:DataFrame入门
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:DataFrame入门相关的知识,希望对你有一定的参考价值。
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家来学习今天的内容!
往期内容:
- Spark基础入门-第一章:Spark 框架概述
- Spark基础入门-第二章:Spark环境搭建-Local
- Spark基础入门-第三章:Spark环境搭建-StandAlone
- Spark基础入门-第四章:Spark环境搭建-StandAlone-HA
- Spark基础入门-第五章:环境搭建-Spark on YARN
- Spark基础入门-第六章:PySpark库
- Spark基础入门-第七章:本机开发环境搭建
- Spark基础入门-第八章:分布式代码执行分析
- Spark Core-第一章: RDD详解
- Spark Core-第三章:RDD的持久化
- Spark Core-第四章:Spark案例练习
- Spark Core-第五章:共享变量
- Spark Core-第六章:Spark 内核调度
- SparkSQL-第一章:SparkSQL快速入门
- SparkSQL-第二章:SparkSQL 概述
一、DataFrame的组成
DataFrame是一个二维表结构, 那么表格结构就有无法绕开的三个点:
- 行
- 列
- 表结构描述
比如,在mysql中的一张表:
- 由许多行组成
- 数据也被分成多个列
- 表也有表结构信息(列、列名、列类型、列约束等 )
基于这个前提, DataFrame的组成如下:
在结构层面:
- - StructType对象描述整个DataFrame的表结构
- - StructField对象描述一个列的信息
在数据层面
- - Row对象记录一行数据
- - Column对象记录一列数据并包含列的信息
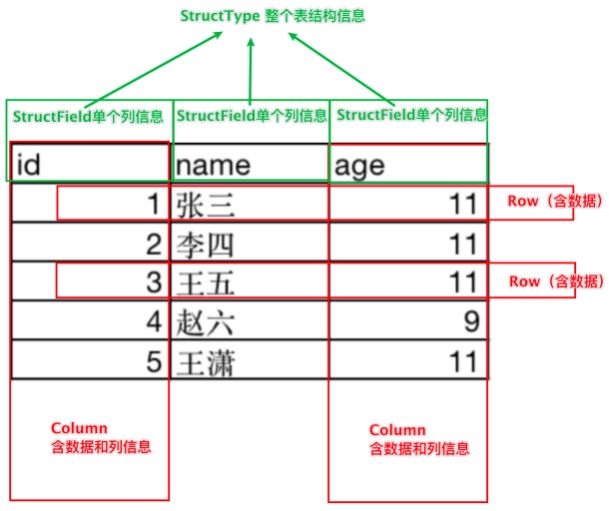
如图, 在表结构层面, DataFrame的表结构由:StructType描述,如下图

一个StructField记录:列名、列类型、列是否运行为空 多个StructField组成一个StructType对象。
一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型 、每个列是否为空
同时,一行数据描述为Row对象,如Row(1, 张三, 11)
一列数据描述为Column对象, Column对象包含一列数据和列的信息
Row、Column、StructType、StructField的编程我们在后面编码阶段会接触
二、DataFrame的代码构建
DataFrame的代码构建 - 基于RDD方式1
DataFrame对象可以从RDD转换而来, 都是分布式数据集 其实就是转换一下内部存储的结构, 转换为二维表结构。
将RDD转换为DataFrame方式1: 调用spark

通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame,这里只传入列名称,类型从RDD中进行推断, 是否允许为空默认为允许(True)。

DataFrame的代码构建 - 基于RDD方式2
将RDD转换为DataFrame方式2:
通过StructType对象来定义DataFrame的“表结构”转换 RDD


DataFrame的代码构建 - 基于RDD方式3
将Naa转换为ae\\e」Jem?方式c:使用Naa的\\oa」方法转换Naa


DataFrame的代码构建 - 基于Pandas的DataFrame
将denpes的ae\\e」Jem?对象,转变为分布式的SdeJ入So1 ae\\e」Jem?对象


DataFrame的代码构建 - 读取外部数据
通过SparkSQL的统一API进行数据读取构建DataFrame统一API示例代码:

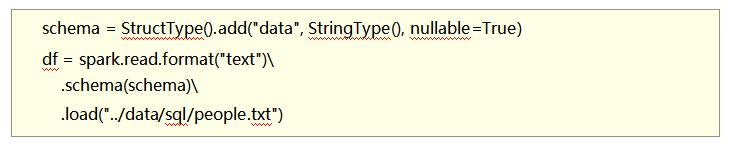
读取text数据源
使用format(“text”)读取文本数据
读取到的DataFrame只会有一个列, 列名默认称之为: value
示例代码:
读取json数据源
使用format(“json”)读取json数据
示例代码:

读取csv数据源
使用format(“csv”)读取csv数据
示例代码:

读取deJbu?\\数据源
使用oJme\\)“deJbu?\\”(读取deJbu?\\数据
示例代码:

deJbu?\\: 是SdeJ入中常用的一种列式存储文件格式
和Hiv?中的OND差不多, 他俩都是列存储格式
deJbu?\\对比普通的文本文件的区别:
- deJbu?\\ 内置sDV?me )列名\\ 列类型\\ 是否为空(
- 存储是以列作为存储格式
- 存储是序列化存储在文件中的)有压缩属性体积小(
三、DataFrame的入门操作
DataFrame支持两种风格进行编程, 分别是:
- DSL风格
- SQL风格
DSL语法风格
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如: df.where().limit()
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如: spark.sql(“SELECT * FROM xxx)
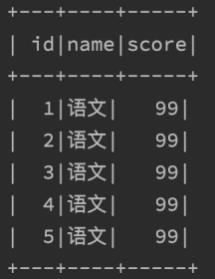
DSL - show 方法
功能:展示DataFrame中的数据, 默认展示20条
语法:

如图,某个df.show后的展示结果
DSL - printSchema方法
功能: 打印输出df的schema信息
语法:


DSL - select
功能:选择DataFrame中的指定列(通过传入参数进行指定)
语法:
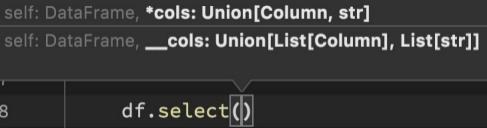
可传递:
• 可变参数的cols对象, cols对象可以是Column对象来指定列或者字符串
列名来指定列
• List[Column]对象或者List[str]对象, 用来选择多个列

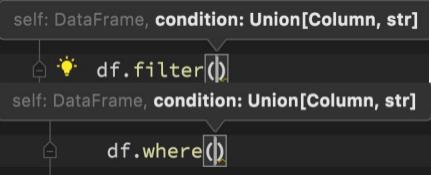
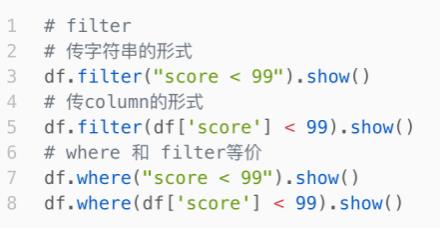
DSL - filter和where
功能:过滤DataFrame内的数据,返回一个过滤后的DataFrame
语法:
df.filter()
df.where()
where和filter功能上是等价的
DSL - groupBy 分组
功能:按照指定的列进行数据的分组, 返回值是GroupedData对象
语法:
df.groupBy()
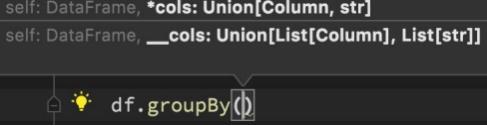
传入参数和select一样, 支持多种形式,不管怎么传意思就是告诉spark按照哪个列分组

GroupedData对象
GroupedData对象是一个特殊的DataFrame数据集
其类全名: <class 'pyspark.sql.group.GroupedData'>
这个对象是经过groupBy后得到的返回值, 内部记录了 以分组形式存储的数据
GroupedData对象其实也有很多API, 比如前面的count方法就是这个对象的内置方法
除此之外,像: min、 max、avg、 sum、等等许多方法都存在,后续会再次使用它
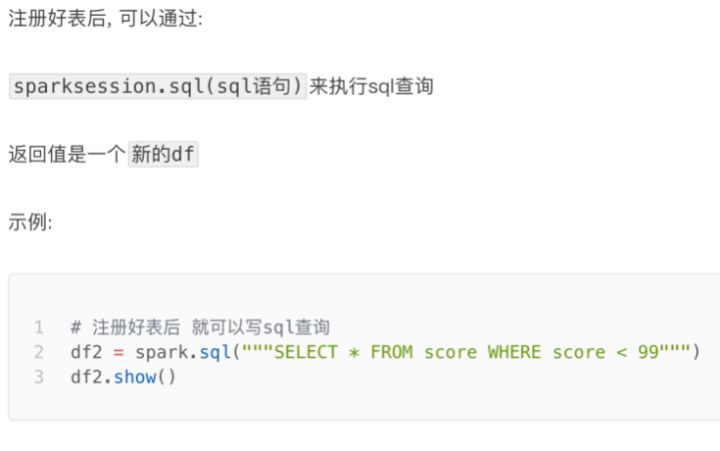
SQL风格语法 - 注册DataFrame成为表
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中
使用spark.sql() 来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:


SQL风格语法 - 使用SQL查询
pyspark.sql.functions 包
PySpark提供了一个包: pyspark.sql.functions
这个包里面提供了 一系列的计算函数供SparkSQL使用
如何用呢?
导包
from pyspark.sql import functions as F
然后就可以用F对象调用函数计算了。
这些功能函数, 返回值多数都是Column对象.

四、词频统计案例练习
我们来完成一个单词计数需求,使用DSL和SQL两种风格来实现。
在实现的过程中,会出现新的API,边写边学习新API, 代码中红色部分即新API

五、电影评分数据分析案例



六、SparkSQL Shuffle 分区数目

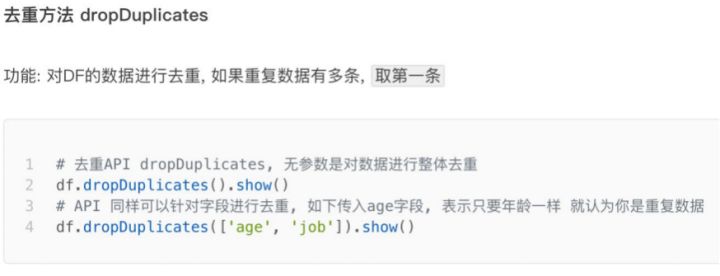
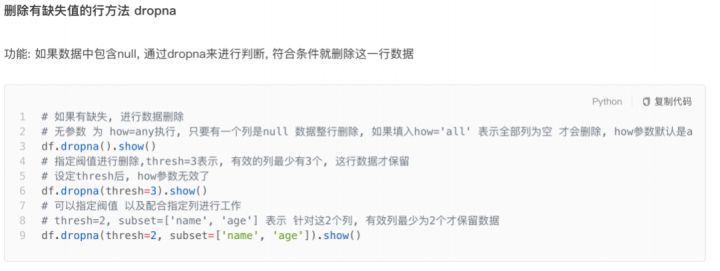
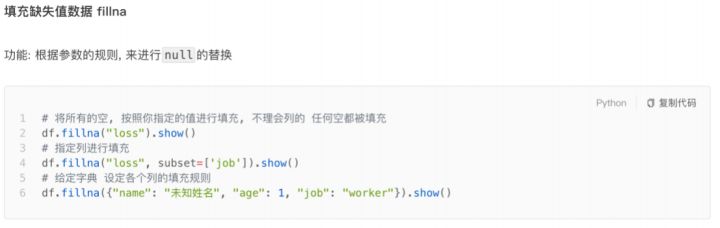
七、SparkSQL 数据清洗API

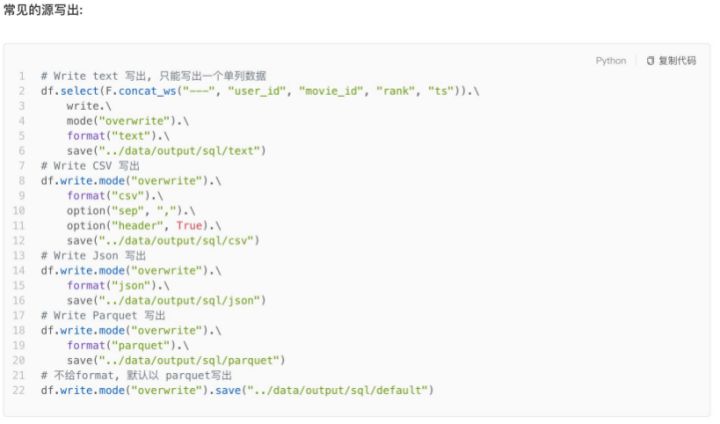
八、DataFrame数据写出

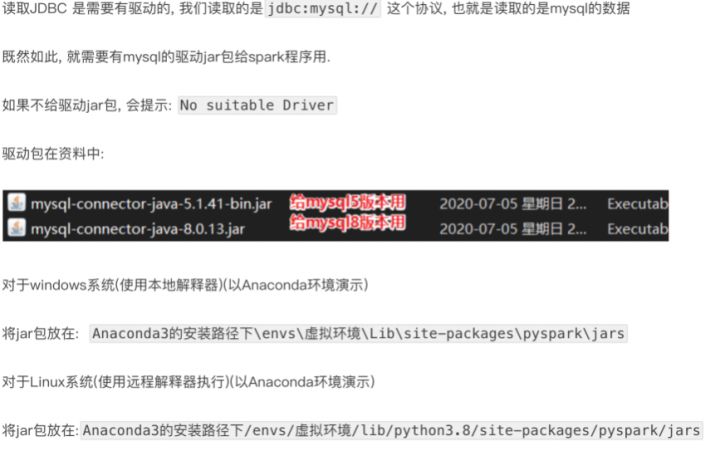
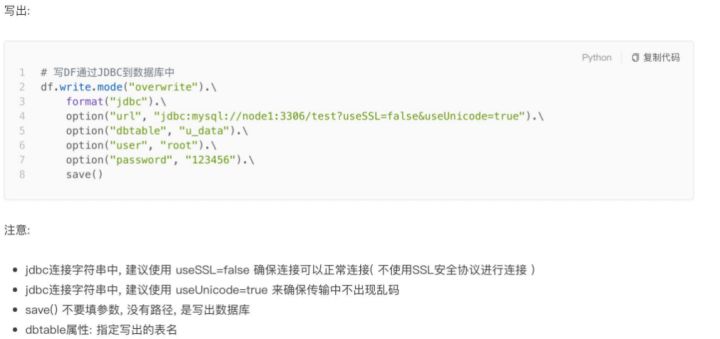
九、DataFrame 通过JDBC读写数据库(MySQL示例)

以上是关于:DataFrame入门的主要内容,如果未能解决你的问题,请参考以下文章