
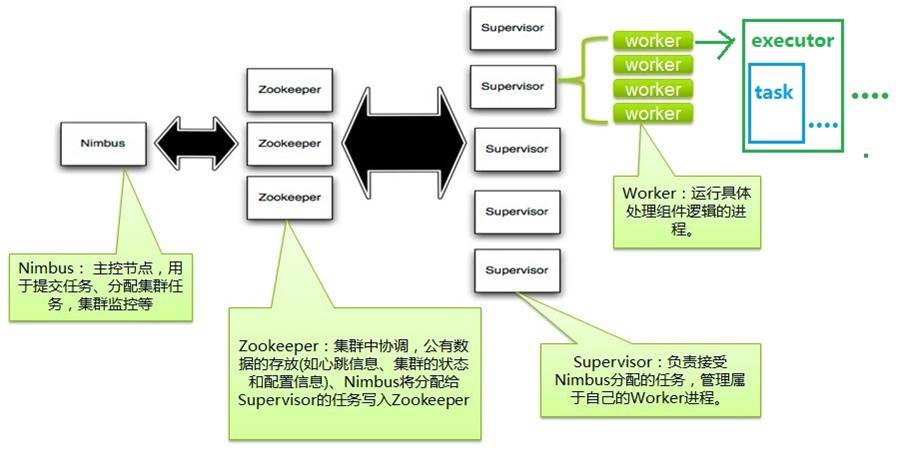
1. Nimbus:负责资源分配和任务调度。
2. Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
3. Worker:运行具体处理组件逻辑的进程。
4. Task:worker中每一个 Spout /bolt的线程称为一个task. 在 Storm 0.8之后,task不再与物理线程对应,同一个 Spout /bolt的task可能会共享一个物理线程,该线程称为executor。
下面这个图描述了以上几个角色之间的关系:
5,Topology: Storm 中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。
6, Spout:在一个topology中产生源数据流的组件。通常情况下 Spout 会从外部数据源中读取数据,然后转换为topology内部的源数据。 Spout 是一个主动的角色,其接口中有个nextTuple()函数, Storm 框架会不停地调用此函数,用户只要在其中生成源数据即可。
7,Bolt:在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
8, Tuple:一次消息传递的基本单元。
9,Stream:源源不断传递的tuple就组成了stream。
10,Stream Grouping:即消息的partition方法。流分组策略告诉topology如何在两个组件之间发送tuple。 Storm 中提供若干种实用的grouping方式,包括shuffle, fields hash, all, global, none, direct和localOrShuffle等。
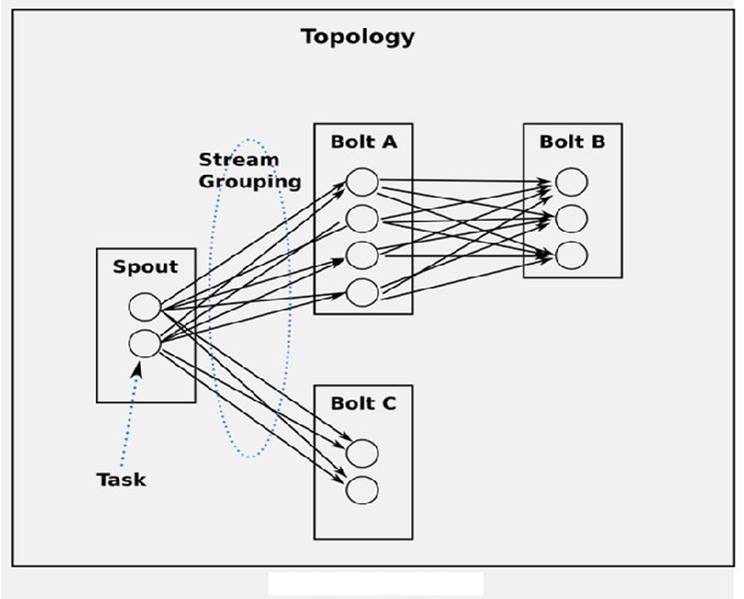
运行中的Topology :
•运行中的Topology主要由以下三个组件组成的:
•Worker processes(进程)
•Executors (threads)(线程)
•Tasks
Stream的概念
•Stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。
•通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Stream中,bolt可以接收任意多个输入stream, 作一些处理, 有些bolt可能还会发射一些新的stream
Stream Grouping
定义topology的很重要的一部分就是定义数据流数据流应该发送到那些bolt中。数据流分组就是将数据流进行分组,按需要进入不同的bolt中。可以使用Storm提供的分组规则,也可以实现backtype.storm.grouping.CustomStreamGrouping自定义分组规则。Storm定义了8种内置的数据流分组方法:
1. Shuffle grouping(随机分组):随机分发tuple给bolt的各个task,每个bolt实例接收到相同数量的tuple;
2. Fields grouping(按字段分组):根据指定字段的值进行分组。比如,一个数据流按照”user-id”分组,所有具有相同”user-id”的tuple将被路由到同一bolt的task中,不同”user-id”可能路由到不同bolt的task中;
3. Partial Key grouping(部分key分组):数据流根据field进行分组,类似于按字段分组,但是将在两个下游bolt之间进行均衡负载,当资源发生倾斜的时候能够更有效率的使用资源。
4. All grouping(全复制分组):将所有tuple复制后分发给所有bolt的task。小心使用。
5. Global grouping(全局分组):将所有的tuple路由到唯一一个task上。Storm按照最小的task ID来选取接收数据的task;(注意,当时用全局分组是,设置bolt的task并发是没有意义的,因为所有tuple都转发到一个task上。同时需要注意的是,所有tuple转发到一个jvm实例上,可能会引起storm集群某个jvm或服务器出现性能瓶颈或崩溃)
6. None grouping(不分组):这种分组方式指明不需要关心分组方式。实际上,不分组功能与随机分组相同。预留功能。
7. Direct grouping(指向型分组):数据源会调用emitDirect来判断一个tuple应该由哪个storm组件接收,只能在声明了指向型的数据流上使用。
8. Local or shuffle grouping(本地或随机分组):当同一个worker进程中有目标bolt,将把数据发送到这些bolt中。否则,功能将与随机分组相同。该方法取决与topology的并发度,本地或随机分组可以减少网络传输,降低IO,提高topology性能。
以上是关于storm基本概念的主要内容,如果未能解决你的问题,请参考以下文章