湖仓一体电商项目(十五):实时统计商品及一级种类二级种类访问排行业务需求和分层设计及流程图
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了湖仓一体电商项目(十五):实时统计商品及一级种类二级种类访问排行业务需求和分层设计及流程图相关的知识,希望对你有一定的参考价值。

文章目录
实时统计商品及一级种类、二级种类访问排行业务需求和分层设计及流程图
实时统计商品及一级种类、二级种类访问排行业务需求和分层设计及流程图
一、业务需求
用户登录系统后会浏览商品,浏览日志通过日志采集接口采集到Kafka “KAFKA-USER-LOG-DATA”topic中,每个用户浏览商品的日志信息中都有浏览的商品编号以及当前商品所属的二级分类信息,我们需要根据用户在网站上浏览的日志信息实时统计出商品浏览排行、商品一级种类、二级种类访问排行,并在大屏展示,展示效果如下:

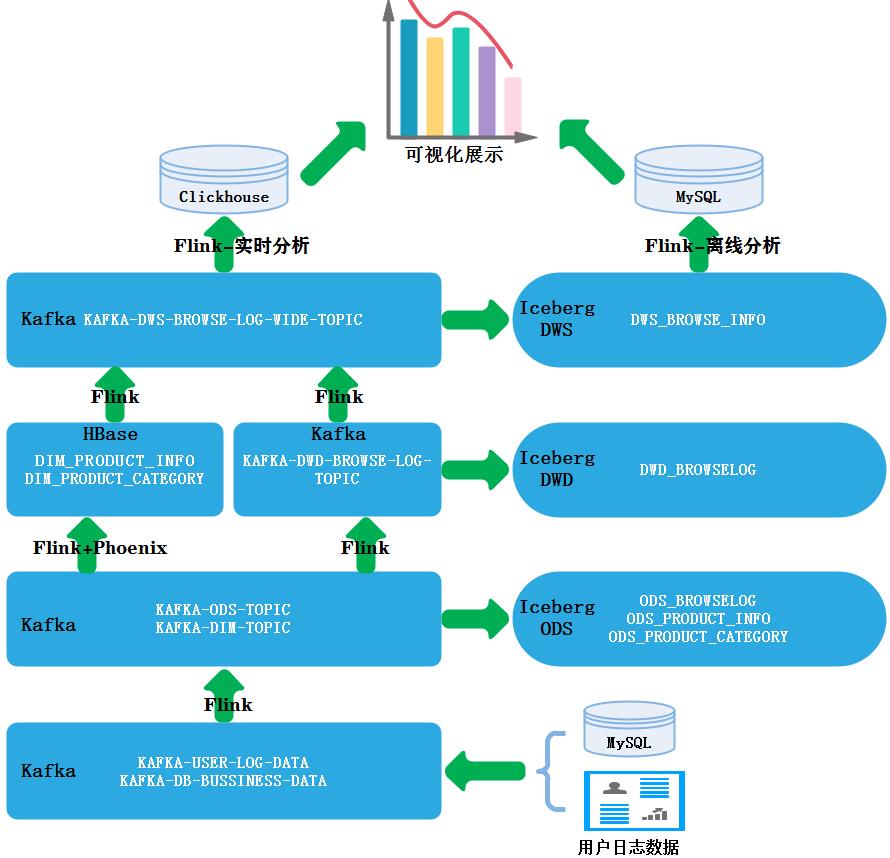
二、业务分层设计及流程图
本业务涉及到的数据有两类,一类是来自于mysql业务库商品分类表“pc_product_category”、商品基本信息表“pc_product”,我们会将以上业务表数据采集到大数据平台中构建数仓分层,同样,我们采用数据湖技术Iceberg构建湖仓一体结构进行数据仓库分层,在数仓中以上两张表是维度数据。在设计湖仓分层时,我们将维度数据存储在HBase中,将事实数据存储在Iceberg数仓分层中,在第一个业务中我们已经写好了通用的处理维度数据代码“DimDataToHBase.scala”,只需要在MySQL配置表“lakehousedb.dim_tbl_config_info”表中配置好对应的维度表即可,这样通过maxwell增量或者全量将MySQL中维度数据分流导入到Kafka 存储维度的topic “KAFKA-DIM-TOPIC”中,进而通过处理维度通用代码将维度数据写入到HBase中。
另一类数据是来自于用户浏览商品日志数据,此类数据在1.5章节中已经通过日志采集接口将数据采集到Kafka topic “KAFKA-USER-LOG-DATA”中,针对此topic中数据我们需要通过Flink代码进行处理,Flink代码会将所有业务库中的数据保留一份完整数据到Iceberg ODS层中,针对维度数据会将数据进行过滤存储在Kafka 中,方便后续维度数据处理,另外为了使代码重启后消费数据位置信息得到保证,这里我们将所有事实数据也存储在Kafka中,后续各层也是按照此逻辑执行。
本实时业务湖仓分层设计如下图所示:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于湖仓一体电商项目(十五):实时统计商品及一级种类二级种类访问排行业务需求和分层设计及流程图的主要内容,如果未能解决你的问题,请参考以下文章